Official statement
Other statements from this video 43 ▾
- □ Pourquoi Googlebot s'arrête-t-il à 15 Mo par URL et comment cela impacte-t-il votre crawl ?
- □ Google mesure-t-il vraiment le poids de page comme vous le pensez ?
- □ Le poids des pages mobiles a triplé en 10 ans : faut-il s'inquiéter pour le SEO ?
- □ Les données structurées alourdissent-elles trop vos pages pour être rentables en SEO ?
- □ Votre site mobile contient-il autant de contenu que votre version desktop ?
- □ Pourquoi votre contenu desktop disparaît-il des résultats Google s'il manque sur mobile ?
- □ La vitesse de page impacte-t-elle réellement les conversions selon Google ?
- □ Google traite-t-il vraiment 40 milliards d'URLs de spam par jour ?
- □ La compression réseau améliore-t-elle réellement le crawl budget de votre site ?
- □ Le lazy loading est-il vraiment indispensable pour optimiser le poids initial de vos pages ?
- □ Pourquoi le poids des pages mobiles a-t-il triplé en une décennie ?
- □ Le poids des pages impacte-t-il vraiment l'expérience utilisateur et le SEO ?
- □ Les données structurées alourdissent-elles vraiment vos pages HTML ?
- □ Pourquoi la parité mobile-desktop reste-t-elle un facteur de déclassement majeur ?
- □ Faut-il encore se préoccuper du poids des pages pour le SEO ?
- □ La taille des ressources est-elle le facteur déterminant de la vitesse de votre site ?
- □ Pourquoi Google impose-t-il une limite stricte de 1 Mo pour les images ?
- □ L'optimisation de la taille des pages profite-t-elle vraiment plus aux utilisateurs qu'au SEO ?
- □ Googlebot limite-t-il vraiment le crawl à 15 Mo par URL ?
- □ Le poids des pages web explose : faut-il s'inquiéter pour son SEO ?
- □ La taille des pages web nuit-elle encore vraiment à votre SEO ?
- □ Les structured data alourdissent-elles vos pages au point de nuire au SEO ?
- □ La vitesse de chargement influence-t-elle vraiment les conversions de vos pages ?
- □ La compression réseau suffit-elle à optimiser l'espace de stockage des utilisateurs ?
- □ Pourquoi la disparité mobile/desktop tue-t-elle votre référencement en indexation mobile-first ?
- □ Le lazy loading est-il vraiment un levier de performance SEO à activer systématiquement ?
- □ Google bloque 40 milliards d'URLs de spam par jour : comment votre site échappe-t-il au filtre ?
- □ L'optimisation des images peut-elle vraiment diviser par 10 le poids de vos pages ?
- □ Googlebot s'arrête-t-il vraiment à 15 Mo par URL ?
- □ Pourquoi la parité mobile-desktop impacte-t-elle autant votre classement en Mobile-First Indexing ?
- □ Le poids de vos pages freine-t-il vraiment votre référencement ?
- □ Les données structurées ralentissent-elles vraiment votre crawl ?
- □ Google intercepte vraiment 40 milliards d'URLs de spam par jour ?
- □ Faut-il limiter vos images à 1 Mo pour plaire à Google ?
- □ Googlebot s'arrête-t-il vraiment à 15 Mo par URL crawlée ?
- □ La vitesse d'un site impacte-t-elle vraiment la conversion ?
- □ Pourquoi la disparité mobile-desktop ruine-t-elle encore tant de classements SEO ?
- □ Les données structurées alourdissent-elles vraiment vos pages HTML ?
- □ Pourquoi la taille des pages reste-t-elle un facteur SEO critique malgré l'amélioration des connexions Internet ?
- □ La compression réseau suffit-elle à optimiser le crawl de votre site ?
- □ Le lazy loading peut-il vraiment booster vos performances sans impacter le crawl ?
- □ La taille d'un site web a-t-elle vraiment un impact sur son référencement ?
- □ Pourquoi Google limite-t-il la taille des images à 1Mo sur sa documentation développeur ?
