Declaration officielle
Autres déclarations de cette vidéo 43 ▾
- □ Pourquoi Googlebot s'arrête-t-il à 15 Mo par URL et comment cela impacte-t-il votre crawl ?
- □ Google mesure-t-il vraiment le poids de page comme vous le pensez ?
- □ Le poids des pages mobiles a triplé en 10 ans : faut-il s'inquiéter pour le SEO ?
- □ Les données structurées alourdissent-elles trop vos pages pour être rentables en SEO ?
- □ Votre site mobile contient-il autant de contenu que votre version desktop ?
- □ Pourquoi votre contenu desktop disparaît-il des résultats Google s'il manque sur mobile ?
- □ La vitesse de page impacte-t-elle réellement les conversions selon Google ?
- □ Google traite-t-il vraiment 40 milliards d'URLs de spam par jour ?
- □ La compression réseau améliore-t-elle réellement le crawl budget de votre site ?
- □ Le lazy loading est-il vraiment indispensable pour optimiser le poids initial de vos pages ?
- □ Googlebot s'arrête-t-il vraiment après 15 Mo par URL ?
- □ Pourquoi le poids des pages mobiles a-t-il triplé en une décennie ?
- □ Le poids des pages impacte-t-il vraiment l'expérience utilisateur et le SEO ?
- □ Les données structurées alourdissent-elles vraiment vos pages HTML ?
- □ Pourquoi la parité mobile-desktop reste-t-elle un facteur de déclassement majeur ?
- □ Faut-il encore se préoccuper du poids des pages pour le SEO ?
- □ La taille des ressources est-elle le facteur déterminant de la vitesse de votre site ?
- □ Pourquoi Google impose-t-il une limite stricte de 1 Mo pour les images ?
- □ L'optimisation de la taille des pages profite-t-elle vraiment plus aux utilisateurs qu'au SEO ?
- □ Googlebot limite-t-il vraiment le crawl à 15 Mo par URL ?
- □ Le poids des pages web explose : faut-il s'inquiéter pour son SEO ?
- □ La taille des pages web nuit-elle encore vraiment à votre SEO ?
- □ Les structured data alourdissent-elles vos pages au point de nuire au SEO ?
- □ La vitesse de chargement influence-t-elle vraiment les conversions de vos pages ?
- □ La compression réseau suffit-elle à optimiser l'espace de stockage des utilisateurs ?
- □ Pourquoi la disparité mobile/desktop tue-t-elle votre référencement en indexation mobile-first ?
- □ Le lazy loading est-il vraiment un levier de performance SEO à activer systématiquement ?
- □ Google bloque 40 milliards d'URLs de spam par jour : comment votre site échappe-t-il au filtre ?
- □ L'optimisation des images peut-elle vraiment diviser par 10 le poids de vos pages ?
- □ Googlebot s'arrête-t-il vraiment à 15 Mo par URL ?
- □ Pourquoi la parité mobile-desktop impacte-t-elle autant votre classement en Mobile-First Indexing ?
- □ Le poids de vos pages freine-t-il vraiment votre référencement ?
- □ Les données structurées ralentissent-elles vraiment votre crawl ?
- □ Faut-il limiter vos images à 1 Mo pour plaire à Google ?
- □ Googlebot s'arrête-t-il vraiment à 15 Mo par URL crawlée ?
- □ La vitesse d'un site impacte-t-elle vraiment la conversion ?
- □ Pourquoi la disparité mobile-desktop ruine-t-elle encore tant de classements SEO ?
- □ Les données structurées alourdissent-elles vraiment vos pages HTML ?
- □ Pourquoi la taille des pages reste-t-elle un facteur SEO critique malgré l'amélioration des connexions Internet ?
- □ La compression réseau suffit-elle à optimiser le crawl de votre site ?
- □ Le lazy loading peut-il vraiment booster vos performances sans impacter le crawl ?
- □ La taille d'un site web a-t-elle vraiment un impact sur son référencement ?
- □ Pourquoi Google limite-t-il la taille des images à 1Mo sur sa documentation développeur ?
