Declaration officielle
Autres déclarations de cette vidéo 20 ▾
- □ Pourquoi Google ne peut-il jamais garantir que vos utilisateurs atterriront sur la bonne version linguistique de votre site ?
- □ Faut-il bannir les redirections automatiques pour les sites multilingues ?
- □ Faut-il bloquer l'exécution JavaScript pour les SPA avec SSR ?
- □ Faut-il baliser les mots étrangers avec l'attribut lang pour le SEO ?
- □ Le contenu dupliqué entraîne-t-il vraiment une pénalité Google ?
- □ Le rel=canonical est-il vraiment pris en compte par Google ou juste une suggestion ignorée ?
- □ Les FAQ dans les articles de blog sont-elles vraiment utiles pour le SEO ?
- □ Hreflang est-il vraiment obligatoire pour gérer un site international ?
- □ Le cache Google a-t-il un impact sur votre référencement ?
- □ Les résultats de recherche localisés : comment Google adapte-t-il vraiment son algorithme selon les pays et les langues ?
- □ Le noindex est-il vraiment inutile pour gérer le budget de crawl ?
- □ Faut-il vraiment se limiter à une seule thématique sur son site pour bien ranker ?
- □ Combien de liens peut-on vraiment mettre sur une page sans pénalité Google ?
- □ Le nombre de mots est-il vraiment inutile pour le référencement ?
- □ Faut-il s'inquiéter de réutiliser les mêmes blocs de texte sur plusieurs pages ?
- □ Google valide-t-il vraiment la traduction automatique sur les sites multilingues ?
- □ Les URLs bloquées par robots.txt mais indexées posent-elles vraiment problème ?
- □ Faut-il vraiment dupliquer le schema Organisation sur toutes les pages du site ?
- □ Les avis auto-hébergés peuvent-ils afficher des étoiles dans les résultats de recherche Google ?
- □ Pourquoi les fusions de sites Web génèrent-elles des résultats imprévisibles aux yeux de Google ?
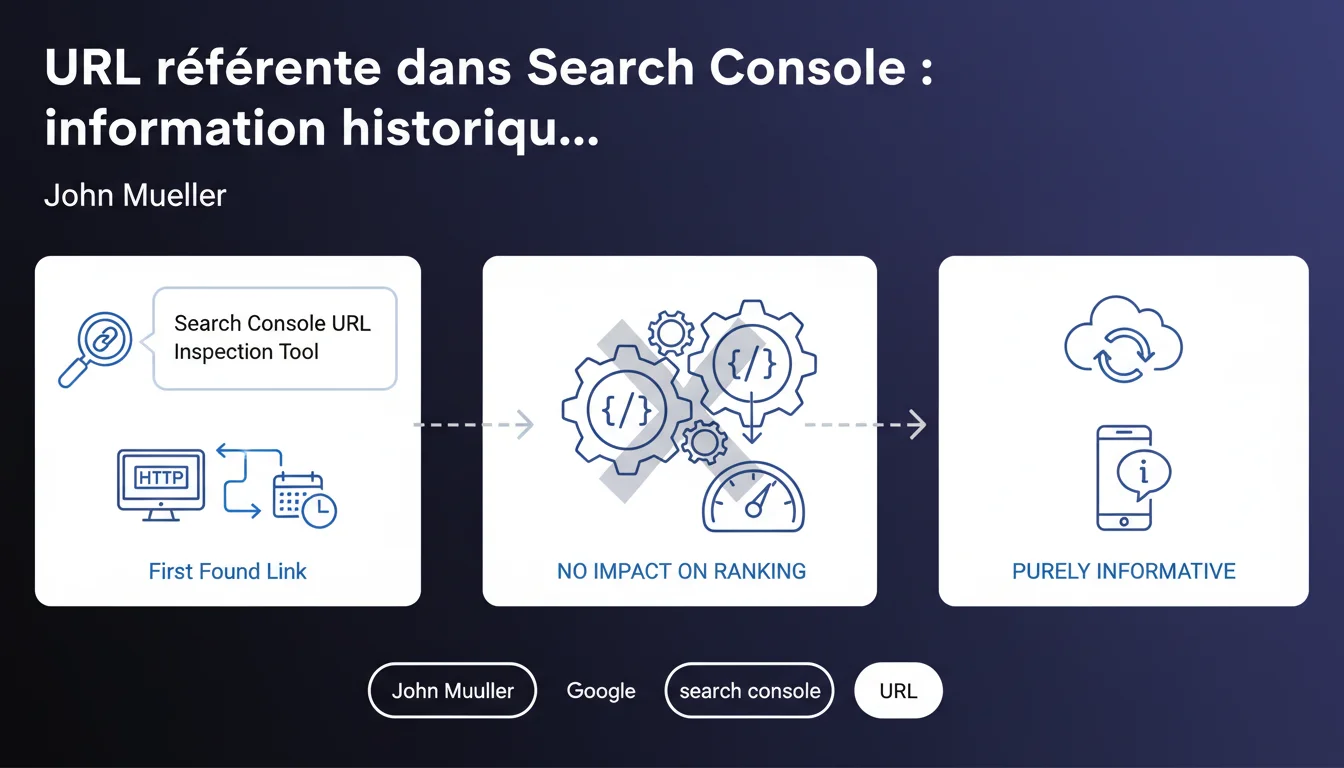
L'URL référente affichée dans l'outil d'inspection d'URL de Search Console indique simplement où Google a découvert le premier lien vers une page. Cette donnée est purement historique et n'a aucune influence sur le positionnement. Elle peut même pointer vers une ancienne version HTTP alors que votre site est en HTTPS.
