Declaration officielle
Autres déclarations de cette vidéo 43 ▾
- □ Pourquoi Googlebot s'arrête-t-il à 15 Mo par URL et comment cela impacte-t-il votre crawl ?
- □ Google mesure-t-il vraiment le poids de page comme vous le pensez ?
- □ Le poids des pages mobiles a triplé en 10 ans : faut-il s'inquiéter pour le SEO ?
- □ Les données structurées alourdissent-elles trop vos pages pour être rentables en SEO ?
- □ Votre site mobile contient-il autant de contenu que votre version desktop ?
- □ Pourquoi votre contenu desktop disparaît-il des résultats Google s'il manque sur mobile ?
- □ La vitesse de page impacte-t-elle réellement les conversions selon Google ?
- □ Google traite-t-il vraiment 40 milliards d'URLs de spam par jour ?
- □ La compression réseau améliore-t-elle réellement le crawl budget de votre site ?
- □ Le lazy loading est-il vraiment indispensable pour optimiser le poids initial de vos pages ?
- □ Googlebot s'arrête-t-il vraiment après 15 Mo par URL ?
- □ Pourquoi le poids des pages mobiles a-t-il triplé en une décennie ?
- □ Le poids des pages impacte-t-il vraiment l'expérience utilisateur et le SEO ?
- □ Les données structurées alourdissent-elles vraiment vos pages HTML ?
- □ Pourquoi la parité mobile-desktop reste-t-elle un facteur de déclassement majeur ?
- □ Faut-il encore se préoccuper du poids des pages pour le SEO ?
- □ La taille des ressources est-elle le facteur déterminant de la vitesse de votre site ?
- □ Pourquoi Google impose-t-il une limite stricte de 1 Mo pour les images ?
- □ L'optimisation de la taille des pages profite-t-elle vraiment plus aux utilisateurs qu'au SEO ?
- □ Googlebot limite-t-il vraiment le crawl à 15 Mo par URL ?
- □ Le poids des pages web explose : faut-il s'inquiéter pour son SEO ?
- □ La taille des pages web nuit-elle encore vraiment à votre SEO ?
- □ Les structured data alourdissent-elles vos pages au point de nuire au SEO ?
- □ La vitesse de chargement influence-t-elle vraiment les conversions de vos pages ?
- □ La compression réseau suffit-elle à optimiser l'espace de stockage des utilisateurs ?
- □ Pourquoi la disparité mobile/desktop tue-t-elle votre référencement en indexation mobile-first ?
- □ Le lazy loading est-il vraiment un levier de performance SEO à activer systématiquement ?
- □ Google bloque 40 milliards d'URLs de spam par jour : comment votre site échappe-t-il au filtre ?
- □ L'optimisation des images peut-elle vraiment diviser par 10 le poids de vos pages ?
- □ Googlebot s'arrête-t-il vraiment à 15 Mo par URL ?
- □ Pourquoi la parité mobile-desktop impacte-t-elle autant votre classement en Mobile-First Indexing ?
- □ Le poids de vos pages freine-t-il vraiment votre référencement ?
- □ Les données structurées ralentissent-elles vraiment votre crawl ?
- □ Google intercepte vraiment 40 milliards d'URLs de spam par jour ?
- □ Faut-il limiter vos images à 1 Mo pour plaire à Google ?
- □ La vitesse d'un site impacte-t-elle vraiment la conversion ?
- □ Pourquoi la disparité mobile-desktop ruine-t-elle encore tant de classements SEO ?
- □ Les données structurées alourdissent-elles vraiment vos pages HTML ?
- □ Pourquoi la taille des pages reste-t-elle un facteur SEO critique malgré l'amélioration des connexions Internet ?
- □ La compression réseau suffit-elle à optimiser le crawl de votre site ?
- □ Le lazy loading peut-il vraiment booster vos performances sans impacter le crawl ?
- □ La taille d'un site web a-t-elle vraiment un impact sur son référencement ?