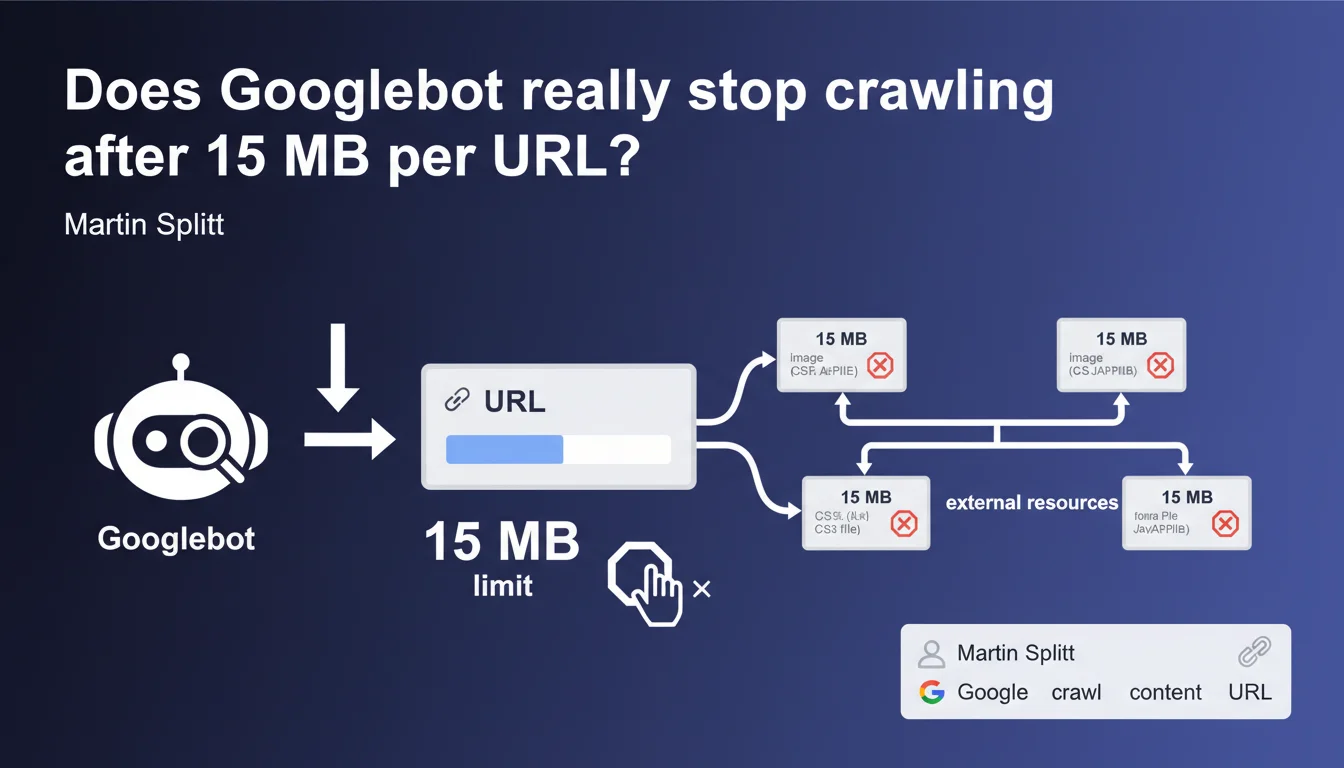
Googlebot enforces a strict 15 MB raw content limit per crawled URL. Beyond this threshold, the bot halts retrieval. This rule applies individually to each resource: HTML, CSS, JS, and images each have their own quota. Sites with large pages or heavy resources risk partial indexation.
What you need to understand
What exactly does this 15 MB limit mean?
The limit applies to raw uncompressed content fetched by Googlebot. When the bot downloads your HTML, CSS, JavaScript, or any other resource, it counts the bytes received. At 15 MB, it cuts the connection and moves on.
Critical point: each URL has its own counter. If your HTML page is 2 MB and references an 18 MB JavaScript file, the HTML will be fully crawled, but the JS will be truncated at 15 MB. The two budgets are separate.
Why does Google enforce this constraint?
Crawling is expensive in terms of resources — bandwidth, storage, and processing time. Google crawls billions of pages every day. Without strict limits, a poorly optimized site could monopolize disproportionate resources.
This rule also protects crawled sites: a bot downloading infinitely large files could overwhelm servers. The 15 MB limit remains generous for the majority of standard web pages.
Does this limit affect all types of content?
