Official statement
Other statements from this video 43 ▾
- □ Is Google Really Measuring Page Weight the Way You Think It Does?
- □ Has mobile page weight tripled in 10 years? Why should SEO professionals care about this trend?
- □ Is your structured data bloating your pages too much to be worth the SEO investment?
- □ Is your mobile site missing critical content that exists on desktop?
- □ Is your desktop content disappearing from Google rankings because it's missing on mobile?
- □ Does page speed really impact conversions according to Google?
- □ Is Google really processing 40 billion spam URLs every single day?
- □ Does network compression really improve your site's crawl budget?
- □ Is lazy loading really essential to optimize your initial page weight and boost Core Web Vitals?
- □ Does Googlebot really stop crawling after 15 MB per URL?
- □ Has mobile page weight really tripled in just one decade?
- □ Does page weight really affect user experience and SEO performance?
- □ Does structured data really bloat your HTML and hurt page performance?
- □ Is mobile-desktop parity really costing you search rankings more than you think?
- □ Should you still worry about page weight for SEO in 2024?
- □ Is resource size really the make-or-break factor for your website's speed?
- □ Is Google really enforcing a strict 1 MB limit on images—and what does that tell you about SEO priorities?
- □ Does optimizing page size actually benefit users more than it benefits your search rankings?
- □ Does Googlebot really cap crawling at 15 MB per URL?
- □ Is exploding web page weight hurting your SEO? Here's what you need to know
- □ Is page size really still hurting your SEO in 2024?
- □ Are structured data slowing down your pages enough to harm your SEO?
- □ Does page loading speed really impact your conversion rates?
- □ Does network compression really optimize user device storage space, or is it just a temporary fix?
- □ Is content disparity between mobile and desktop killing your rankings in mobile-first indexing?
- □ Is lazy loading really a must-have SEO performance lever you should activate systematically?
- □ Does Google really block 40 billion spam URLs daily—and how does your site avoid the filter?
- □ Can image optimization really cut your page weight by 90%?
- □ Does Googlebot really stop at 15 MB per URL?
- □ Why is mobile-desktop parity sabotaging your rankings in Mobile-First Indexing?
- □ Is your page weight really slowing down your SEO performance?
- □ Does structured data really slow down your crawl budget?
- □ Does Google really block 40 billion spam URLs every single day?
- □ Should you really cap your images at 1 MB to satisfy Google?
- □ Does Googlebot really stop crawling after 15 MB per URL?
- □ Does site speed really impact your conversion rates?
- □ Is mobile-desktop mismatch really destroying your SEO rankings right now?
- □ Do structured data markups really bloat your HTML pages?
- □ Does page size really matter for SEO when internet connections keep getting faster?
- □ Is network compression really enough to optimize your site's crawlability?
- □ Can lazy loading really boost your performance without hurting crawlability?
- □ Does your website's overall size really hurt your SEO performance?
- □ Why does Google enforce a strict 1MB image size limit across its developer documentation?
