Declaration officielle
Autres déclarations de cette vidéo 20 ▾
- □ Pourquoi Google ne peut-il jamais garantir que vos utilisateurs atterriront sur la bonne version linguistique de votre site ?
- □ Faut-il bannir les redirections automatiques pour les sites multilingues ?
- □ Faut-il baliser les mots étrangers avec l'attribut lang pour le SEO ?
- □ Le contenu dupliqué entraîne-t-il vraiment une pénalité Google ?
- □ Le rel=canonical est-il vraiment pris en compte par Google ou juste une suggestion ignorée ?
- □ Les FAQ dans les articles de blog sont-elles vraiment utiles pour le SEO ?
- □ Hreflang est-il vraiment obligatoire pour gérer un site international ?
- □ Le cache Google a-t-il un impact sur votre référencement ?
- □ Les résultats de recherche localisés : comment Google adapte-t-il vraiment son algorithme selon les pays et les langues ?
- □ Le noindex est-il vraiment inutile pour gérer le budget de crawl ?
- □ Faut-il vraiment se limiter à une seule thématique sur son site pour bien ranker ?
- □ Combien de liens peut-on vraiment mettre sur une page sans pénalité Google ?
- □ L'URL référente dans Search Console impacte-t-elle vraiment votre classement ?
- □ Le nombre de mots est-il vraiment inutile pour le référencement ?
- □ Faut-il s'inquiéter de réutiliser les mêmes blocs de texte sur plusieurs pages ?
- □ Google valide-t-il vraiment la traduction automatique sur les sites multilingues ?
- □ Les URLs bloquées par robots.txt mais indexées posent-elles vraiment problème ?
- □ Faut-il vraiment dupliquer le schema Organisation sur toutes les pages du site ?
- □ Les avis auto-hébergés peuvent-ils afficher des étoiles dans les résultats de recherche Google ?
- □ Pourquoi les fusions de sites Web génèrent-elles des résultats imprévisibles aux yeux de Google ?
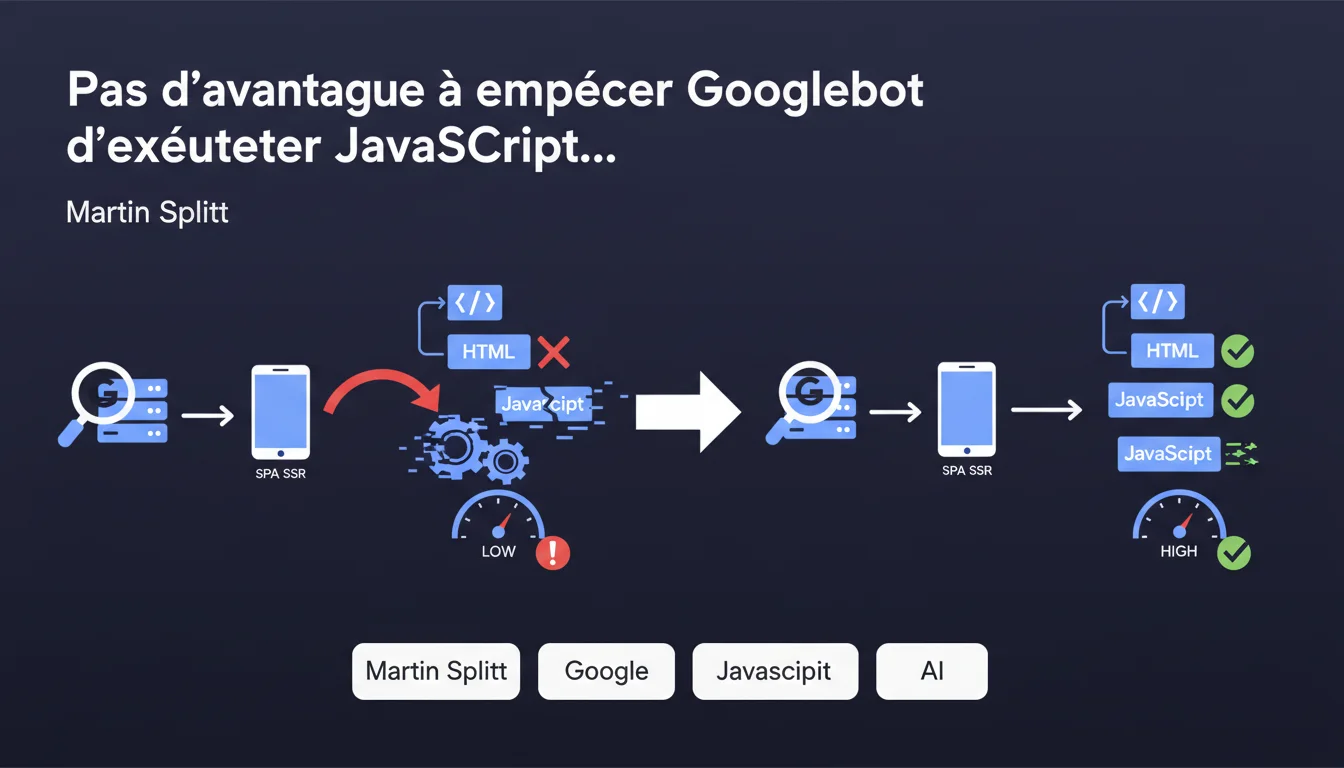
Pour les applications monopage avec rendu côté serveur, bloquer l'exécution JavaScript de Googlebot n'apporte aucun bénéfice. Au contraire, cela complique inutilement l'infrastructure puisque Googlebot exploite déjà le HTML pré-rendu. La complexité supplémentaire n'a aucune contrepartie en termes d'indexation ou de crawl budget.
