Declaration officielle
Autres déclarations de cette vidéo 43 ▾
- □ Google mesure-t-il vraiment le poids de page comme vous le pensez ?
- □ Le poids des pages mobiles a triplé en 10 ans : faut-il s'inquiéter pour le SEO ?
- □ Les données structurées alourdissent-elles trop vos pages pour être rentables en SEO ?
- □ Votre site mobile contient-il autant de contenu que votre version desktop ?
- □ Pourquoi votre contenu desktop disparaît-il des résultats Google s'il manque sur mobile ?
- □ La vitesse de page impacte-t-elle réellement les conversions selon Google ?
- □ Google traite-t-il vraiment 40 milliards d'URLs de spam par jour ?
- □ La compression réseau améliore-t-elle réellement le crawl budget de votre site ?
- □ Le lazy loading est-il vraiment indispensable pour optimiser le poids initial de vos pages ?
- □ Googlebot s'arrête-t-il vraiment après 15 Mo par URL ?
- □ Pourquoi le poids des pages mobiles a-t-il triplé en une décennie ?
- □ Le poids des pages impacte-t-il vraiment l'expérience utilisateur et le SEO ?
- □ Les données structurées alourdissent-elles vraiment vos pages HTML ?
- □ Pourquoi la parité mobile-desktop reste-t-elle un facteur de déclassement majeur ?
- □ Faut-il encore se préoccuper du poids des pages pour le SEO ?
- □ La taille des ressources est-elle le facteur déterminant de la vitesse de votre site ?
- □ Pourquoi Google impose-t-il une limite stricte de 1 Mo pour les images ?
- □ L'optimisation de la taille des pages profite-t-elle vraiment plus aux utilisateurs qu'au SEO ?
- □ Googlebot limite-t-il vraiment le crawl à 15 Mo par URL ?
- □ Le poids des pages web explose : faut-il s'inquiéter pour son SEO ?
- □ La taille des pages web nuit-elle encore vraiment à votre SEO ?
- □ Les structured data alourdissent-elles vos pages au point de nuire au SEO ?
- □ La vitesse de chargement influence-t-elle vraiment les conversions de vos pages ?
- □ La compression réseau suffit-elle à optimiser l'espace de stockage des utilisateurs ?
- □ Pourquoi la disparité mobile/desktop tue-t-elle votre référencement en indexation mobile-first ?
- □ Le lazy loading est-il vraiment un levier de performance SEO à activer systématiquement ?
- □ Google bloque 40 milliards d'URLs de spam par jour : comment votre site échappe-t-il au filtre ?
- □ L'optimisation des images peut-elle vraiment diviser par 10 le poids de vos pages ?
- □ Googlebot s'arrête-t-il vraiment à 15 Mo par URL ?
- □ Pourquoi la parité mobile-desktop impacte-t-elle autant votre classement en Mobile-First Indexing ?
- □ Le poids de vos pages freine-t-il vraiment votre référencement ?
- □ Les données structurées ralentissent-elles vraiment votre crawl ?
- □ Google intercepte vraiment 40 milliards d'URLs de spam par jour ?
- □ Faut-il limiter vos images à 1 Mo pour plaire à Google ?
- □ Googlebot s'arrête-t-il vraiment à 15 Mo par URL crawlée ?
- □ La vitesse d'un site impacte-t-elle vraiment la conversion ?
- □ Pourquoi la disparité mobile-desktop ruine-t-elle encore tant de classements SEO ?
- □ Les données structurées alourdissent-elles vraiment vos pages HTML ?
- □ Pourquoi la taille des pages reste-t-elle un facteur SEO critique malgré l'amélioration des connexions Internet ?
- □ La compression réseau suffit-elle à optimiser le crawl de votre site ?
- □ Le lazy loading peut-il vraiment booster vos performances sans impacter le crawl ?
- □ La taille d'un site web a-t-elle vraiment un impact sur son référencement ?
- □ Pourquoi Google limite-t-il la taille des images à 1Mo sur sa documentation développeur ?