- □ Pourquoi Google limite-t-il la taille des images à 1Mo sur sa documentation développeur ?
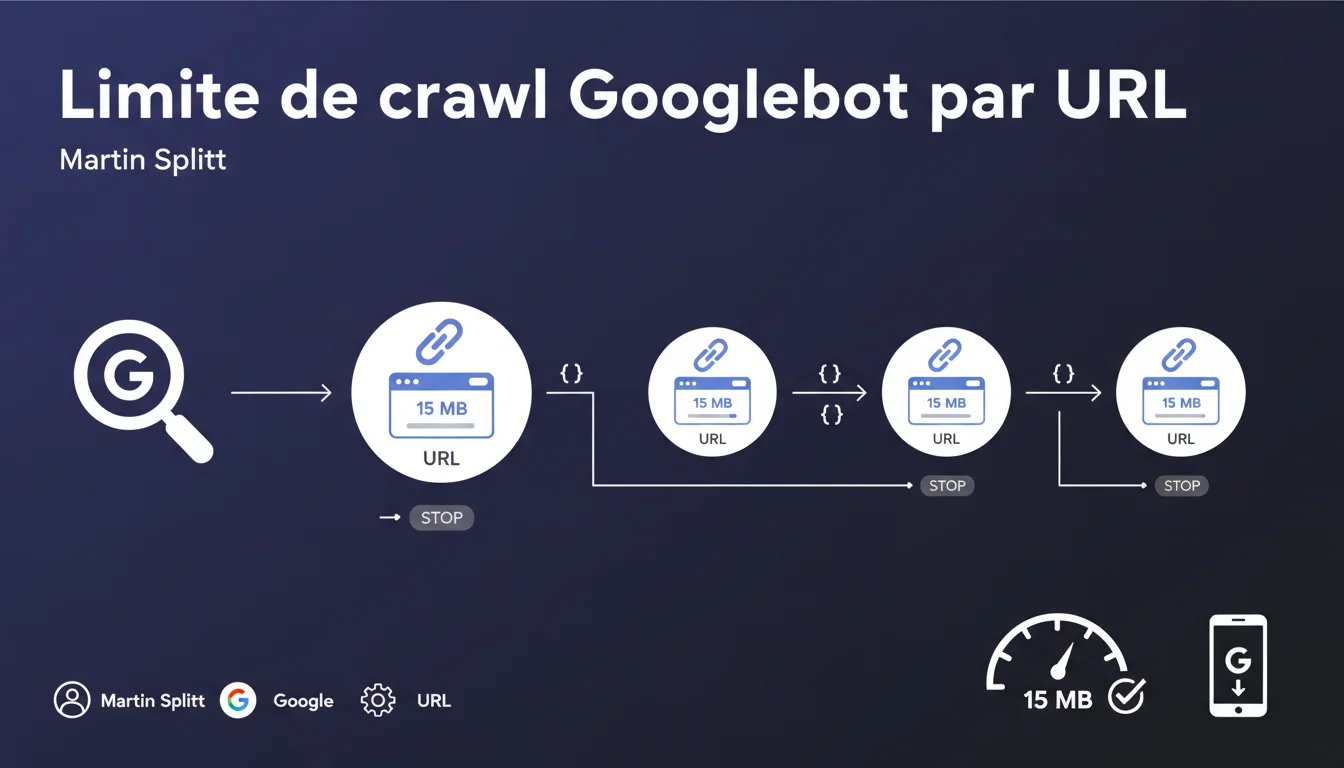
Googlebot ne crawle que les 15 premiers mégaoctets de contenu brut par URL, puis s'arrête net. Cette limite s'applique individuellement à chaque ressource : HTML, CSS, JS, images — chacune dispose de son propre quota de 15 Mo. Tout ce qui dépasse est ignoré, ce qui peut compromettre l'indexation si votre contenu critique arrive après cette barre.