Ce qu'il faut comprendre
Pourquoi cette question se pose-t-elle pour les SPA SSR ?
Les applications monopage (SPA) ont longtemps été un casse-tête SEO. Historiquement, elles généraient leur contenu côté client via JavaScript, rendant l'indexation problématique. Le rendu côté serveur (SSR) est apparu comme solution : le serveur génère le HTML complet avant l'envoi au navigateur.
Certains praticiens imaginent qu'il serait judicieux de bloquer l'exécution JavaScript pour Googlebot sur ces architectures SSR — l'idée étant d'économiser du crawl budget ou d'éviter des incohérences entre HTML initial et contenu hydraté. C'est précisément cette hypothèse que Martin Splitt démonte.
Qu'est-ce que Googlebot fait réellement avec un SPA SSR ?
Lorsque Googlebot crawle une page SSR, il reçoit d'abord le HTML complet pré-rendu. Ce contenu est immédiatement exploitable pour l'indexation. Ensuite, si JavaScript est disponible, Googlebot l'exécute — processus appelé hydratation côté client.
L'exécution JavaScript ne remplace pas le contenu initial : elle enrichit l'interactivité et peut révéler du contenu additionnel. Bloquer cette étape prive Googlebot d'une vision complète de l'expérience utilisateur réelle, sans économie mesurable de ressources.
Quels sont les risques de bloquer JavaScript sur SPA SSR ?
Introduire une règle spécifique pour empêcher Googlebot d'exécuter JavaScript ajoute une couche de complexité technique : détection d'user-agent, configuration serveur ou robots.txt adaptée, maintenance supplémentaire. Tout cela pour aucun gain identifié.
Pire, si l'hydratation JavaScript modifie certains éléments de la page (ajout de liens internes, lazy-loading d'images, mise à jour de structured data), bloquer l'exécution prive Googlebot de ces signaux. Vous créez une divergence entre ce que voit le bot et ce que vit l'utilisateur — exactement ce qu'il faut éviter.
