Declaration officielle
Autres déclarations de cette vidéo 23 ▾
- □ Google compte-t-il vraiment tous les liens visibles dans Search Console ?
- □ Faut-il vraiment concentrer son contenu sur moins de pages pour ranker ?
- □ Les critères d'avis produits Google s'appliquent-ils même si votre site n'est pas classé comme site d'avis ?
- □ L'API Indexing de Google fonctionne-t-elle vraiment pour tous les contenus ?
- □ L'E-A-T influence-t-il vraiment le classement Google ou n'est-ce qu'un mythe ?
- □ Les mentions de marque sans lien ont-elles un impact sur votre référencement ?
- □ Les commentaires d'utilisateurs améliorent-ils vraiment le classement dans Google ?
- □ Les certificats SSL premium influencent-ils vraiment le référencement Google ?
- □ PDF et HTML avec le même contenu : faut-il craindre une cannibalisation dans les SERPs ?
- □ Peut-on vraiment piloter l'indexation des PDF via les headers HTTP ?
- □ Faut-il encore utiliser rel=next et rel=prev pour la pagination ?
- □ Googlebot peut-il vraiment indexer vos contenus en défilement infini ?
- □ Faut-il vraiment indexer toutes les pages de son site ?
- □ Faut-il vraiment rediriger l'ancien sitemap en 301 ou soumettre le nouveau directement ?
- □ Pourquoi 97% de crawl refresh est-il un signal positif pour votre site ?
- □ Comment Google détermine-t-il réellement la vitesse de crawl de votre site ?
- □ Vitesse de crawl et Core Web Vitals : pourquoi Google fait-il la distinction ?
- □ Pourquoi Google ralentit-il son crawl après un changement d'hébergement ?
- □ Le paramètre de taux de crawl est-il vraiment un plafond et non un objectif ?
- □ Le CTR peut-il vraiment pénaliser le reste de votre site ?
- □ Le maillage interne est-il vraiment l'élément le plus déterminant pour le SEO ?
- □ Le linking interne agit-il vraiment instantanément après recrawl ?
- □ Faut-il s'inquiéter si Google ne crawle pas toutes vos pages ?
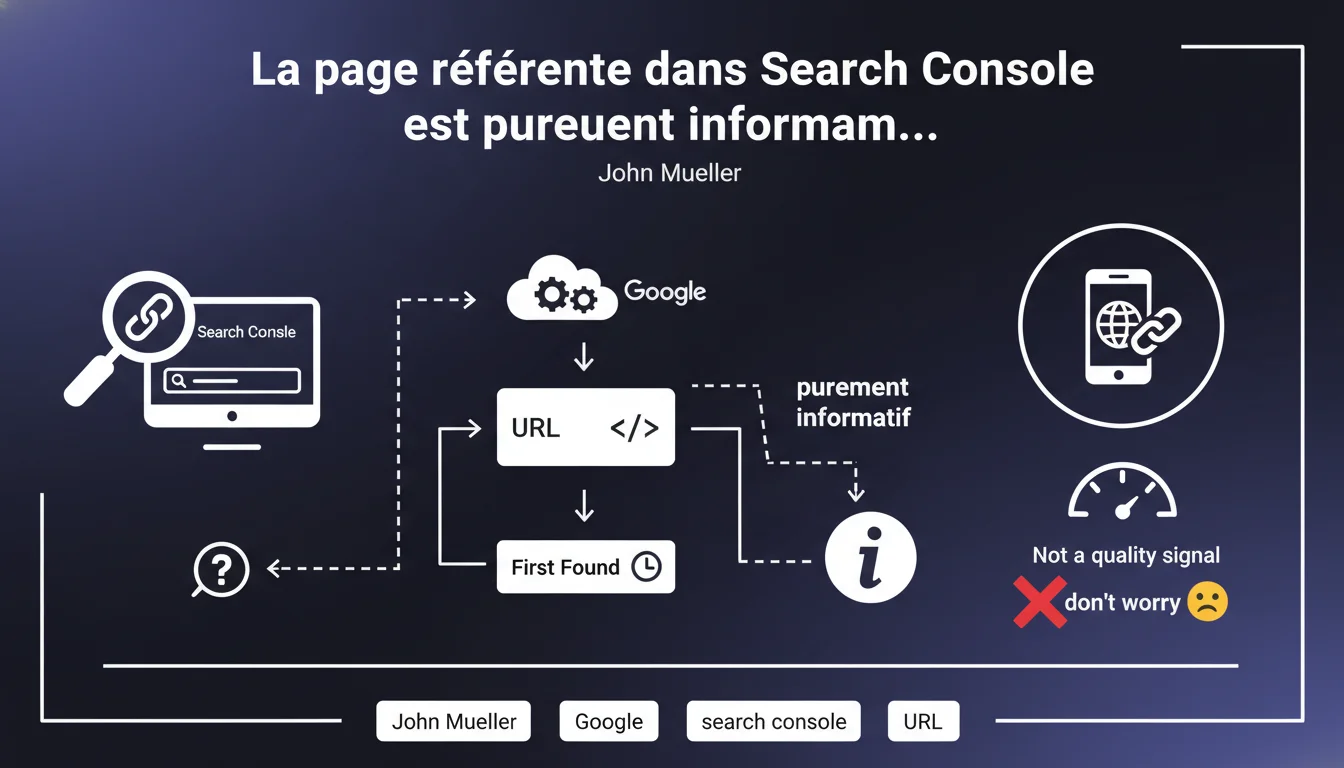
La page référente dans l'outil d'inspection d'URL de Search Console indique simplement où Google a découvert une URL pour la première fois. Ce n'est ni un signal de qualité, ni un critère de ranking, même si la source semble douteuse ou aléatoire.