Ce qu'il faut comprendre
Qu'est-ce que l'URL référente dans Search Console exactement ?
L'outil d'inspection d'URL de Search Console affiche une information appelée "URL référente". Il s'agit simplement de la page sur laquelle Googlebot a trouvé le premier lien pointant vers l'URL que vous inspectez.
Cette donnée est conservée dans l'historique de Google. Elle peut donc remonter à plusieurs mois ou années, même si la page référente n'existe plus ou a été modifiée depuis. C'est une trace archivée du parcours de découverte de Googlebot.
Pourquoi cette URL peut-elle sembler obsolète ou incohérente ?
Vous inspectez une page HTTPS moderne et l'URL référente pointe vers une vieille page HTTP ? Normal. Google conserve l'information du premier lien découvert historiquement, pas du dernier en date.
Cette URL peut même provenir d'une page supprimée, d'un ancien design de site ou d'un domaine migré. Elle n'est jamais mise à jour pour refléter l'état actuel de votre maillage interne.
Cette information a-t-elle un impact sur le référencement ?
Non. John Mueller est explicite : cette donnée est purement informative. Elle ne joue aucun rôle dans le calcul du classement, du PageRank interne ou de l'indexation actuelle.
Google utilise les liens qu'il trouve aujourd'hui pour évaluer votre site, pas ceux qu'il a découverts il y a trois ans. L'URL référente affichée dans Search Console relève de l'archéologie technique, rien de plus.
- L'URL référente montre où Googlebot a découvert le premier lien vers une page
- Cette information peut dater de plusieurs années et pointer vers des pages obsolètes
- Elle n'a aucun impact sur le classement ni sur l'indexation actuelle
- Google utilise les liens découverts récemment pour évaluer votre site, pas les traces historiques
- Ne perdez pas de temps à corriger cette URL référente, c'est inutile
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, complètement. J'ai croisé des dizaines de cas où l'URL référente pointait vers des pages HTTP migrées depuis longtemps, voire vers des anciens domaines. Aucun impact négatif observé sur le positionnement de ces pages.
Certains SEO s'inquiètent parfois de voir une URL référente "cassée" ou obsolète, pensant que Google considère encore ce lien. Cette déclaration de Mueller clôt le débat : cette donnée est archivée mais inactive dans l'algorithme.
Pourquoi Google conserve-t-il cette information si elle est inutile ?
Bonne question. Ma théorie : c'est une donnée de debug interne exposée dans Search Console sans véritable utilité pratique pour les webmasters. Google a historiquement un problème de communication entre ses équipes — certaines métriques affichées dans GSC relèvent plus du vestige technique que de l'outil actionnable.
Soyons honnêtes : si cette métrique avait un impact réel, Google la mettrait à jour en temps réel. Le fait qu'elle reste figée dans le passé confirme son caractère purement informatif.
Dans quels cas cette URL référente peut-elle quand même être utile ?
Elle peut servir lors d'un audit de migration. Si vous retrouvez des URL référentes pointant vers un ancien domaine ou une ancienne arborescence, ça vous confirme que Google a bien crawlé ces anciennes versions — utile pour comprendre l'historique du crawl.
Autre usage marginal : détecter d'où viennent vos premières découvertes. Si une page stratégique a été découverte via un lien externe de mauvaise qualité plutôt que via votre maillage interne, ça peut indiquer un problème de crawlabilité initial — mais attention, c'est de l'archéologie, pas du diagnostic actuel.
Impact pratique et recommandations
Que faut-il faire concrètement avec cette information ?
Rien. Littéralement. Ne perdez pas de temps à essayer de "corriger" cette URL référente ou à la mettre à jour. Ce n'est pas un signal pris en compte par l'algorithme de Google.
Concentrez vos efforts sur les liens actuellement crawlés : votre maillage interne, vos backlinks récents, la structure de navigation. C'est là que se joue votre référencement.
Quelles erreurs éviter ?
Première erreur : paniquer en voyant une URL référente obsolète ou cassée. Certains SEO créent des redirections ou modifient leur maillage pour "réparer" cette URL — c'est du temps perdu.
Deuxième erreur : utiliser cette métrique comme indicateur de santé SEO. Elle ne reflète pas l'état actuel de votre crawl ni de votre popularité interne.
Comment vérifier que vos liens actuels sont bien pris en compte ?
Utilisez le rapport "Liens" de Search Console pour voir les backlinks et liens internes actuellement indexés. C'est la source fiable pour auditer votre profil de liens.
Pour le maillage interne, crawlez votre site avec Screaming Frog ou Oncrawl. Comparez les profondeurs de clic et vérifiez que vos pages stratégiques reçoivent suffisamment de liens internes récents.
- Ignorez l'URL référente affichée dans l'outil d'inspection — elle n'a aucun impact SEO
- Ne créez pas de redirections ni de corrections pour "réparer" une URL référente obsolète
- Concentrez-vous sur le rapport "Liens" de Search Console pour auditer vos backlinks actuels
- Crawlez votre site régulièrement pour vérifier la qualité de votre maillage interne
- Assurez-vous que vos pages stratégiques sont bien découvertes via votre navigation actuelle
❓ Questions frequentes
Dois-je corriger une URL référente qui pointe vers une ancienne page HTTP ?
L'URL référente peut-elle expliquer un problème d'indexation ?
Le rapport Liens de Search Console affiche-t-il aussi des données obsolètes ?
Pourquoi Google affiche-t-il cette information si elle est inutile ?
Cette URL référente peut-elle servir lors d'une migration de site ?
🎥 De la même vidéo 20
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 21/10/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.