Declaration officielle
Autres déclarations de cette vidéo 43 ▾
- □ Pourquoi Googlebot s'arrête-t-il à 15 Mo par URL et comment cela impacte-t-il votre crawl ?
- □ Google mesure-t-il vraiment le poids de page comme vous le pensez ?
- □ Le poids des pages mobiles a triplé en 10 ans : faut-il s'inquiéter pour le SEO ?
- □ Les données structurées alourdissent-elles trop vos pages pour être rentables en SEO ?
- □ Votre site mobile contient-il autant de contenu que votre version desktop ?
- □ Pourquoi votre contenu desktop disparaît-il des résultats Google s'il manque sur mobile ?
- □ La vitesse de page impacte-t-elle réellement les conversions selon Google ?
- □ Google traite-t-il vraiment 40 milliards d'URLs de spam par jour ?
- □ La compression réseau améliore-t-elle réellement le crawl budget de votre site ?
- □ Le lazy loading est-il vraiment indispensable pour optimiser le poids initial de vos pages ?
- □ Googlebot s'arrête-t-il vraiment après 15 Mo par URL ?
- □ Pourquoi le poids des pages mobiles a-t-il triplé en une décennie ?
- □ Le poids des pages impacte-t-il vraiment l'expérience utilisateur et le SEO ?
- □ Les données structurées alourdissent-elles vraiment vos pages HTML ?
- □ Pourquoi la parité mobile-desktop reste-t-elle un facteur de déclassement majeur ?
- □ Faut-il encore se préoccuper du poids des pages pour le SEO ?
- □ La taille des ressources est-elle le facteur déterminant de la vitesse de votre site ?
- □ Pourquoi Google impose-t-il une limite stricte de 1 Mo pour les images ?
- □ L'optimisation de la taille des pages profite-t-elle vraiment plus aux utilisateurs qu'au SEO ?
- □ Le poids des pages web explose : faut-il s'inquiéter pour son SEO ?
- □ La taille des pages web nuit-elle encore vraiment à votre SEO ?
- □ Les structured data alourdissent-elles vos pages au point de nuire au SEO ?
- □ La vitesse de chargement influence-t-elle vraiment les conversions de vos pages ?
- □ La compression réseau suffit-elle à optimiser l'espace de stockage des utilisateurs ?
- □ Pourquoi la disparité mobile/desktop tue-t-elle votre référencement en indexation mobile-first ?
- □ Le lazy loading est-il vraiment un levier de performance SEO à activer systématiquement ?
- □ Google bloque 40 milliards d'URLs de spam par jour : comment votre site échappe-t-il au filtre ?
- □ L'optimisation des images peut-elle vraiment diviser par 10 le poids de vos pages ?
- □ Googlebot s'arrête-t-il vraiment à 15 Mo par URL ?
- □ Pourquoi la parité mobile-desktop impacte-t-elle autant votre classement en Mobile-First Indexing ?
- □ Le poids de vos pages freine-t-il vraiment votre référencement ?
- □ Les données structurées ralentissent-elles vraiment votre crawl ?
- □ Google intercepte vraiment 40 milliards d'URLs de spam par jour ?
- □ Faut-il limiter vos images à 1 Mo pour plaire à Google ?
- □ Googlebot s'arrête-t-il vraiment à 15 Mo par URL crawlée ?
- □ La vitesse d'un site impacte-t-elle vraiment la conversion ?
- □ Pourquoi la disparité mobile-desktop ruine-t-elle encore tant de classements SEO ?
- □ Les données structurées alourdissent-elles vraiment vos pages HTML ?
- □ Pourquoi la taille des pages reste-t-elle un facteur SEO critique malgré l'amélioration des connexions Internet ?
- □ La compression réseau suffit-elle à optimiser le crawl de votre site ?
- □ Le lazy loading peut-il vraiment booster vos performances sans impacter le crawl ?
- □ La taille d'un site web a-t-elle vraiment un impact sur son référencement ?
- □ Pourquoi Google limite-t-il la taille des images à 1Mo sur sa documentation développeur ?
