Declaration officielle
Autres déclarations de cette vidéo 23 ▾
- □ Google compte-t-il vraiment tous les liens visibles dans Search Console ?
- □ Faut-il vraiment concentrer son contenu sur moins de pages pour ranker ?
- □ Les critères d'avis produits Google s'appliquent-ils même si votre site n'est pas classé comme site d'avis ?
- □ L'API Indexing de Google fonctionne-t-elle vraiment pour tous les contenus ?
- □ L'E-A-T influence-t-il vraiment le classement Google ou n'est-ce qu'un mythe ?
- □ Les mentions de marque sans lien ont-elles un impact sur votre référencement ?
- □ Les commentaires d'utilisateurs améliorent-ils vraiment le classement dans Google ?
- □ Les certificats SSL premium influencent-ils vraiment le référencement Google ?
- □ PDF et HTML avec le même contenu : faut-il craindre une cannibalisation dans les SERPs ?
- □ Peut-on vraiment piloter l'indexation des PDF via les headers HTTP ?
- □ Faut-il encore utiliser rel=next et rel=prev pour la pagination ?
- □ Googlebot peut-il vraiment indexer vos contenus en défilement infini ?
- □ Faut-il vraiment indexer toutes les pages de son site ?
- □ Faut-il s'inquiéter de la page référente affichée dans Google Search Console ?
- □ Faut-il vraiment rediriger l'ancien sitemap en 301 ou soumettre le nouveau directement ?
- □ Pourquoi 97% de crawl refresh est-il un signal positif pour votre site ?
- □ Vitesse de crawl et Core Web Vitals : pourquoi Google fait-il la distinction ?
- □ Pourquoi Google ralentit-il son crawl après un changement d'hébergement ?
- □ Le paramètre de taux de crawl est-il vraiment un plafond et non un objectif ?
- □ Le CTR peut-il vraiment pénaliser le reste de votre site ?
- □ Le maillage interne est-il vraiment l'élément le plus déterminant pour le SEO ?
- □ Le linking interne agit-il vraiment instantanément après recrawl ?
- □ Faut-il s'inquiéter si Google ne crawle pas toutes vos pages ?
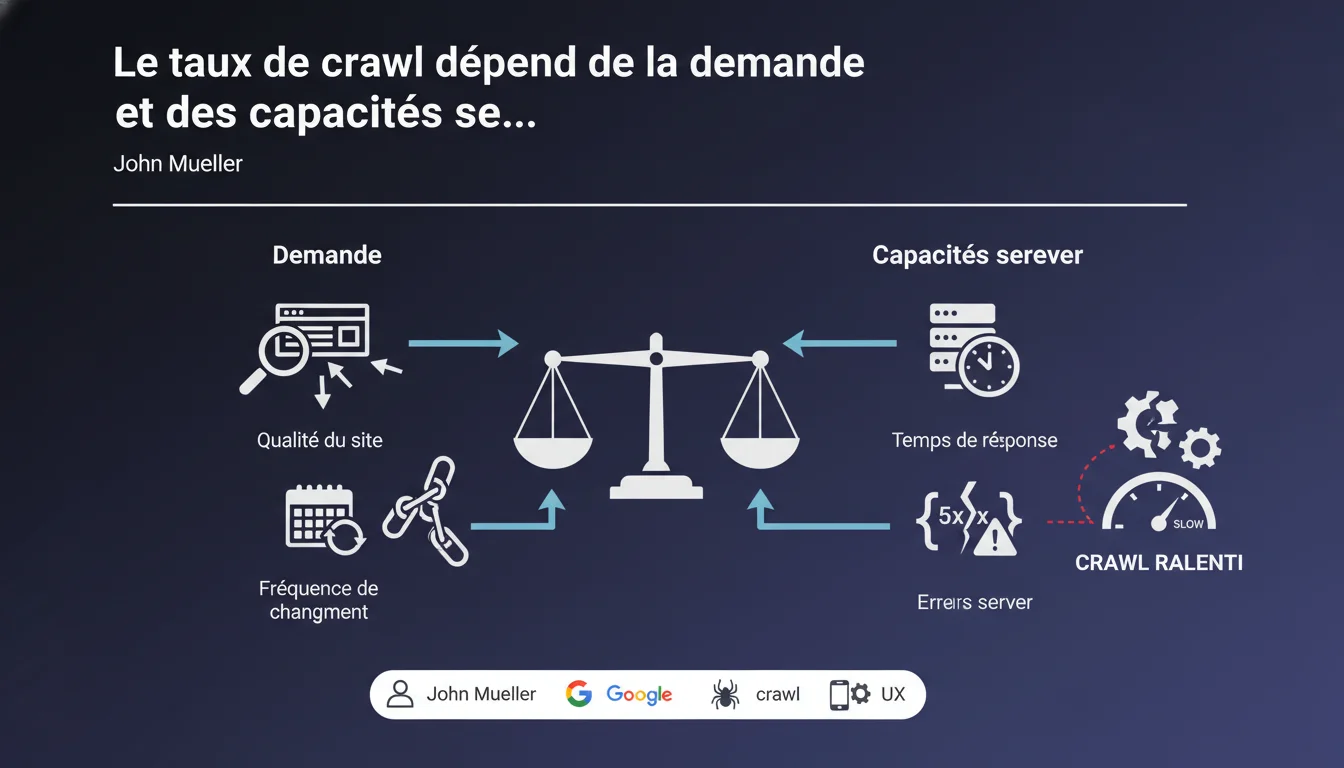
Google ajuste son taux de crawl en fonction de deux paramètres : la demande (qualité du site, fréquence des mises à jour) et les limitations serveur (temps de réponse, erreurs 5xx). Concrètement ? Un serveur lent ou instable freine directement le crawl, quelle que soit la qualité de votre contenu.