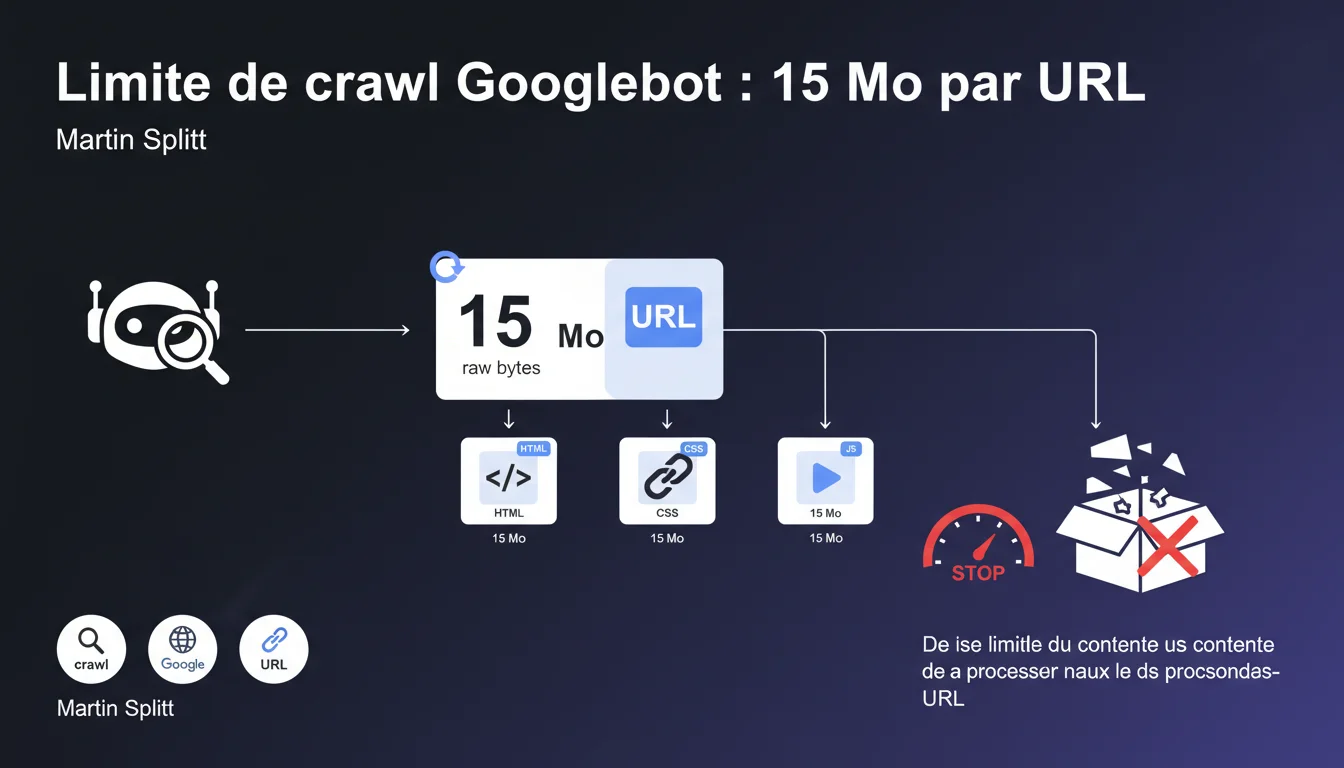
Googlebot télécharge au maximum 15 Mo de contenu brut par URL avant de s'arrêter. Cette limite s'applique individuellement à chaque ressource : HTML, CSS, JS, images — chacune dispose de son propre quota de 15 Mo. Si votre page dépasse cette taille, Google n'indexera tout simplement pas l'intégralité du contenu.
Ce qu'il faut comprendre
Cette limite de 15 Mo concerne quoi exactement ?
Google parle ici de contenu brut (raw bytes), c'est-à-dire les données non compressées récupérées par Googlebot. Même si votre serveur envoie un fichier compressé en gzip ou brotli, Google décompte les 15 Mo après décompression.
La limite s'applique ressource par ressource. Votre HTML peut peser 14 Mo, votre fichier CSS principal 12 Mo, et votre bundle JavaScript 10 Mo — chacun est traité séparément. Googlebot ne cumule pas les poids pour bloquer l'ensemble de la page, mais il s'arrête net sur chaque fichier qui dépasse le seuil.
Pourquoi Google impose-t-il cette restriction ?
Le crawl budget est une réalité économique pour Google. Chaque octet téléchargé coûte en bande passante, en temps de traitement, en stockage. Une limite stricte évite qu'un seul fichier monopolise des ressources démesurées.
Cette contrainte protège aussi l'infrastructure de Google contre les sites mal optimisés ou malveillants qui pourraient tenter d'injecter des quantités astronomiques de contenu dans une seule URL. Soyons honnêtes : un HTML de 15 Mo, c'est déjà un symptôme d'architecture catastrophique.
Qu'arrive-t-il au contenu au-delà des 15 Mo ?
Googlebot s'arrête purement et simplement. Il ne verra jamais ce qui suit. Si votre navigation principale, vos liens internes ou vos éléments structurants se trouvent après cette coupure, ils n'existent tout simplement pas pour Google.
Concrètement, si votre HTML atteint 15,5 Mo, les 500 derniers ko disparaissent du radar. Cela peut inclure des sections entières de contenu, des balises schema.org, des liens de maillage interne critiques.
- 15 Mo de contenu brut = limite stricte par URL, décomptée après décompression
- Chaque ressource (HTML, CSS, JS, images) dispose de sa propre limite indépendante
- Au-delà de 15 Mo, Googlebot arrête le téléchargement et ignore le reste du fichier
- Impact critique sur l'indexation si des éléments essentiels sont situés après la coupure
- Pas de cumul : chaque fichier référencé redémarre son propre compteur à zéro
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées sur le terrain ?
Oui, et c'est même une confirmation officielle d'une limite qui circulait depuis des années dans la communauté SEO. On observe régulièrement des cas où des pages avec du contenu généré dynamiquement — catalogues e-commerce, listings d'annuaires, pages catégories infinies — voient leur HTML exploser en taille.