Yes, all resource types are affected: HTML, CSS, JavaScript, images, PDFs, videos. Each URL has its own 15 MB ceiling.
A frequent case: dynamically generated infinite pages. If your HTML continues loading content via infinite scroll without clear pagination, Googlebot may hit the limit before retrieving everything. Result: partial indexation.
- 15 MB per URL, not per entire page
- Applies to raw uncompressed content
- Each resource (HTML, CSS, JS, images) has its own quota
- Beyond that, Googlebot immediately stops downloading
- No carryover or cumulative counting between resources
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes, and it confirms what many practitioners have suspected. Testing shows that Googlebot does indeed truncate oversized pages. HTML exceeding 15 MB sees its content cut off — often in the middle of a tag or paragraph.
The problem is that Google doesn't send explicit alerts in Search Console when this limit is reached. You discover the issue indirectly: unindexed content, missing sections in snippets, or incomplete crawl detected through logs. [To verify]: no official KPI directly reports this metric.
Which sites are truly affected by this limit?
Let's be honest: the majority of sites will never hit 15 MB per URL. A standard HTML page, even content-rich, rarely exceeds 500 KB to 2 MB. The real cases affected are edge cases.
E-commerce sites with endless listings injected as raw HTML, single-page applications (SPAs) loading all content at once, pages with thousands of lines of embedded JSON-LD, or news sites with infinite feeds. And that's where it gets tricky: these structures are often created without crawl considerations.
Could Google increase this limit?
Technically, yes. But the challenge isn't technical — it's economic and strategic. Google crawls efficiently by rationing resources. Universally increasing the limit would multiply costs without proportional benefit.
What's missing from this statement is any nuance on exceptions. Are there priority sites that benefit from higher limits? Google doesn't say. [To verify]: no public data confirms or denies the existence of variable quotas based on the site.
Practical impact and recommendations
How do you verify if your site exceeds the limit?
First step: analyze the size of your URLs. Use Chrome DevTools (Network tab) to measure uncompressed resource size. Watch out — the displayed "transferred" size is often compressed. Look at the "size" or "content length" column.
On the server side, examine your logs carefully. Search for Googlebot requests interrupted abruptly or HTTP 206 codes (partial content). If Googlebot cuts the connection before download completion, that's a red flag.
- Measure the raw uncompressed size of each URL with DevTools
- List HTML pages exceeding 5 MB — these are at-risk candidates
- Identify large third-party JS/CSS resources (> 10 MB)
- Analyze server logs to detect incomplete crawls
- Test actual indexation with targeted
site:searches on content near the end of pages
What corrective actions should you implement?
If your pages exceed or approach the limit, refactor the structure. Paginate long listings instead of loading everything at once. Externalize bulky data (massive JSON-LD, for example) into separate files if they're not critical for indexation.
For JavaScript, split your bundles. A monolithic 20 MB JS file is a problem. Code splitting, lazy loading, dynamic imports: all these techniques reduce initial weight. Googlebot will render better with lightweight, modular resources.
Should you rethink your technical architecture?
In some cases, yes. Poorly designed SPAs often generate a skeletal HTML, then inject everything via JS. If this JS exceeds 15 MB, Googlebot sees only an empty shell — or worse, randomly truncated content.
Server-Side Rendering (SSR) or Static Site Generation (SSG) become strategic allies. You deliver pre-rendered, lightweight HTML, avoiding dependency on massive JS resources. It's a technical undertaking, but the SEO impact is direct.
In practice: audit your oversized URLs, paginate or split heavy content, optimize your JS/CSS bundles, and monitor crawl logs. If your pages approach the limit, indexation is compromised.
These optimizations often involve front-end and back-end architecture changes. When technical challenges become complex — template refactoring, advanced code splitting, SSR — partnering with a specialized SEO agency can accelerate compliance while securing strategic choices. Precise technical diagnosis prevents costly mistakes.
❓ Frequently Asked Questions
La compression HTTP affecte-t-elle la limite de 15 Mo ?
Google me prévient-il si une URL dépasse la limite ?
Les images et vidéos comptent-elles dans les 15 Mo ?
Le lazy loading résout-il le problème pour les pages longues ?
Peut-on demander une exception à Google pour des sites spécifiques ?
🎥 From the same video 43
Other SEO insights extracted from this same Google Search Central video · published on 30/03/2026
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.