Official statement
Other statements from this video 43 ▾
- □ Pourquoi Googlebot s'arrête-t-il à 15 Mo par URL et comment cela impacte-t-il votre crawl ?
- □ Google mesure-t-il vraiment le poids de page comme vous le pensez ?
- □ Le poids des pages mobiles a triplé en 10 ans : faut-il s'inquiéter pour le SEO ?
- □ Les données structurées alourdissent-elles trop vos pages pour être rentables en SEO ?
- □ Votre site mobile contient-il autant de contenu que votre version desktop ?
- □ Pourquoi votre contenu desktop disparaît-il des résultats Google s'il manque sur mobile ?
- □ La vitesse de page impacte-t-elle réellement les conversions selon Google ?
- □ Google traite-t-il vraiment 40 milliards d'URLs de spam par jour ?
- □ La compression réseau améliore-t-elle réellement le crawl budget de votre site ?
- □ Le lazy loading est-il vraiment indispensable pour optimiser le poids initial de vos pages ?
- □ Googlebot s'arrête-t-il vraiment après 15 Mo par URL ?
- □ Pourquoi le poids des pages mobiles a-t-il triplé en une décennie ?
- □ Le poids des pages impacte-t-il vraiment l'expérience utilisateur et le SEO ?
- □ Les données structurées alourdissent-elles vraiment vos pages HTML ?
- □ Pourquoi la parité mobile-desktop reste-t-elle un facteur de déclassement majeur ?
- □ Faut-il encore se préoccuper du poids des pages pour le SEO ?
- □ La taille des ressources est-elle le facteur déterminant de la vitesse de votre site ?
- □ Pourquoi Google impose-t-il une limite stricte de 1 Mo pour les images ?
- □ L'optimisation de la taille des pages profite-t-elle vraiment plus aux utilisateurs qu'au SEO ?
- □ Googlebot limite-t-il vraiment le crawl à 15 Mo par URL ?
- □ Le poids des pages web explose : faut-il s'inquiéter pour son SEO ?
- □ La taille des pages web nuit-elle encore vraiment à votre SEO ?
- □ Les structured data alourdissent-elles vos pages au point de nuire au SEO ?
- □ La vitesse de chargement influence-t-elle vraiment les conversions de vos pages ?
- □ La compression réseau suffit-elle à optimiser l'espace de stockage des utilisateurs ?
- □ Pourquoi la disparité mobile/desktop tue-t-elle votre référencement en indexation mobile-first ?
- □ Le lazy loading est-il vraiment un levier de performance SEO à activer systématiquement ?
- □ Google bloque 40 milliards d'URLs de spam par jour : comment votre site échappe-t-il au filtre ?
- □ L'optimisation des images peut-elle vraiment diviser par 10 le poids de vos pages ?
- □ Pourquoi la parité mobile-desktop impacte-t-elle autant votre classement en Mobile-First Indexing ?
- □ Le poids de vos pages freine-t-il vraiment votre référencement ?
- □ Les données structurées ralentissent-elles vraiment votre crawl ?
- □ Google intercepte vraiment 40 milliards d'URLs de spam par jour ?
- □ Faut-il limiter vos images à 1 Mo pour plaire à Google ?
- □ Googlebot s'arrête-t-il vraiment à 15 Mo par URL crawlée ?
- □ La vitesse d'un site impacte-t-elle vraiment la conversion ?
- □ Pourquoi la disparité mobile-desktop ruine-t-elle encore tant de classements SEO ?
- □ Les données structurées alourdissent-elles vraiment vos pages HTML ?
- □ Pourquoi la taille des pages reste-t-elle un facteur SEO critique malgré l'amélioration des connexions Internet ?
- □ La compression réseau suffit-elle à optimiser le crawl de votre site ?
- □ Le lazy loading peut-il vraiment booster vos performances sans impacter le crawl ?
- □ La taille d'un site web a-t-elle vraiment un impact sur son référencement ?
- □ Pourquoi Google limite-t-il la taille des images à 1Mo sur sa documentation développeur ?