Le problème typique ? Les sites qui inline-ent des données JSON massives, qui dupliquent du contenu dans des attributs HTML, ou qui chargent des centaines de produits dans une seule page sans pagination. Ces architectures dépassent facilement les 15 Mo et perdent des pans entiers de leur contenu dans l'indexation.
Quelles nuances faut-il apporter à cette règle ?
Martin Splitt ne précise pas si cette limite s'applique avant ou après le rendu JavaScript. Si votre HTML initial pèse 2 Mo mais que le DOM généré par votre framework atteint 18 Mo après hydratation, que se passe-t-il ? [A vérifier] — Google n'a jamais clarifié ce point publiquement.
Autre zone grise : les ressources référencées mais non essentielles au rendu. Une image de fond de 20 Mo dans un CSS sera-t-elle téléchargée partiellement ou complètement ignorée ? La réponse dépend probablement du contexte et du type de ressource. On manque de données concrètes sur ce cas de figure.
Enfin, cette limite est une contrainte technique, pas une recommandation qualitative. Ce n'est pas parce que votre page pèse 14 Mo qu'elle est optimisée — elle reste catastrophique pour l'UX, le crawl budget et les Core Web Vitals.
Dans quels cas cette règle pose-t-elle vraiment problème ?
Les sites les plus impactés sont ceux qui génèrent du contenu massivement agrégé : moteurs de recherche verticaux, comparateurs de prix, marketplaces avec des centaines de variantes produits sur une seule page.
Cas concret observé : un site e-commerce qui chargeait 500 produits par catégorie pour améliorer artificiellement la « profondeur de contenu ». Résultat : HTML de 22 Mo. Google coupait avant le footer, perdant ainsi tous les liens de maillage interne critiques. L'indexation des pages profondes s'est effondrée.
Impact pratique et recommandations
Comment vérifier si votre site est concerné par cette limite ?
Première étape : identifier les URLs à risque. Utilisez un crawler comme Screaming Frog ou Oncrawl et filtrez les pages dont le HTML dépasse 5 Mo — vous êtes déjà dans la zone rouge. Examinez ensuite vos ressources JS et CSS : un bundle webpack de 10 Mo n'est pas rare sur des applications React mal optimisées.
Vérifiez avec Chrome DevTools l'onglet Network, colonne « Size » (décoché « Disable cache »). Regardez la taille après décompression, pas la taille transférée. C'est cette valeur qui compte pour Googlebot.
Testez également avec curl -H "Accept-Encoding: gzip" -s https://votresite.com | wc -c pour obtenir la taille brute que Google récupère. Si le résultat approche ou dépasse 15 000 000 octets, vous avez un problème.
Que faut-il faire concrètement pour rester sous cette limite ?
Paginez. Toujours. Si vous affichez des listes longues — produits, articles, annuaires — découpez en pages de 20-50 éléments maximum. Utilisez des paramètres d'URL propres (?page=2) avec des balises rel="next" et rel="prev" si pertinent.
Supprimez tout contenu inutile dans le HTML source : pas de JSON-LD redondant, pas de duplication de données entre attributs data-* et contenu visible, pas d'inline CSS ou JS massif. Externalisez vos ressources et optimisez-les individuellement.
Pour les applications JavaScript lourdes, adoptez le code splitting. Ne chargez que le strict nécessaire au premier rendu. Lazy-loadez les modules secondaires après l'interaction utilisateur. Webpack, Vite, Parcel — tous les bundlers modernes supportent cette approche.
Quelles erreurs éviter absolument ?
Ne tentez pas de « contourner » cette limite en splitant artificiellement votre contenu sur plusieurs URLs sans logique éditoriale. Google détecte ce type de manipulation et peut considérer cela comme du doorway pages.
Évitez également de compter uniquement sur la compression serveur (gzip/brotli) pour rester sous la limite. Certes, elle réduit le transfert réseau, mais Google décompte les octets après décompression. Un fichier de 25 Mo compressé à 12 Mo reste un fichier de 25 Mo pour Googlebot.
- Auditer toutes les pages dépassant 5 Mo de HTML brut avec un crawler professionnel
- Mesurer la taille réelle (non compressée) de chaque ressource dans Chrome DevTools
- Paginer systématiquement les listes longues (produits, articles, annuaires)
- Externaliser CSS et JavaScript — jamais d'inline massif dans le HTML
- Implémenter le code splitting sur les applications JS modernes (React, Vue, Angular)
- Supprimer toute redondance : JSON-LD inutile, attributs data-* dupliqués, contenu caché
- Tester régulièrement avec curl ou des outils de monitoring la taille brute des ressources critiques
- Monitorer l'évolution du poids des pages dans votre crawl budget mensuel
❓ Questions frequentes
La limite de 15 Mo s'applique-t-elle au contenu compressé ou décompressé ?
Si mon HTML dépasse 15 Mo, Google indexe-t-il quand même une partie de la page ?
Cette limite concerne-t-elle aussi les images et les vidéos intégrées ?
Comment savoir si mes pages dépassent cette limite ?
Un site en JavaScript client-side (React, Vue) est-il plus exposé à ce problème ?
🎥 De la même vidéo 43
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 30/03/2026
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.