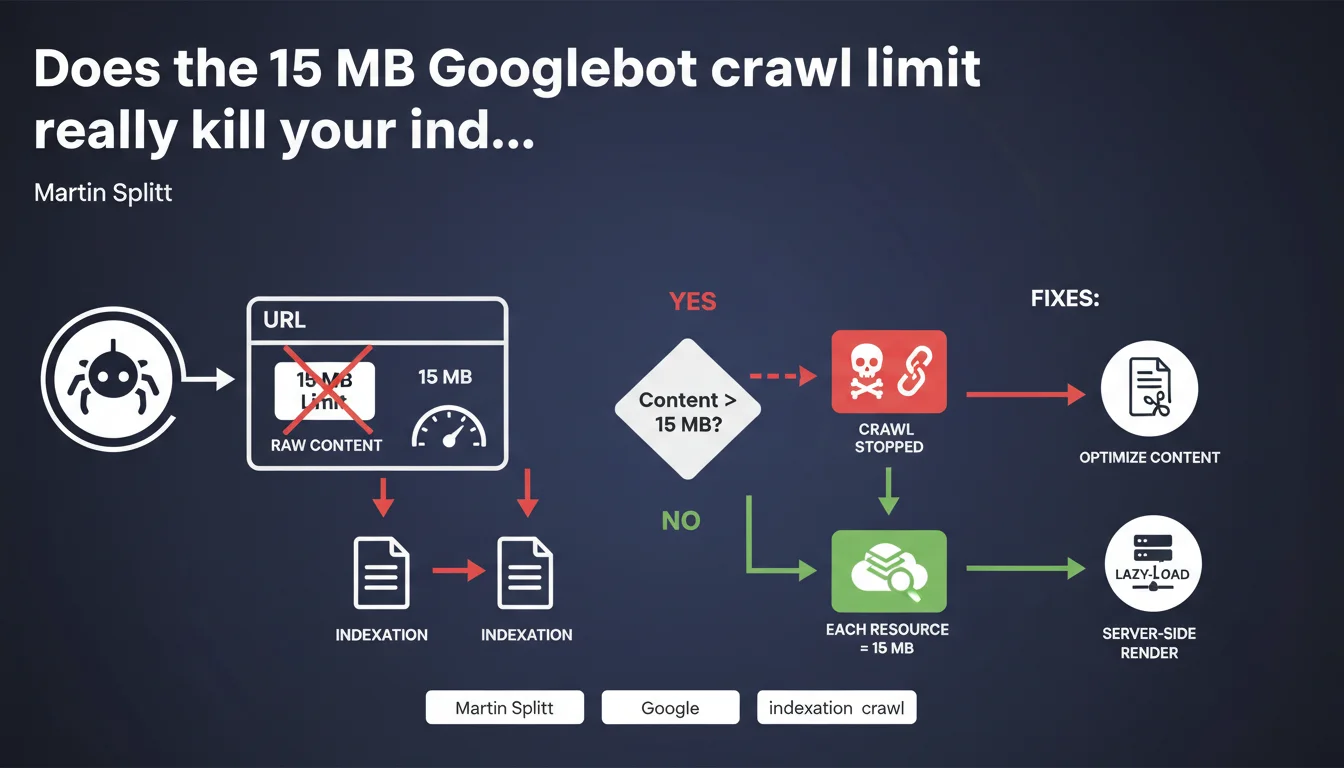
Googlebot downloads a maximum of 15 MB of raw content per URL before stopping. This limit applies individually to each resource: HTML, CSS, JS, images — each one has its own 15 MB quota. If your page exceeds this size, Google will simply not index the entire content.
What you need to understand
What exactly does this 15 MB limit apply to?
Google is talking about raw content (raw bytes), meaning uncompressed data retrieved by Googlebot. Even if your server sends a file compressed with gzip or brotli, Google counts the 15 MB after decompression.
The limit applies resource by resource. Your HTML can weigh 14 MB, your main CSS file 12 MB, and your JavaScript bundle 10 MB — each is treated separately. Googlebot doesn't add up the weights to block the entire page, but it stops dead on any file that exceeds the threshold.
Why does Google impose this restriction?
Crawl budget is an economic reality for Google. Every byte downloaded costs bandwidth, processing time, storage. A strict limit prevents any single file from monopolizing disproportionate resources.
This constraint also protects Google's infrastructure against poorly optimized or malicious sites that might attempt to inject astronomical amounts of content into a single URL. Let's be honest: a 15 MB HTML file is already a symptom of catastrophic architecture.
What happens to content beyond 15 MB?
Googlebot simply stops. It will never see what comes next. If your primary navigation, internal links, or structuring elements are located after this cutoff, they simply don't exist for Google.
Concretely, if your HTML reaches 15.5 MB, the last 500 KB disappear from the radar. This can include entire sections of content, schema.org tags, critical internal linking elements.
- 15 MB of raw content = strict limit per URL, counted after decompression
- Each resource (HTML, CSS, JS, images) has its own independent limit
- Beyond 15 MB, Googlebot stops downloading and ignores the rest of the file
- Critical impact on indexation if essential elements are located after the cutoff
- No cumulative counting: each referenced file restarts its own counter at zero
SEO Expert opinion
Is this statement consistent with field observations?
Yes, and it's even an official confirmation of a limit that's been circulating in the SEO community for years. We regularly observe cases where pages with dynamically generated content — e-commerce catalogs, directory listings, infinite category pages — see their HTML explode in size.
