Declaration officielle
Autres déclarations de cette vidéo 43 ▾
- □ Pourquoi Googlebot s'arrête-t-il à 15 Mo par URL et comment cela impacte-t-il votre crawl ?
- □ Google mesure-t-il vraiment le poids de page comme vous le pensez ?
- □ Le poids des pages mobiles a triplé en 10 ans : faut-il s'inquiéter pour le SEO ?
- □ Les données structurées alourdissent-elles trop vos pages pour être rentables en SEO ?
- □ Votre site mobile contient-il autant de contenu que votre version desktop ?
- □ Pourquoi votre contenu desktop disparaît-il des résultats Google s'il manque sur mobile ?
- □ La vitesse de page impacte-t-elle réellement les conversions selon Google ?
- □ Google traite-t-il vraiment 40 milliards d'URLs de spam par jour ?
- □ La compression réseau améliore-t-elle réellement le crawl budget de votre site ?
- □ Le lazy loading est-il vraiment indispensable pour optimiser le poids initial de vos pages ?
- □ Pourquoi le poids des pages mobiles a-t-il triplé en une décennie ?
- □ Le poids des pages impacte-t-il vraiment l'expérience utilisateur et le SEO ?
- □ Les données structurées alourdissent-elles vraiment vos pages HTML ?
- □ Pourquoi la parité mobile-desktop reste-t-elle un facteur de déclassement majeur ?
- □ Faut-il encore se préoccuper du poids des pages pour le SEO ?
- □ La taille des ressources est-elle le facteur déterminant de la vitesse de votre site ?
- □ Pourquoi Google impose-t-il une limite stricte de 1 Mo pour les images ?
- □ L'optimisation de la taille des pages profite-t-elle vraiment plus aux utilisateurs qu'au SEO ?
- □ Googlebot limite-t-il vraiment le crawl à 15 Mo par URL ?
- □ Le poids des pages web explose : faut-il s'inquiéter pour son SEO ?
- □ La taille des pages web nuit-elle encore vraiment à votre SEO ?
- □ Les structured data alourdissent-elles vos pages au point de nuire au SEO ?
- □ La vitesse de chargement influence-t-elle vraiment les conversions de vos pages ?
- □ La compression réseau suffit-elle à optimiser l'espace de stockage des utilisateurs ?
- □ Pourquoi la disparité mobile/desktop tue-t-elle votre référencement en indexation mobile-first ?
- □ Le lazy loading est-il vraiment un levier de performance SEO à activer systématiquement ?
- □ Google bloque 40 milliards d'URLs de spam par jour : comment votre site échappe-t-il au filtre ?
- □ L'optimisation des images peut-elle vraiment diviser par 10 le poids de vos pages ?
- □ Googlebot s'arrête-t-il vraiment à 15 Mo par URL ?
- □ Pourquoi la parité mobile-desktop impacte-t-elle autant votre classement en Mobile-First Indexing ?
- □ Le poids de vos pages freine-t-il vraiment votre référencement ?
- □ Les données structurées ralentissent-elles vraiment votre crawl ?
- □ Google intercepte vraiment 40 milliards d'URLs de spam par jour ?
- □ Faut-il limiter vos images à 1 Mo pour plaire à Google ?
- □ Googlebot s'arrête-t-il vraiment à 15 Mo par URL crawlée ?
- □ La vitesse d'un site impacte-t-elle vraiment la conversion ?
- □ Pourquoi la disparité mobile-desktop ruine-t-elle encore tant de classements SEO ?
- □ Les données structurées alourdissent-elles vraiment vos pages HTML ?
- □ Pourquoi la taille des pages reste-t-elle un facteur SEO critique malgré l'amélioration des connexions Internet ?
- □ La compression réseau suffit-elle à optimiser le crawl de votre site ?
- □ Le lazy loading peut-il vraiment booster vos performances sans impacter le crawl ?
- □ La taille d'un site web a-t-elle vraiment un impact sur son référencement ?
- □ Pourquoi Google limite-t-il la taille des images à 1Mo sur sa documentation développeur ?