Ce qu'il faut comprendre
Que signifie vraiment cette "page référente" dans Search Console ?
La page référente dans l'outil d'inspection d'URL correspond à la première occurrence détectée par Google pour crawler une URL donnée. C'est un simple marqueur historique de découverte — rien de plus.
Google garde en mémoire le premier point d'entrée par lequel Googlebot a rencontré cette URL. Ça peut être un lien depuis votre sitemap XML, depuis une page de votre propre site, ou depuis un site externe totalement aléatoire. Cette information est purement informative.
Pourquoi cette donnée apparaît-elle dans Search Console ?
Search Console affiche cette métadonnée pour aider les webmasters à comprendre comment Google découvre leur contenu. C'est utile pour tracer l'origine d'une indexation inattendue ou pour comprendre les chemins de crawl.
Mais attention : ce n'est pas parce qu'une URL a été découverte via un site tiers que ce lien a un poids SEO particulier. Google dissocie totalement la découverte de l'évaluation qualitative.
Cette page référente influence-t-elle le classement de mon URL ?
Non. La page référente n'a aucun impact direct sur le ranking. Google évalue votre page sur ses propres mérites : contenu, pertinence, signaux utilisateur, backlinks globaux — pas sur la base du premier lien qui a permis de la trouver.
Si votre URL a été découverte via un site de spam ou un annuaire douteux, ça ne pénalise pas votre page. Google crawle, indexe, puis évalue indépendamment.
- La page référente est un marqueur historique, pas un signal de qualité
- Elle n'affecte ni le crawl budget ni le ranking de la page
- Google dissocie découverte et évaluation SEO
- Inutile de paniquer si la source semble aléatoire ou peu recommandable
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, absolument. On observe régulièrement que des pages indexées via des sources improbables (agrégateurs automatiques, miroirs, scrapers) se classent parfaitement bien si leur contenu est solide. La page référente n'est qu'un détail technique de crawl.
En revanche, certains SEO confondent encore "première découverte" et "lien le plus important". Cette déclaration de Mueller remet les pendules à l'heure : Google ne fait pas de sentimentalisme sur l'origine du crawl.
Quelles nuances faut-il apporter ?
Soyons honnêtes : si votre page n'est découverte que via des sites externes douteux, ça peut signaler un problème structurel — mauvais maillage interne, sitemap XML absent, robots.txt bloquant. La page référente en elle-même n'est pas problématique, mais elle peut révéler un défaut d'architecture.
Autre point : une page qui n'apparaît nulle part dans votre propre maillage interne, mais qui est crawlée via un backlink externe, c'est un signal d'alerte. Pas parce que le backlink est "mauvais", mais parce que vous avez probablement orpheliné cette URL.
Dans quels cas cette règle pourrait-elle être trompeuse ?
Mueller parle de "page référente" dans Search Console, mais certains outils tiers utilisent le même terme pour désigner le lien le plus influent ou le "referring domain" principal. Ne mélangez pas les deux.
La page référente GSC ≠ le backlink qui transmet le plus de PageRank. C'est juste le premier point de contact. [À vérifier] : Google ne communique pas publiquement sur la façon dont il pondère les liens dans son graphe après la découverte initiale.
Impact pratique et recommandations
Que faut-il faire concrètement avec cette information ?
Arrêtez de surveiller la page référente comme un KPI. Elle ne vous dit rien sur la performance SEO de votre URL. Concentrez-vous plutôt sur les métriques qui comptent : impressions, clics, position moyenne, taux de crawl.
Si vous constatez qu'une URL stratégique a été découverte via un site externe plutôt que votre propre architecture, posez-vous la question : pourquoi Google ne l'a pas trouvée via votre maillage interne ou votre sitemap XML ?
Quelles erreurs éviter ?
Ne désavouez pas un domaine simplement parce qu'il apparaît comme page référente. Ce lien n'a peut-être aucun poids SEO et Google l'ignore probablement déjà dans son calcul de ranking.
Ne réorganisez pas votre site pour "contrôler" la page référente. C'est une donnée historique figée au moment de la première découverte. Même si vous ajoutez ensuite des liens internes, la page référente ne change pas dans Search Console.
Comment vérifier que mon site est correctement structuré ?
- Vérifiez que toutes vos pages stratégiques sont présentes dans votre sitemap XML
- Auditez votre maillage interne : aucune page orpheline, profondeur de clic raisonnable
- Utilisez l'outil d'inspection d'URL pour valider que Google peut crawler et indexer vos contenus prioritaires
- Surveillez les patterns de découverte : si trop d'URLs sont trouvées via des sources externes, c'est un problème d'architecture
- Ignorez la page référente comme signal de qualité — focalisez-vous sur les backlinks globaux et leur distribution thématique
❓ Questions frequentes
La page référente change-t-elle si je crée ensuite des liens internes vers cette URL ?
Si une page est découverte via un site de spam, dois-je désavouer ce lien ?
Peut-on forcer Google à utiliser une page référente spécifique ?
La page référente a-t-elle un lien avec le concept de "seed site" ou de "trusted domain" ?
Pourquoi certaines pages n'affichent-elles aucune page référente dans Search Console ?
🎥 De la même vidéo 23
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 18/02/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.