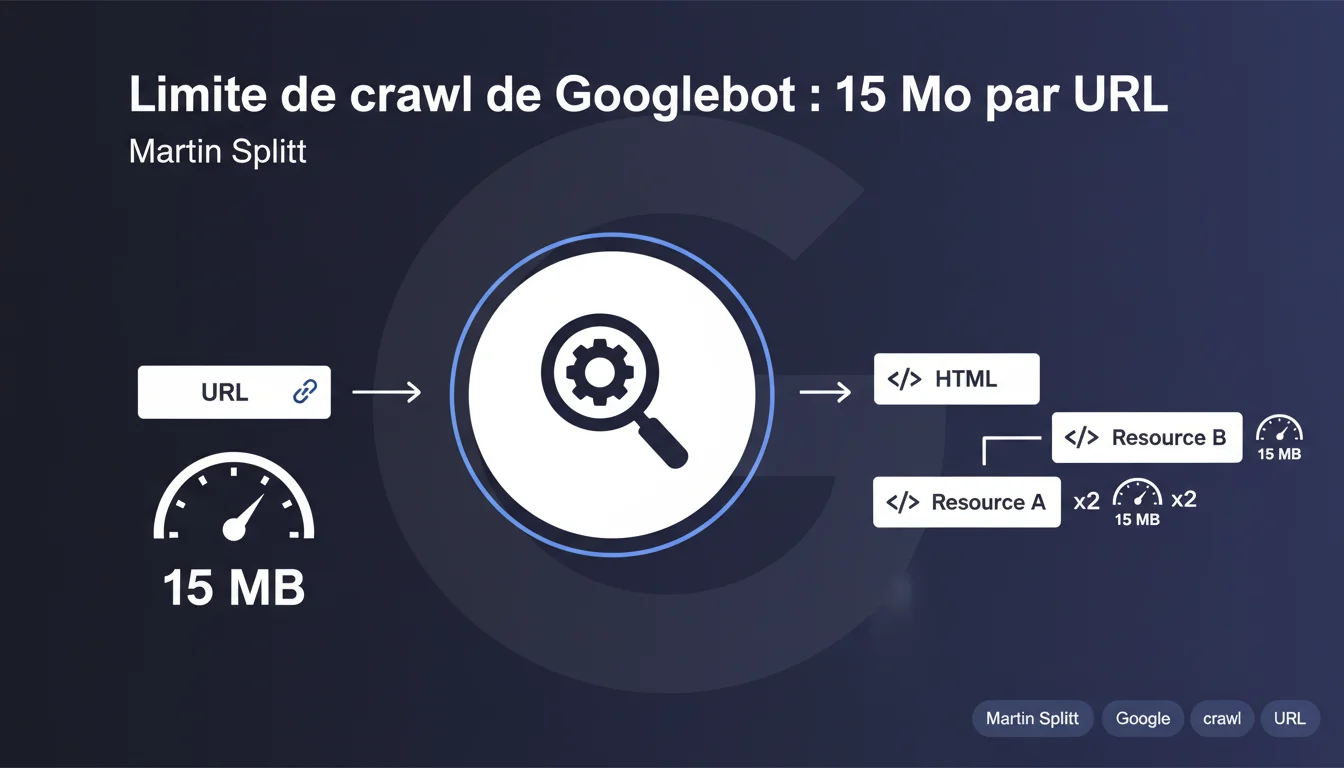
Googlebot récupère par défaut un maximum de 15 mégaoctets de contenu brut par URL avant d'arrêter le crawl. Cette limite s'applique individuellement à chaque ressource : votre HTML principal, mais aussi chaque CSS, JavaScript ou image référencée. Au-delà, le contenu n'est pas indexé.
Ce qu'il faut comprendre
Que signifie concrètement cette limite de 15 Mo ?
Quand Googlebot accède à une URL, il télécharge le contenu brut — HTML non compressé, JavaScript, CSS ou tout autre fichier. Dès que ce contenu dépasse 15 mégaoctets, le bot stoppe la récupération.
Ce qui reste au-delà n'est ni crawlé, ni analysé, ni indexé. Si votre page charge 20 Mo de HTML, les 5 derniers mégaoctets sont purement et simplement ignorés.
Cette limite s'applique-t-elle à chaque ressource séparément ?
Oui. Chaque URL a son propre quota de 15 Mo. Un fichier HTML de 10 Mo peut référencer un JavaScript de 12 Mo et un CSS de 8 Mo : chacun sera crawlé dans la limite de 15 Mo individuellement.
Concrètement, si votre JS principal fait 18 Mo, Googlebot n'en récupérera que 15 Mo. Le reste ? Invisible pour le moteur.
Pourquoi Google impose-t-il cette contrainte ?
Soyons honnêtes : crawler le web entier coûte cher en bande passante, en temps de traitement et en infrastructure. Limiter la taille des fichiers récupérés permet à Google de maximiser l'efficacité du crawl budget.
Dans la pratique, très peu de pages web légitimes dépassent 15 Mo de HTML brut. Cette limite vise surtout les cas extrêmes : pages générées dynamiquement mal configurées, dumps de données, contenus parasites.