Ce qu'il faut comprendre
Google impose une limite stricte de 15 Mo par URL crawlée. Concrètement, si votre page HTML pèse 18 Mo, Googlebot ne lira que les 15 premiers mégaoctets et ignorera les 3 derniers. Cette règle n'est pas nouvelle, mais sa confirmation officielle clarifie enfin ce que beaucoup soupçonnaient.
Chaque ressource externe — feuille de style, script, image — bénéficie de sa propre enveloppe de 15 Mo. Ce n'est pas un budget global par page, mais une limite individuelle par fichier. Une page HTML peut donc théoriquement orchestrer plusieurs centaines de mégaoctets de ressources, à condition qu'aucune ne franchisse seule le seuil.
Pourquoi cette limite existe-t-elle ?
Google doit crawler des milliards de pages. Allouer des ressources infinies à chaque URL serait techniquement et économiquement absurde. La limite de 15 Mo sert de garde-fou contre les contenus trop lourds, mal optimisés ou générés dynamiquement sans contrôle.
Elle protège aussi l'infrastructure de Google contre les sites qui, volontairement ou non, envoient des flux de données interminables. Le moteur préfère couper court plutôt que de gaspiller du temps machine.
Cette limite impacte-t-elle vraiment les sites classiques ?
Pour la majorité des sites web, 15 Mo par ressource est largement suffisant. Une page HTML classique pèse rarement plus de 100-200 Ko. Même des sites médias riches ne franchissent généralement pas ce seuil pour leur HTML ou leurs scripts principaux.
Là où ça coince : les sites e-commerce avec des catalogues JSON massifs, les plateformes qui génèrent du HTML dynamique sans pagination, ou encore les SPAs (Single Page Applications) qui envoient tout le contenu d'un coup. Si votre contenu stratégique — descriptions produits, données structurées, maillage interne — arrive après les 15 premiers Mo, Google ne le verra jamais.
- La limite s'applique par URL, pas par page ou domaine.
- Chaque ressource externe (CSS, JS, images) a son propre quota de 15 Mo.
- Si une ressource dépasse 15 Mo, tout ce qui suit est ignoré définitivement.
- Cette règle concerne le contenu brut avant décompression — un fichier gzippé compte pour sa taille compressée.
- Les sites avec du lazy loading ou du rendu différé ne sont pas exemptés : si le HTML de base dépasse 15 Mo, c'est déjà problématique.
Avis d'un expert SEO
Cette limite de 15 Mo est-elle vraiment respectée dans tous les cas ?
Spoiler : non. Ou du moins, pas de manière aussi binaire que Google le laisse entendre. Des tests terrain montrent que certaines pages dépassant 15 Mo sont quand même indexées — partiellement ou totalement. [À vérifier] : Google applique-t-il cette règle strictement sur tous les types de contenus, ou existe-t-il des exceptions pour des sites à fort PageRank ou des contenus jugés critiques ?
Mon hypothèse — et c'est une hypothèse — est que Google tolère des dépassements légers sur des sites de confiance, mais coupe sans appel sur les sites à faible autorité ou ceux qui abusent. Autrement dit, la limite est probablement plus souple pour Le Monde que pour votre e-shop de niche.
Quels sites risquent vraiment de se heurter à cette barrière ?
Trois profils sont particulièrement exposés : les sites e-commerce avec des pages catégories infinies (genre 5000 produits chargés en une seule fois), les plateformes SaaS avec des dashboards boursoufflés de données JSON, et les sites d'actualité qui injectent des dizaines de contenus sponsorisés ou publicitaires avant le contenu principal.
Si vous utilisez du Server-Side Rendering (SSR) mal calibré, vous pouvez facilement dépasser 15 Mo sans vous en rendre compte. Idem pour les sites qui embarquent des bibliothèques JavaScript complètes en inline plutôt qu'en fichiers externes.
Faut-il s'inquiéter pour les ressources externes volumineuses ?