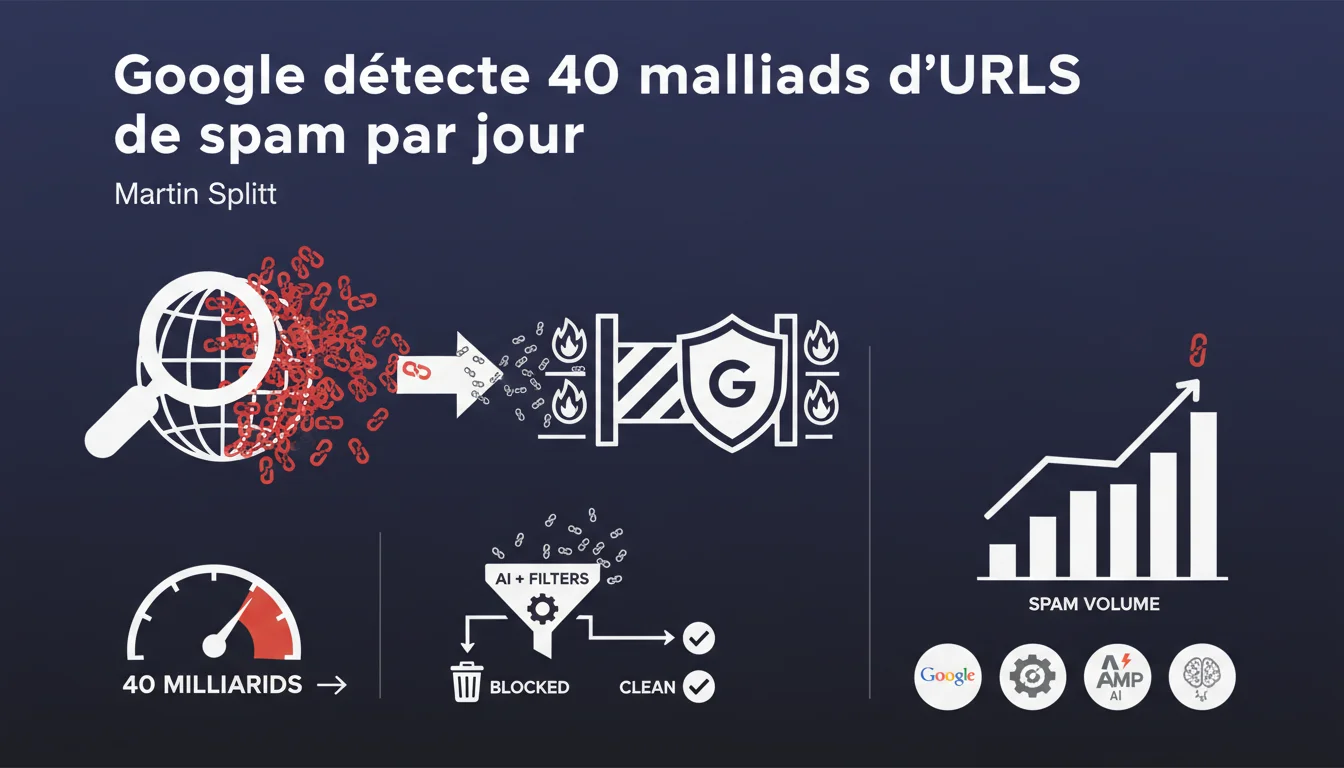
Google bloque 40 milliards d'URLs de spam quotidiennement, un chiffre qui illustre l'échelle industrielle du spam web. Cette déclaration de Martin Splitt confirme que la détection spam est désormais largement automatisée et que les filtres Google fonctionnent en amont de l'indexation. Pour les sites légitimes, cela signifie qu'une mauvaise configuration ou des signaux ambigus peuvent vous faire basculer du mauvais côté de cette barrière.
Ce qu'il faut comprendre
Que signifie concrètement ce chiffre de 40 milliards ?
Ce volume colossal représente les URLs détectées et bloquées avant même qu'elles n'atteignent l'index. On parle ici d'une détection en temps réel, probablement au niveau du crawl ou juste avant l'indexation.
Google ne précise pas si ces 40 milliards incluent les duplicatas d'une même campagne spam ou si ce sont des URLs uniques. La nuance compte — un réseau de sites scrappés peut générer des millions de variantes d'une même page.
Comment Google filtre-t-il ce spam à cette échelle ?
Impossible de traiter ce volume manuellement. Google s'appuie sur des modèles d'apprentissage automatique entraînés à reconnaître les patterns spam : domaines jetables, contenus dupliqués massivement, schémas de liens artificiels, comportements de crawl suspects.
La détection intervient probablement à plusieurs niveaux : lors de la découverte d'URLs (via liens, sitemaps), pendant le crawl (analyse des réponses serveur), et au moment de l'indexation (analyse du contenu et des signaux).
Pourquoi cette déclaration maintenant ?
Martin Splitt cherche à montrer que Google gère le problème — une manière de rassurer face à la montée du spam IA généré en masse. Mais c'est aussi un message indirect aux SEO : si vos pratiques ressemblent de trop près à du spam, vous risquez d'être pris dans le filet.