- Chaque URL crawlée a une limite individuelle de 15 Mo de contenu brut
- Le contenu au-delà de cette limite n'est ni analysé ni indexé
- Cela inclut HTML, JavaScript, CSS et toute autre ressource
- La compression n'entre pas en jeu : c'est le contenu décompressé qui compte
- Cette règle protège le crawl budget de Google face aux pages démesurées
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Globalement, oui. Les SEO qui ont testé des pages volumineuses rapportent des tronquages de contenu au-delà de seuils conséquents. Mais 15 Mo, c'est une limite rarement atteinte sur des sites classiques.
Le vrai problème ? Les sites JavaScript-heavy qui compilent des bundles monstrueux ou les plateformes e-commerce avec des catalogues produits infinis injectés en HTML. Là, cette limite peut mordre.
Quelles nuances faut-il apporter ?
Première nuance : Google parle de contenu brut, donc décompressé. Si tu envoies du Gzip ou du Brotli, le fichier transmis sur le réseau sera plus léger, mais Googlebot décompresse avant de compter.
Deuxième point — et c'est là que ça coince. Google ne précise pas si cette limite s'applique avant ou après le rendu JavaScript. Une page peut faire 5 Mo en HTML initial, puis exploser à 18 Mo après exécution JS. [A vérifier] sur des cas réels avec de gros frameworks front.
Dans quels cas cette règle devient-elle vraiment problématique ?
Les single-page applications (SPA) mal optimisées, qui chargent tout le catalogue produit côté client. Les sites de documentation technique qui génèrent des pages HTML gigantesques. Les plateformes de contenu généré par utilisateurs avec des fils de discussion infinis non paginés.
Dans ces configurations, tu peux facilement dépasser 15 Mo de contenu rendu sans t'en rendre compte. Et si ton contenu stratégique arrive en fin de page, il risque de passer à la trappe.
Impact pratique et recommandations
Que faut-il faire concrètement pour éviter ce plafond ?
Première étape : auditer le poids de vos pages critiques. Utilisez les DevTools Chrome (onglet Network) pour mesurer la taille des fichiers HTML, JS et CSS téléchargés. Attention, vérifiez bien la taille décompressée, pas celle affichée en Gzip.
Deuxième action : tester le rendu Googlebot via l'outil d'inspection d'URL dans la Search Console. Comparez le HTML source et le HTML rendu : si vous constatez des tronquages ou du contenu manquant, vous avez peut-être un problème de limite.
Quelles erreurs éviter absolument ?
Ne chargez pas l'intégralité de votre catalogue produit dans une seule page HTML. Évitez les bundles JavaScript monolithiques : splittez votre code en chunks plus petits, chargés à la demande (code splitting, lazy loading).
Ne générez pas de pages infinies avec du contenu dupliqué ou non essentiel injecté en HTML brut. Privilégiez la pagination propre ou le scroll infini avec chargement AJAX progressif — mais attention, dans ce cas, assurez-vous que Googlebot peut accéder aux pages suivantes via des liens crawlables.
Comment vérifier que mon site respecte cette contrainte ?
- Mesurez la taille décompressée de vos pages HTML principales (DevTools > Network > Size)
- Auditez vos bundles JavaScript : identifiez les fichiers de plus de 10 Mo et splittez-les
- Testez vos URLs stratégiques avec l'outil d'inspection d'URL de la Search Console
- Comparez le HTML source et le HTML rendu : tout le contenu est-il présent après rendu ?
- Mettez en place une pagination claire pour les pages à contenu volumétrique (catalogues, listes, forums)
- Activez la compression Gzip ou Brotli côté serveur pour alléger la transmission (même si Googlebot décompresse ensuite)
- Surveillez vos Core Web Vitals : des fichiers lourds impactent aussi LCP et TBT
La limite de 15 Mo par URL concerne surtout les sites avec des pages très volumineuses ou des architectures JavaScript lourdes. Pour la majorité des sites, cette contrainte reste théorique. Mais pour les plateformes e-commerce complexes, les SPA ou les sites de contenu généré massivement, c'est un point de vigilance réel.
Optimiser le poids des pages, splitter le code JavaScript et tester régulièrement le rendu Googlebot sont des réflexes essentiels. Ces optimisations demandent une expertise technique pointue et une connaissance fine des mécanismes de crawl. Si votre architecture est complexe ou que vous constatez des anomalies d'indexation inexpliquées, faire appel à une agence SEO spécialisée peut s'avérer judicieux pour diagnostiquer précisément les problèmes et mettre en place des solutions sur mesure.
❓ Questions frequentes
Est-ce que la compression Gzip réduit la limite de 15 Mo ?
Si mon HTML fait 5 Mo et mon JavaScript 18 Mo, que se passe-t-il ?
Cette limite s'applique-t-elle au contenu rendu après exécution JavaScript ?
Comment vérifier si mes pages dépassent cette limite ?
Un site WordPress classique risque-t-il de dépasser 15 Mo par page ?
🎥 De la même vidéo 43
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 30/03/2026
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.