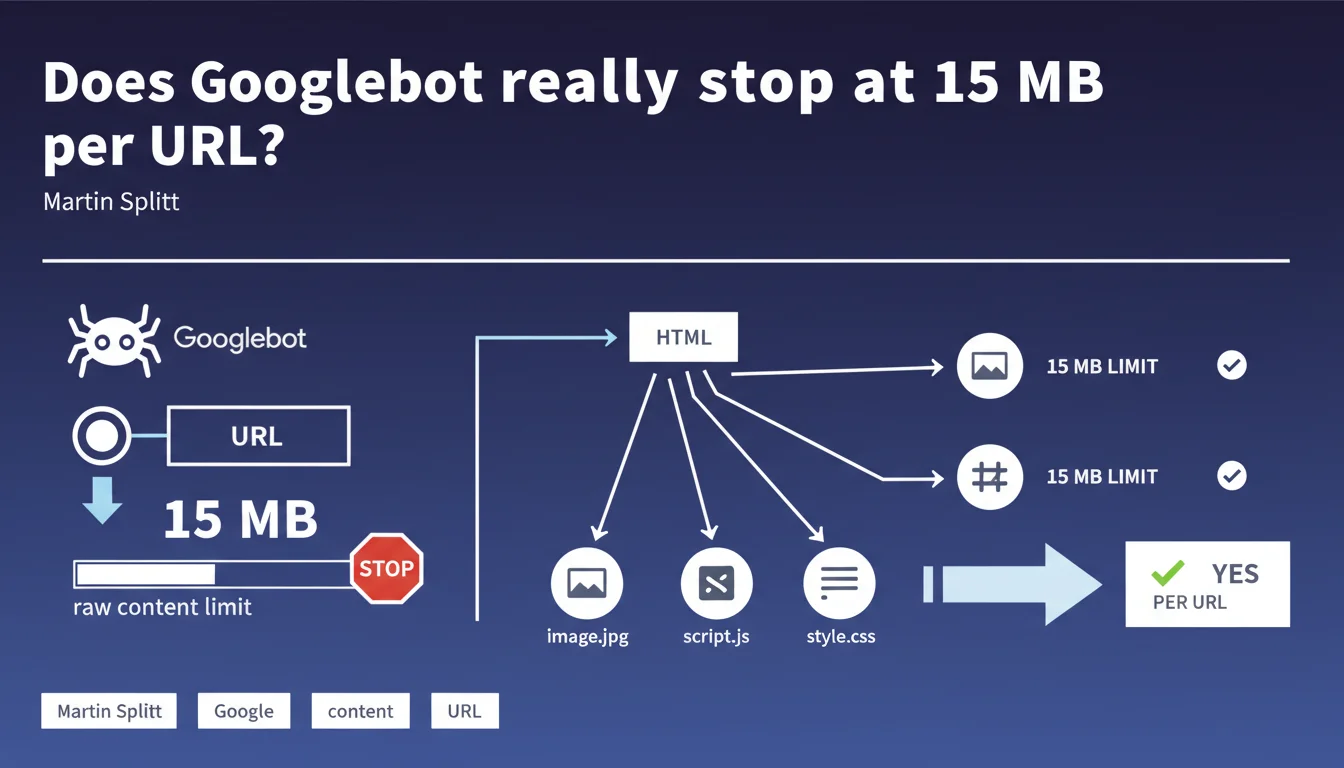
Googlebot crawls up to 15 megabytes of raw content per URL by default before stopping. Each referenced resource (CSS, JS, images) has its own 15 MB limit. This technical constraint directly impacts the indexation of large or content-rich pages.
What you need to understand
What exactly is this 15 MB limit?
Google sets a crawl limit of 15 megabytes for each crawled URL. In concrete terms, Googlebot downloads the raw content of a page until it reaches this threshold, then stops downloading abruptly.
This limit applies to the main HTML document only. External resources — CSS, JavaScript, images, videos — referenced in this HTML each benefit from their own 15 MB quota. In other words, a 10 MB HTML page that loads a 12 MB script and an 8 MB stylesheet passes without issue.
Why does Google impose this constraint?
The reason is simple: protecting crawl infrastructure. Google processes billions of URLs daily. Without safeguards, a poorly configured site could send documents of several hundred megabytes, saturating the crawler's resources.
This limit also prevents abuse — intentional or not. Endlessly generated dynamic pages, oversized JSON feeds, log files exposed by mistake: as many cases that would exceed crawl budget without adding value.