Ce qu'il faut comprendre
Qu'est-ce que Google entend par « demande de crawl » ?
La demande de crawl désigne l'intérêt que Google porte à votre site. Plus votre contenu est jugé qualitatif et mis à jour fréquemment, plus Googlebot voudra passer régulièrement. C'est une équation simple : un site avec du contenu frais et pertinent génère naturellement plus de passages.
Mais attention — cette demande n'est pas un droit acquis. Elle fluctue selon vos performances éditoriales et la réactivité de vos pages aux requêtes des utilisateurs. Un site qui stagne verra mécaniquement sa fréquence de crawl diminuer.
Pourquoi les limitations serveur pèsent-elles autant ?
Google ne veut pas surcharger vos serveurs. Si vos temps de réponse s'allongent ou si les erreurs 5xx se multiplient, Googlebot réduit automatiquement sa cadence. C'est une mesure de protection, autant pour votre infrastructure que pour l'efficacité du crawl.
Le signal est clair : un serveur qui rame envoie un message négatif à Google. Même un site excellent sur le plan éditorial sera pénalisé si son infrastructure ne suit pas.
Quel équilibre Google cherche-t-il à maintenir ?
Google optimise son crawl budget — c'est-à-dire le temps et les ressources qu'il alloue à chaque site. Il veut maximiser la découverte de contenu pertinent sans jamais mettre en péril la stabilité de vos serveurs.
Cet équilibre implique des ajustements constants. Si votre serveur accélère, Google accélère. S'il ralentit, Google ralentit. C'est un dialogue technique permanent entre votre infrastructure et les robots.
- Le taux de crawl n'est pas fixe : il varie selon la qualité du site et la santé du serveur
- Les erreurs 5xx et les temps de réponse lents sont des freins directs au crawl
- Google privilégie toujours la stabilité serveur avant d'augmenter la fréquence de passage
- Un site avec du contenu frais et qualitatif attire naturellement plus de crawl
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Totalement. Tous les professionnels SEO qui analysent régulièrement les logs serveur confirment cette logique. Quand un site enchaîne les erreurs 5xx ou que les temps de réponse dépassent plusieurs secondes, le crawl chute — parfois de 50% ou plus en quelques jours.