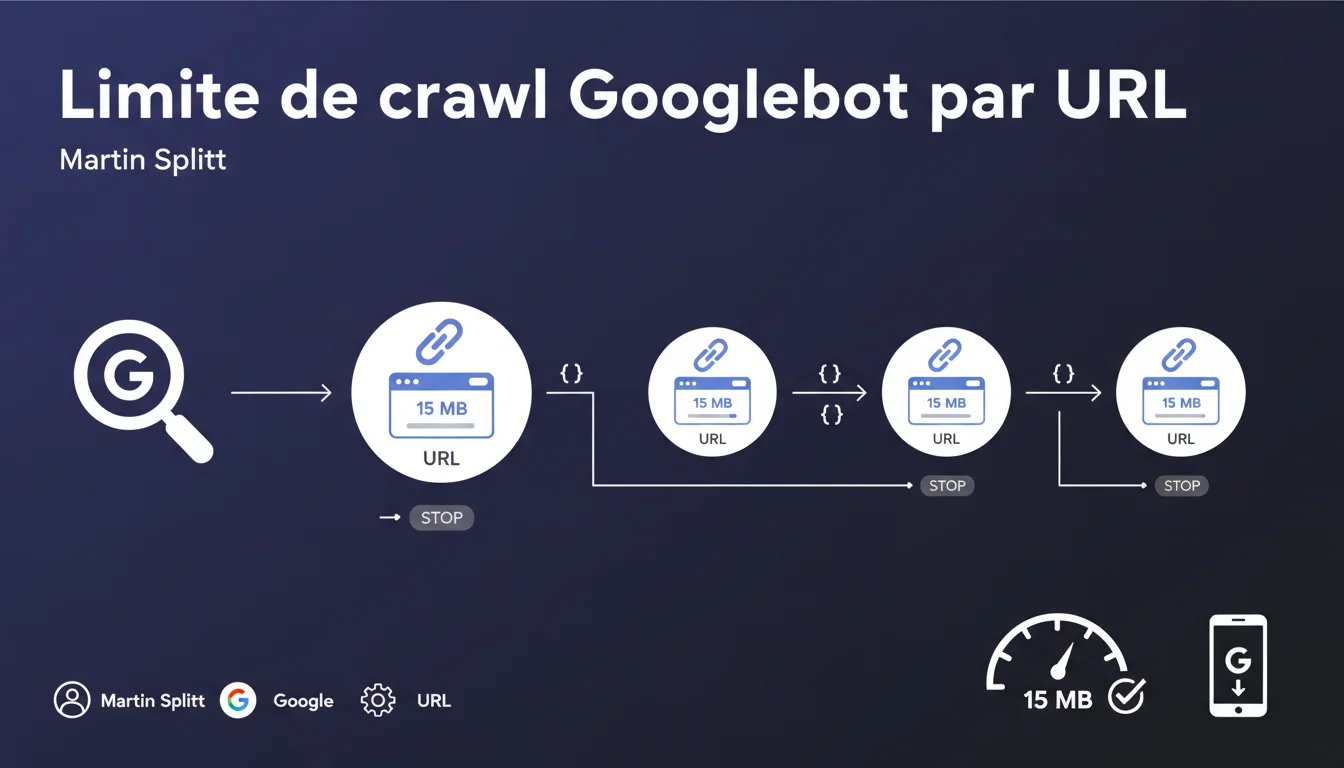
Googlebot impose une limite stricte de 15 Mo de contenu brut par URL crawlée. Au-delà, le bot arrête la récupération. Cette règle s'applique individuellement à chaque ressource : HTML, CSS, JS, images ont chacun leur propre quota. Les sites avec des pages volumineuses ou des ressources lourdes risquent une indexation partielle.
Ce qu'il faut comprendre
Que signifie exactement cette limite de 15 Mo ?
La limite s'applique au contenu brut non compressé récupéré par Googlebot. Quand le bot télécharge votre HTML, CSS, JavaScript ou toute autre ressource, il compte les octets reçus. À 15 Mo, il coupe la connexion et passe à autre chose.
Point crucial : chaque URL a son propre compteur. Si votre page HTML fait 2 Mo et référence un fichier JavaScript de 18 Mo, le HTML sera crawlé intégralement, mais le JS sera tronqué à 15 Mo. Les deux budgets ne se confondent pas.
Pourquoi Google impose-t-il cette contrainte ?
Le crawl coûte cher en ressources — bande passante, stockage, temps de traitement. Google crawle des milliards de pages chaque jour. Sans limite stricte, un site mal optimisé pourrait monopoliser des ressources disproportionnées.
Cette règle protège aussi les sites crawlés : un bot qui téléchargerait indéfiniment des fichiers gigantesques pourrait saturer des serveurs. La limite de 15 Mo reste généreuse pour la majorité des pages web standards.
Cette limite affecte-t-elle tous les types de contenus ?
Oui, tous les types de ressources sont concernés : HTML, CSS, JavaScript, images, PDF, vidéos. Chaque URL a son propre plafond de 15 Mo.
Un cas fréquent : les pages infinies générées dynamiquement. Si votre HTML continue de charger du contenu via scroll infini sans pagination claire, Googlebot peut atteindre la limite avant d'avoir tout récupéré. Résultat : indexation partielle.
- Limite de 15 Mo par URL, pas par page globale
- S'applique au contenu brut non compressé
- Chaque ressource (HTML, CSS, JS, images) a son propre quota
- Au-delà, Googlebot arrête le téléchargement immédiatement
- Pas de report ou cumul entre ressources
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, et elle confirme ce que beaucoup de praticiens suspectaient. Les tests montrent que Googlebot tronque effectivement les pages volumineuses. Des HTML dépassant 15 Mo voient leur contenu coupé — souvent au milieu d'une balise ou d'un paragraphe.