Oui et non. Une image de 20 Mo sera tronquée à 15 Mo par Googlebot, mais ça n'affecte pas l'indexation de votre page HTML — juste la capacité de Google à analyser cette image pour Google Images. Même chose pour les vidéos hébergées en direct sur votre serveur : si elles dépassent 15 Mo, Google ne les crawlera pas entièrement.
En revanche, si votre JavaScript principal pèse 18 Mo, Google ne chargera que les 15 premiers Mo, ce qui peut casser le rendu de votre page côté moteur. Résultat : contenu invisible, indexation foireuse.
Impact pratique et recommandations
Comment vérifier si vos pages dépassent la limite ?
Première étape : simulez un crawl Googlebot avec wget ou curl en limitant la taille de téléchargement à 15 Mo. Commande type : curl -L -r 0-15728640 https://votresite.com/page. Si le fichier récupéré fait exactement 15 Mo, c'est mauvais signe — vous êtes probablement tronqué.
Deuxième méthode : utilisez Screaming Frog ou OnCrawl en activant la limite de taille de contenu à 15 Mo. Filtrez ensuite les URLs dont la taille HTML dépasse ce seuil. Concentrez-vous sur les pages stratégiques : fiches produits, landing pages, hubs de contenu.
Que faire si certaines pages explosent le compteur ?
Trois axes d'optimisation immédiats. Paginez vos contenus longs : au lieu d'afficher 2000 produits sur une page catégorie, passez à 50 par page avec pagination propre (balises rel=next/prev si vous êtes old school, ou simplement une pagination classique). Différez le chargement des contenus secondaires : tout ce qui n'est pas critique pour le rendu initial (avis clients, produits connexes, widgets de réseaux sociaux) peut être lazy-loadé ou injecté via JavaScript après le premier paint.
Enfin, externalisez vos ressources volumineuses. Si vous servez des PDF de 30 Mo ou des images non compressées, migrez-les vers un CDN et optimisez-les. Pour les fichiers JavaScript, privilégiez le découpage en chunks avec du code-splitting plutôt qu'un bundle monolithique.
- Auditez les pages stratégiques avec curl ou wget pour mesurer leur poids brut.
- Identifiez les URLs dont le HTML dépasse 10 Mo — vous êtes en zone rouge.
- Paginez les contenus longs : 50-100 éléments max par page.
- Lazy-loadez tout ce qui n'est pas essentiel au rendu initial.
- Externalisez les ressources volumineuses (images, vidéos, PDF) sur un CDN.
- Compressez systématiquement vos ressources avec gzip ou Brotli.
- Découpez vos fichiers JavaScript avec du code-splitting.
- Testez régulièrement vos pages les plus lourdes avec Google Search Console (test d'URL en direct).
La limite de 15 Mo par URL est rarement un problème pour les sites bien conçus, mais peut devenir un angle mort critique pour les plateformes e-commerce, les SPAs mal optimisées ou les sites médias lourds. Auditez vos pages stratégiques, paginez les contenus infinis, et externalisez les ressources volumineuses. Si votre architecture actuelle génère des pages dépassant 10 Mo, repensez votre stratégie de rendu.
Ces optimisations requièrent souvent des arbitrages techniques complexes entre performance, expérience utilisateur et crawlabilité. Si vous identifiez des pages critiques au-delà du seuil, un accompagnement par une agence SEO spécialisée peut vous aider à restructurer votre architecture sans sacrifier vos objectifs métier.
❓ Questions frequentes
La limite de 15 Mo s'applique-t-elle au contenu compressé ou décompressé ?
Si une image fait 20 Mo, Google l'indexe-t-il quand même dans Google Images ?
Cette limite impacte-t-elle le rendu JavaScript des pages ?
Les sites bénéficiant d'un crawl budget élevé échappent-ils à cette règle ?
Comment mesurer précisément le poids d'une page tel que Google la voit ?
🎥 De la même vidéo 43
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 30/03/2026
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.