Ce qui est moins souvent dit, c'est que Google ajuste ce comportement de manière granulaire. Un serveur lent sur une section du site peut voir cette section spécifiquement ralentie, tandis que le reste continue d'être crawlé normalement. C'est visible dans les logs : certaines arborescences sont délaissées pendant que d'autres restent actives.
Quelles nuances faut-il apporter ?
Le terme « qualité du site » reste volontairement vague. Google ne précise jamais comment il mesure cette qualité pour déterminer la demande de crawl. Est-ce basé sur le Helpful Content ? Sur le taux de clic en SERP ? Sur l'engagement utilisateur ? [A vérifier]
De même, la « fréquence de changement » peut être mal interprétée. Modifier artificiellement des pages sans apporter de valeur réelle n'augmente pas le crawl — au contraire, cela peut le réduire si Google détecte des mises à jour cosmétiques. Seules les modifications substantielles comptent.
Dans quels cas cette règle ne s'applique-t-elle pas totalement ?
Pour les sites d'actualité ou les gros e-commerce, Google alloue généralement un crawl budget plus élevé par défaut, même si le serveur montre quelques signes de faiblesse ponctuelle. La tolérance est plus grande.
Inversement, un petit site peut avoir un serveur ultra-rapide et un contenu correct — mais s'il ne génère aucune demande réelle (pas de backlinks, pas de trafic, pas de fraîcheur), le crawl restera faible. La performance serveur seule ne suffit pas.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser le crawl ?
D'abord, monitorer les temps de réponse serveur. Utilisez Search Console (section « Paramètres » > « Statistiques de l'exploration ») pour identifier les pics de latence. Si le TTFB dépasse régulièrement 500 ms, vous avez un problème.
Ensuite, traquez les erreurs 5xx dans vos logs serveur. Une poignée d'erreurs sporadiques ne pose pas de souci, mais des erreurs récurrentes sur les mêmes URLs ou sections envoient un signal négatif fort. Corrigez-les en priorité.
Enfin, assurez-vous que votre hébergement est dimensionné pour absorber les pics de crawl. Googlebot ne prévient pas avant de passer — si votre serveur sature à chaque passage intensif, le taux de crawl sera bridé durablement.
Quelles erreurs éviter absolument ?
Ne bridez pas artificiellement le crawl via robots.txt ou le paramètre « crawl-delay » sauf cas extrêmes. Si votre serveur ne supporte pas le rythme de Google, c'est un problème d'infrastructure à résoudre — pas une raison de ralentir le crawl.
Évitez aussi de multiplier les redirections 301/302 en chaîne. Chaque redirection rallonge le temps de réponse global et consomme du crawl budget inutilement. Une URL, une destination — c'est la règle.
Comment vérifier que mon site est conforme ?
Analysez vos logs serveur sur une période de 30 jours minimum. Identifiez les URLs crawlées, leur fréquence, et les codes HTTP retournés. Croisez avec les données Search Console pour détecter les incohérences.
Testez votre TTFB via des outils comme WebPageTest ou GTmetrix. Si vous dépassez 600 ms régulièrement, optimisez votre stack technique : cache serveur, CDN, optimisation base de données, réduction des requêtes externes.
- Surveiller le TTFB dans Search Console et viser moins de 500 ms
- Corriger immédiatement toute erreur 5xx récurrente
- Dimensionner l'hébergement pour absorber les pics de crawl sans saturer
- Éviter les chaînes de redirections et les crawl-delays artificiels
- Analyser les logs serveur mensuellement pour identifier les anomalies
- Publier régulièrement du contenu substantiel et de qualité
- Optimiser la stack technique : cache, CDN, base de données
❓ Questions frequentes
Un TTFB lent impacte-t-il le référencement au-delà du crawl ?
Faut-il limiter le crawl via robots.txt si mon serveur est lent ?
Les Core Web Vitals influencent-ils le taux de crawl ?
Comment savoir si Google réduit mon crawl à cause d'erreurs serveur ?
Un CDN améliore-t-il le taux de crawl ?
🎥 De la même vidéo 23
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 18/02/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.