What happens if my page exceeds 15 MB?
Googlebot cuts off the retrieval at exactly 15 MB. Content beyond this threshold is never seen or indexed. If your crucial text appears after 16 MB of HTML, it will remain invisible to Google.
No alert is sent to Search Console. No notification, no warning. The crawl stops silently, and you discover the problem when your pages don't rank or display truncated snippets.
- Limit of 15 MB per URL, applied to raw content (HTML, JSON, XML...)
- Each referenced resource (CSS, JS, images) has its own 15 MB limit
- Content beyond 15 MB is never crawled or indexed
- No warning in Search Console in case of exceeding the limit
- This rule aims to protect Google's infrastructure and prevent abuse
SEO Expert opinion
Does this 15 MB limit pose a problem in practice?
Let's be honest: the majority of websites don't even come close to this threshold. A typical HTML page weighs between 50 KB and 500 KB. Even a long-form article with embedded rich media rarely exceeds 2-3 MB of pure HTML.
Where does it get tricky? E-commerce sites with oversized product listings loaded on a single page, SaaS platforms that inject massive JSON datasets into the DOM, or news sites that stack dozens of articles on the same URL with infinite scroll. In these cases, 15 MB can disappear quickly.
Is Google transparent about what counts toward these 15 MB?
Martin Splitt mentions "raw content," which includes uncompressed HTML. But what about inline JavaScript? JSON data embedded in <script> tags? SVGs integrated directly into the markup?
[To verify] Google doesn't specify whether HTTP compression (gzip, Brotli) is accounted for before or after this limit. If Googlebot decompresses first, a 3 MB compressed HTML could weigh 12 MB raw and approach the limit. No official data on this.
Should you actively monitor this metric?
Yes, especially if you operate in verticals with high content volume. E-commerce, price comparison sites, directories, job boards: so many sectors where pages easily balloon.
The problem? No Google tool exists to monitor this threshold. You must manually measure the HTML size returned for your main templates. A simple curl -I with Content-Length isn't always enough — some servers don't return this header or serve compressed content.
Practical impact and recommendations
How do you verify if your pages exceed the limit?
Start by identifying your at-risk templates: category pages, listings, archives, internal search results pages. These are the ones that accumulate the most content.
Then, measure the actual size of the returned HTML. Use curl -s https://yoursite.com/page | wc -c to get the size in bytes of the raw content. If you exceed 10-12 MB, you're in dangerous territory.
What optimizations should you implement if you exceed the limit?
First approach: pagination or lazy loading. Instead of loading 500 products on a single page, split into pages of 50 products. Or implement infinite scroll that loads content via AJAX after initial render.
Second lever: clean up superfluous HTML. Debug comments, unnecessary whitespace, redundant JSON-LD, oversized data-* attributes... all of this adds weight. Minify and compress aggressively.
Finally, if you embed JSON datasets for your React/Vue apps, externalize them. Rather than inlining them in the HTML, load them via a dedicated endpoint. This lightens the main document and respects the per-resource limit.
What if you can't reduce the size?
If your content is legitimate and can't be split — for example, exhaustive technical documentation on a single page — you'll have to accept that Google only crawls part of it. In this case, ensure your crucial content appears within the first 10 MB.
Alternatively, restructure your architecture so each major section is a distinct URL. This also improves your internal linking and the granularity of your indexation.
- Audit templates with high content volume (categories, listings, archives)
- Measure actual HTML size with
curlor monitoring tools - Implement pagination or lazy loading for lengthy content
- Clean up HTML: minification, comment removal, data attribute optimization
- Externalize large JSON datasets instead of inlining them in HTML
- Prioritize important content in the first megabytes of the document
- Regularly monitor page size after each deployment
❓ Frequently Asked Questions
Les 15 Mo incluent-ils le contenu compressé ou décompressé ?
Si mon HTML fait 14 Mo et charge un CSS de 20 Mo, que se passe-t-il ?
Puis-je voir dans Search Console si mes pages dépassent 15 Mo ?
Le contenu chargé en JavaScript après le rendu initial compte-t-il dans ces 15 Mo ?
Cette limite a-t-elle toujours existé ou est-ce une nouveauté ?
🎥 From the same video 43
Other SEO insights extracted from this same Google Search Central video · published on 30/03/2026
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.