The typical problem? Sites that inline massive JSON data, duplicate content in HTML attributes, or load hundreds of products on a single page without pagination. These architectures easily exceed 15 MB and lose entire sections of content in indexation.
What nuances should be applied to this rule?
Martin Splitt doesn't specify whether this limit applies before or after JavaScript rendering. If your initial HTML weighs 2 MB but the DOM generated by your framework reaches 18 MB after hydration, what happens? [To verify] — Google has never publicly clarified this point.
Another gray area: referenced but non-essential resources for rendering. Will a 20 MB background image in a CSS file be partially downloaded or completely ignored? The answer probably depends on context and resource type. We lack concrete data on this scenario.
Finally, this limit is a technical constraint, not a qualitative recommendation. Just because your page weighs 14 MB doesn't mean it's optimized — it remains catastrophic for UX, crawl budget, and Core Web Vitals.
In what cases does this rule really pose a problem?
The most impacted sites are those generating massively aggregated content: vertical search engines, price comparators, marketplaces with hundreds of product variants on a single page.
Concrete observed case: an e-commerce site loading 500 products per category to artificially improve "content depth". Result: 22 MB HTML. Google cut off before the footer, thus losing all critical internal linking elements. Indexation of deep pages collapsed.
Practical impact and recommendations
How do you verify if your site is affected by this limit?
First step: identify at-risk URLs. Use a crawler like Screaming Frog or Oncrawl and filter pages where HTML exceeds 5 MB — you're already in the red zone. Then examine your JS and CSS resources: a 10 MB webpack bundle isn't uncommon on poorly optimized React applications.
Check with Chrome DevTools the Network tab, "Size" column (uncheck "Disable cache"). Look at the size after decompression, not the transferred size. This is the value that matters to Googlebot.
Also test with curl -H "Accept-Encoding: gzip" -s https://yoursite.com | wc -c to get the raw size that Google retrieves. If the result approaches or exceeds 15,000,000 bytes, you have a problem.
What should you concretely do to stay under this limit?
Paginate. Always. If you display long lists — products, articles, directories — split them into pages of 20-50 elements maximum. Use clean URL parameters (?page=2) with rel="next" and rel="prev" tags if relevant.
Remove all unnecessary content from the HTML source: no redundant JSON-LD, no data duplication between data-* attributes and visible content, no massive inline CSS or JS. Externalize your resources and optimize them individually.
For heavyweight JavaScript applications, adopt code splitting. Load only what's strictly necessary for first render. Lazy-load secondary modules after user interaction. Webpack, Vite, Parcel — all modern bundlers support this approach.
What errors must you absolutely avoid?
Don't attempt to "work around" this limit by artificially splitting your content across multiple URLs without editorial logic. Google detects this type of manipulation and may consider it doorway pages.
Also avoid relying solely on server compression (gzip/brotli) to stay under the limit. It certainly reduces network transfer, but Google counts bytes after decompression. A 25 MB file compressed to 12 MB is still a 25 MB file for Googlebot.
- Audit all pages exceeding 5 MB of raw HTML with a professional crawler
- Measure the actual (non-compressed) size of each resource in Chrome DevTools
- Systematically paginate long lists (products, articles, directories)
- Externalize CSS and JavaScript — never massive inline content in HTML
- Implement code splitting on modern JS applications (React, Vue, Angular)
- Remove all redundancy: unnecessary JSON-LD, duplicated data-* attributes, hidden content
- Regularly test with curl or monitoring tools the raw size of critical resources
- Monitor the evolution of page weight in your monthly crawl budget
❓ Frequently Asked Questions
La limite de 15 Mo s'applique-t-elle au contenu compressé ou décompressé ?
Si mon HTML dépasse 15 Mo, Google indexe-t-il quand même une partie de la page ?
Cette limite concerne-t-elle aussi les images et les vidéos intégrées ?
Comment savoir si mes pages dépassent cette limite ?
Un site en JavaScript client-side (React, Vue) est-il plus exposé à ce problème ?
🎥 From the same video 43
Other SEO insights extracted from this same Google Search Central video · published on 30/03/2026
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.