- 40 milliards d'URLs bloquées par jour = détection automatisée quasi-totale
- Le filtrage intervient avant l'indexation, pas après
- Les signaux spam sont détectés par machine learning, pas par humains
- Un site légitime mal configuré peut déclencher ces filtres
- La frontière entre optimisation agressive et spam devient plus floue pour les algorithmes
Avis d'un expert SEO
Ce chiffre est-il crédible au regard du volume total du web ?
Soyons honnêtes — 40 milliards par jour, ça paraît énorme. Mais quand on connaît l'écosystème du spam industriel (fermes de contenu auto-générées, réseaux de PBN, scraping massif, doorway pages), ce n'est pas délirant. [À vérifier] : Google ne précise pas la méthodologie — s'agit-il d'URLs découvertes ou d'URLs crawlées ?
Ce qui m'interpelle davantage, c'est le silence sur les faux positifs. À cette échelle, même un taux d'erreur de 0,1% représente 40 millions d'URLs légitimes bloquées par jour. Google ne dit rien là-dessus.
Les sites légitimes sont-ils à l'abri de ces filtres ?
Absolument pas. J'ai vu des sites e-commerce avec des milliers de pages filtrées par paramètres d'URL mal gérés, des blogs WordPress générant du bruit via des archives mal configurées, des sites multilingues créant involontairement du duplicate.
Le problème — et Google ne le dit pas franchement — c'est que ces filtres ne font pas toujours la différence entre un site mal foutu et un site malveillant. Si vos signaux techniques (vitesse, structure, robots.txt) ressemblent à ceux d'un scraper, vous risquez le même traitement.
Faut-il s'inquiéter si on fait du SEO agressif mais légitime ?
Ça dépend de ce qu'on entend par « agressif ». Si tu publies 100 articles IA par jour avec un maillage interne sur-optimisé et des backlinks achetés, tu te rapproches dangereusement des patterns spam détectables. Le machine learning ne juge pas l'intention — il détecte des motifs.
Impact pratique et recommandations
Comment vérifier que mon site n'est pas pris dans ces filtres ?
Première étape : compare le nombre d'URLs crawlées (Search Console, logs serveur) au nombre d'URLs indexées. Un écart important peut signaler un problème. Utilise la commande site: pour vérifier l'indexation réelle, pas juste ce que dit la GSC.
Ensuite, analyse tes logs serveur. Si Googlebot découvre des milliers d'URLs mais n'en indexe qu'une fraction, et que ces URLs ne sont pas bloquées par robots.txt ou noindex, tu es probablement filtré.
Quelles erreurs techniques peuvent déclencher un signalement spam ?
Les paramètres d'URL mal gérés sont un classique : ?sort=, ?page=, ?sessionid= génèrent des variantes infinies. Google peut interpréter ça comme du doorway spam. Même chose pour le duplicate content massif : pagination mal configurée, versions AMP/mobile/desktop non canonicalisées, contenus syndiqués sans balise rel=canonical.
Les sites qui génèrent du contenu automatisé — même légitime (fiches produits, agrégateurs) — doivent absolument différencier leur output d'un scraper. Ça passe par des signaux qualitatifs : temps de chargement, engagement utilisateur, liens internes cohérents.
Que faire si mon site subit une chute d'indexation brutale ?
Creuse tes logs de crawl pour identifier les URLs qui ne passent plus. Vérifie le comportement de Googlebot : crawle-t-il toujours ces pages, ou les ignore-t-il complètement ? Si elles sont crawlées mais non indexées, c'est probablement un filtre qualité ou spam.
Ensuite, audite tes signaux techniques : temps de réponse serveur, taux d'erreur 4xx/5xx, redirections en chaîne, duplicate content. Corrige le plus évident en priorité. Si rien ne bouge après 4-6 semaines, c'est peut-être un filtre manuel — à ce stade, la Search Console devrait te notifier.
- Monitorer l'écart entre URLs crawlées et URLs indexées chaque semaine
- Analyser les logs serveur pour détecter les URLs ignorées par Googlebot
- Nettoyer les paramètres d'URL inutiles via robots.txt ou URL Parameters Tool
- Canonicaliser systématiquement les contenus dupliqués ou similaires
- Vérifier que le contenu auto-généré apporte une valeur ajoutée réelle
- Surveiller les Core Web Vitals et les signaux d'engagement utilisateur
- Tester la différenciation entre pages pour éviter le thin content détecté comme spam
❓ Questions frequentes
Ces 40 milliards d'URLs bloquées incluent-elles les pages en noindex ou robots.txt ?
Un site légitime peut-il être bloqué par erreur dans ces filtres ?
Comment savoir si mon site est touché par un filtre spam ?
Google communique-t-il quand il détecte un site comme spam ?
Le spam IA généré en masse est-il comptabilisé dans ces 40 milliards ?
🎥 De la même vidéo 43
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 30/03/2026
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.