Le problème, c'est que Google n'envoie pas d'alerte explicite dans Search Console quand cette limite est atteinte. Vous découvrez le problème indirectement : contenu non indexé, sections manquantes dans les snippets, ou crawl incomplet détecté via des logs. [À vérifier] : aucun KPI officiel ne remonte cette métrique directement.
Quels sites sont réellement concernés par cette limite ?
Soyons honnêtes : la majorité des sites n'atteindront jamais 15 Mo par URL. Un HTML classique, même riche, fait rarement plus de 500 Ko à 2 Mo. Les vrais concernés sont des cas particuliers.
Sites e-commerce avec des listings interminables injectés en HTML brut, applications web monopage (SPA) qui chargent tout le contenu d'un coup, pages avec des milliers de lignes de JSON-LD embedded, ou encore sites d'actualités avec des flux infinis. Et c'est là que ça coince : ces structures sont souvent créées sans considération pour le crawl.
Google pourrait-il augmenter cette limite ?
Techniquement, oui. Mais l'enjeu n'est pas technique — il est économique et stratégique. Google crawle efficacement en rationnant ses ressources. Augmenter la limite universellement multiplierait les coûts sans bénéfice proportionnel.
Ce qui manque dans cette déclaration, c'est toute nuance sur les exceptions. Y a-t-il des sites prioritaires qui bénéficient d'une limite supérieure ? Google ne le dit pas. [À vérifier] : aucune donnée publique ne confirme ou infirme l'existence de quotas variables selon le site.
Impact pratique et recommandations
Comment vérifier si votre site dépasse la limite ?
Première étape : analysez la taille de vos URLs. Utilisez Chrome DevTools (onglet Network) pour mesurer la taille non compressée de vos ressources. Attention, le poids affiché « transféré » est souvent compressé — regardez la colonne « size » ou « content length ».
Côté serveur, scrutez vos logs. Cherchez des requêtes Googlebot interrompues brutalement ou des codes HTTP 206 (partial content). Si Googlebot coupe la connexion avant la fin du téléchargement, c'est un signal d'alarme.
- Mesurer la taille brute (non compressée) de chaque URL avec DevTools
- Lister les pages HTML dépassant 5 Mo — ce sont des candidats à risque
- Identifier les ressources JS/CSS tiers volumineuses (> 10 Mo)
- Analyser les logs serveur pour détecter des crawls incomplets
- Tester l'indexation réelle avec une recherche
site:ciblée sur du contenu en fin de page
Quelles actions correctives mettre en place ?
Si vos pages dépassent ou approchent la limite, refactorez la structure. Paginez les listings longs au lieu de tout charger d'un coup. Externalisez les données volumineuses (JSON-LD massifs, par exemple) dans des fichiers séparés si elles ne sont pas critiques pour l'indexation.
Pour le JavaScript, divisez vos bundles. Un fichier JS monolithique de 20 Mo est un problème. Code splitting, lazy loading, imports dynamiques : toutes ces techniques réduisent le poids initial. Googlebot rendra mieux des ressources légères et modulaires.
Faut-il repenser son architecture technique ?
Dans certains cas, oui. Les SPAs mal conçues génèrent souvent un HTML initial squelettique, puis injectent tout en JS. Si ce JS dépasse 15 Mo, Googlebot ne verra qu'une coquille vide — ou pire, un contenu tronqué aléatoirement.
Le SSR (Server-Side Rendering) ou le SSG (Static Site Generation) deviennent des alliés stratégiques. Vous livrez du HTML pré-rendu léger, évitant la dépendance à des ressources JS massives. C'est un chantier technique, mais l'impact SEO est direct.
Concrètement : auditez vos URLs volumineuses, paginez ou scindez les contenus lourds, optimisez vos bundles JS/CSS, et surveillez les logs de crawl. Si vos pages flirtent avec la limite, l'indexation est compromise.
Ces optimisations touchent souvent à l'architecture front-end et backend. Quand les enjeux techniques deviennent complexes — refonte de templates, code splitting avancé, SSR — s'entourer d'une agence SEO spécialisée peut accélérer la mise en conformité tout en sécurisant les choix stratégiques. Un diagnostic technique précis évite les erreurs coûteuses.
❓ Questions frequentes
La compression HTTP affecte-t-elle la limite de 15 Mo ?
Google me prévient-il si une URL dépasse la limite ?
Les images et vidéos comptent-elles dans les 15 Mo ?
Le lazy loading résout-il le problème pour les pages longues ?
Peut-on demander une exception à Google pour des sites spécifiques ?
🎥 De la même vidéo 43
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 30/03/2026
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.