Official statement
Other statements from this video 23 ▾
- □ Does Google really count every single visible link pointing to your site in Search Console?
- □ Should you really concentrate your content on fewer pages to rank better?
- □ Do Google's product review criteria apply even if your site isn't classified as a review site?
- □ Does Google's Indexing API really work for all types of content?
- □ Does E-A-T Really Impact Google Rankings, or Is It Just a Myth?
- □ Do unlinked brand mentions really boost your SEO rankings?
- □ Do user comments really improve your Google rankings?
- □ Do premium SSL certificates really impact Google rankings?
- □ Does having the same content in both PDF and HTML formats hurt your SEO rankings through cannibalization?
- □ Can you really control PDF indexing through HTTP headers?
- □ Should you still use rel=next and rel=prev tags for pagination in 2024?
- □ Does Googlebot really index all your infinite scroll content?
- □ Should you really index every page on your website?
- □ Should you really worry about the referrer page shown in Google Search Console?
- □ Should you really redirect the old sitemap with a 301 or submit the new one directly instead?
- □ Is a 97% crawl refresh rate actually a positive sign for your website's health?
- □ Does Google really measure crawl speed and Core Web Vitals the same way — and why should you care?
- □ Does Google really slow down crawling after a hosting migration, and how long does it last?
- □ Is the crawl rate parameter really a ceiling rather than something Google will try to maximize?
- □ Can CTR really penalize the rest of your website?
- □ Is internal linking really the most critical factor for SEO success?
- □ Does internal linking really take effect instantly after Google recrawls your pages?
- □ Should you worry if Google isn't crawling all your pages?
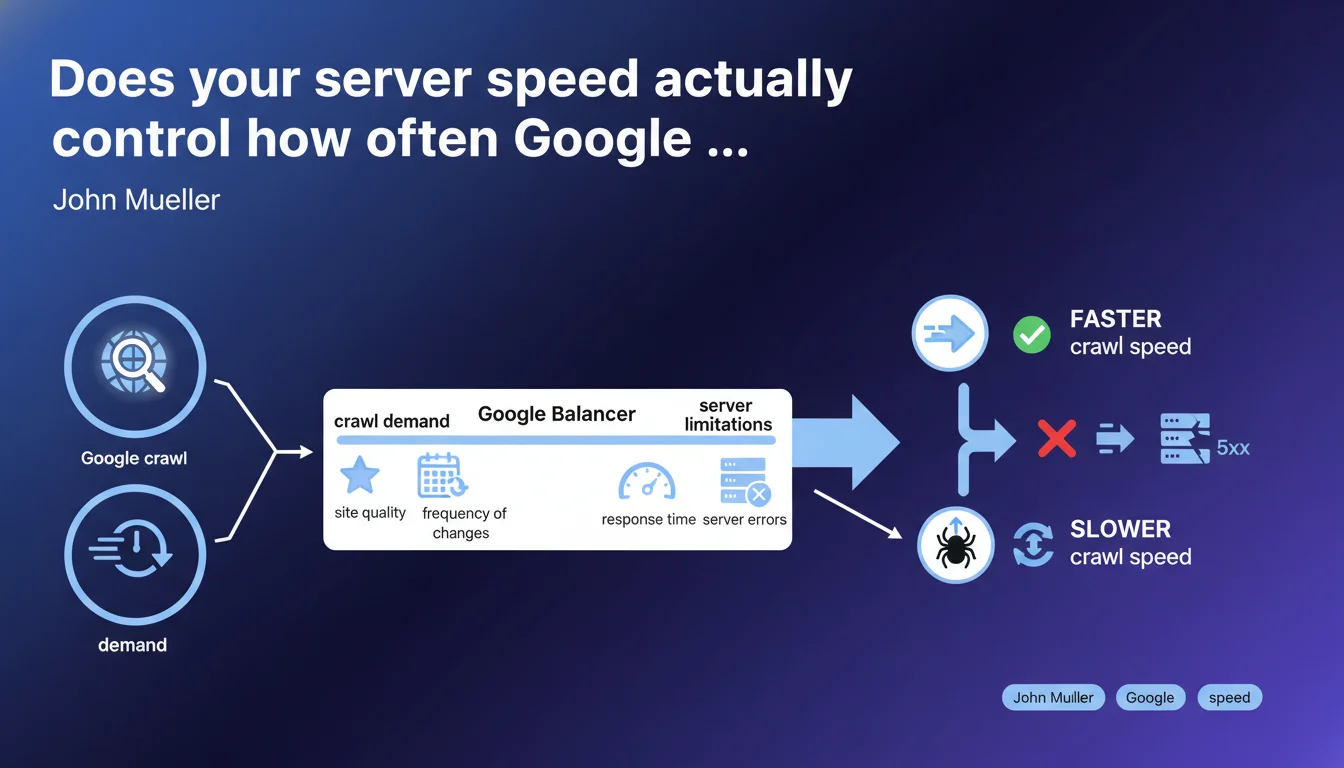
Google adjusts its crawl rate based on two parameters: demand (site quality, update frequency) and server limitations (response time, 5xx errors). In practice? A slow or unstable server directly slows down crawling, regardless of how good your content is.
What you need to understand
What does Google really mean by "crawl demand"?
The crawl demand refers to the interest Google has in your site. The more your content is deemed high-quality and updated frequently, the more often Googlebot wants to visit. It's a simple equation: a site with fresh, relevant content naturally generates more visits.
But be careful — this demand isn't a guarantee. It fluctuates based on your editorial performance and how your pages respond to user queries. A stagnant site will mechanically see its crawl frequency decline.
Why do server limitations carry so much weight?
Google doesn't want to overload your servers. If your response times increase or 5xx errors multiply, Googlebot automatically reduces its pace. This is a protective measure, both for your infrastructure and for crawl efficiency.
The signal is clear: a struggling server sends a negative message to Google. Even an editorially excellent site will be penalized if its infrastructure can't keep up.
What balance is Google trying to maintain?
Google optimizes its crawl budget — that is, the time and resources it allocates to each site. It wants to maximize the discovery of relevant content without ever jeopardizing the stability of your servers.
This balance requires constant adjustments. If your server speeds up, Google speeds up. If it slows down, Google slows down. It's a permanent technical dialogue between your infrastructure and the bots.
- The crawl rate is not fixed: it varies based on site quality and server health
- 5xx errors and slow response times are direct crawl blockers
- Google always prioritizes server stability before increasing crawl frequency
- A site with fresh, quality content naturally attracts more crawling
SEO Expert opinion
Is this statement consistent with real-world observations?
Absolutely. Every SEO professional who regularly analyzes server logs confirms this logic. When a site experiences consecutive 5xx errors or response times exceed several seconds, crawling drops — sometimes by 50% or more within days.
What's less often mentioned is that Google makes these adjustments in a granular way. A slow server on one section of a site can see that specific section slow down, while the rest continues to be crawled normally. This is visible in logs: certain site sections get neglected while others remain active.
What nuances should we add?
The term "site quality" remains deliberately vague. Google never specifies how it measures this quality to determine crawl demand. Is it based on Helpful Content? On click-through rates in SERPs? On user engagement? [Needs verification]
Similarly, "frequency of change" can be misinterpreted. Artificially modifying pages without adding real value doesn't increase crawling — quite the opposite, it can reduce it if Google detects cosmetic updates. Only substantial modifications count.
In what cases doesn't this rule fully apply?
For news sites or large e-commerce platforms, Google generally allocates a higher crawl budget by default, even if the server shows occasional signs of weakness. Tolerance is greater.
Conversely, a small site can have an ultra-fast server and decent content — but if it generates no real demand (no backlinks, no traffic, no freshness), crawling will remain low. Server performance alone isn't enough.
Practical impact and recommendations
What should you do concretely to optimize crawl?
First, monitor server response times. Use Search Console (section "Settings" > "Crawl statistics") to identify latency spikes. If TTFB regularly exceeds 500 ms, you have a problem.
Next, track 5xx errors in your server logs. A handful of sporadic errors aren't an issue, but recurring errors on the same URLs or sections send a strong negative signal. Fix them as a priority.
Finally, make sure your hosting can handle crawl spikes. Googlebot doesn't give notice before visiting — if your server saturates every time it crawls intensively, your crawl rate will be permanently throttled.
What mistakes must you absolutely avoid?
Don't artificially limit crawling via robots.txt or the "crawl-delay" parameter except in extreme cases. If your server can't handle Google's pace, that's an infrastructure problem to solve — not a reason to slow down crawling.
Also avoid creating chains of 301/302 redirects. Each redirect increases overall response time and wastes crawl budget unnecessarily. One URL, one destination — that's the rule.
How do you verify your site complies?
Analyze your server logs over at least 30 days. Identify crawled URLs, their frequency, and the HTTP codes returned. Cross-reference with Search Console data to spot inconsistencies.
Test your TTFB using tools like WebPageTest or GTmetrix. If you regularly exceed 600 ms, optimize your technical stack: server cache, CDN, database optimization, reduction of external requests.
- Monitor TTFB in Search Console and aim for under 500 ms
- Immediately fix any recurring 5xx errors
- Size your hosting to absorb crawl spikes without saturating
- Avoid redirect chains and artificial crawl-delays
- Analyze server logs monthly to identify anomalies
- Regularly publish substantial, quality content
- Optimize your technical stack: cache, CDN, database
❓ Frequently Asked Questions
Un TTFB lent impacte-t-il le référencement au-delà du crawl ?
Faut-il limiter le crawl via robots.txt si mon serveur est lent ?
Les Core Web Vitals influencent-ils le taux de crawl ?
Comment savoir si Google réduit mon crawl à cause d'erreurs serveur ?
Un CDN améliore-t-il le taux de crawl ?
🎥 From the same video 23
Other SEO insights extracted from this same Google Search Central video · published on 18/02/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.