- Le HTML SSR suffit à l'indexation de base, mais JavaScript complète la vision de Googlebot
- Bloquer JavaScript sur SPA SSR augmente la complexité sans bénéfice crawl budget réel
- Divergence bot/utilisateur : risque de perdre des signaux d'indexation (liens, images, données structurées)
- Aucun avantage mesurable à cette restriction selon la déclaration officielle
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, globalement. Les audits montrent que les SPA SSR bien implémentés sont indexés efficacement sans manipulation spécifique de l'accès JavaScript. Les frameworks modernes (Next.js, Nuxt, SvelteKit) génèrent un HTML complet côté serveur — Googlebot n'a jamais eu de difficulté avec ce format.
En revanche, certains praticiens rapportent des gains de crawl budget en limitant JavaScript sur des sites massifs avec des milliers de pages. [A vérifier] : ces gains sont-ils liés au blocage JavaScript ou à d'autres optimisations (réduction de ressources tierces, scripts analytics, etc.) ? La déclaration de Splitt ne quantifie pas l'impact crawl budget — elle affirme simplement qu'il n'y a « aucun avantage », ce qui reste vague.
Dans quels cas cette règle pourrait-elle ne pas s'appliquer ?
Soyons honnêtes : cette déclaration vise les SPA avec SSR propre. Si votre SPA utilise un SSR partiel ou hybride, avec du contenu critique uniquement accessible post-hydratation, la situation change. Dans ce cas, bloquer JavaScript devient effectivement contre-productif — mais c'est surtout le signe d'une architecture mal pensée.
Pour les sites à très fort volume de crawl (millions de pages, taux de renouvellement élevé), certains experts continuent de tester des restrictions JavaScript sur des ressources non critiques. La déclaration de Splitt ne couvre pas explicitement ces edge cases. Si vous êtes dans cette situation, les tests A/B restent indispensables.
Quelle nuance technique faut-il intégrer ?
La déclaration parle d'« empêcher Googlebot d'exécuter les bundles JavaScript ». Concrètement, cela signifierait bloquer les fichiers .js via robots.txt ou renvoyer un 403/404 à Googlebot pour ces ressources. Ce n'est pas la même chose que de réduire la taille des bundles, différer leur chargement ou optimiser leur exécution.
Réduire le poids JavaScript, minifier, tree-shaking, code-splitting — toutes ces optimisations restent pertinentes. Ce que Splitt conteste, c'est l'idée de bloquer l'accès complet aux bundles pour Googlebot sous prétexte d'économiser du crawl budget. Nuance importante.
Impact pratique et recommandations
Que faut-il faire concrètement pour les SPA SSR ?
Première règle : ne bloquez pas JavaScript pour Googlebot. Pas de règle Disallow dans robots.txt visant les bundles .js, pas de détection d'user-agent renvoyant un contenu tronqué. Laissez Googlebot accéder à l'ensemble des ressources nécessaires à l'exécution de la page.
Ensuite, vérifiez que votre HTML SSR est complet et autonome. Testez avec un navigateur sans JavaScript activé : le contenu essentiel doit être présent. Si vous dépendez de JavaScript pour afficher du texte, des liens internes ou des structured data, votre SSR est insuffisant — et bloquer JavaScript aggraverait le problème.
Quelles erreurs éviter lors de l'implémentation SSR ?
Évitez l'hydratation qui écrase du contenu. Certains frameworks réinitialisent le DOM lors de l'hydratation, créant un flash de contenu non stylisé (FOUC) ou pire, modifiant des éléments déjà indexables. Googlebot peut capturer un état transitoire incohérent.
Ne surchargez pas l'hydratation de logique métier lourde. Si votre JavaScript côté client doit faire des appels API pour compléter la page, c'est que votre SSR est incomplet. Le contenu critique doit être pré-rendu côté serveur, pas reconstruit côté client.
Comment vérifier que votre site est conforme à cette recommandation ?
Utilisez l'outil d'inspection d'URL dans Google Search Console. Comparez le HTML brut (onglet « HTML » ou « Plus d'infos ») avec le rendu affiché. Si les deux versions sont identiques ou quasi-identiques, votre SSR fonctionne correctement et JavaScript n'ajoute que de l'interactivité.
Testez également avec curl ou un bot headless sans JavaScript. Si le contenu essentiel manque, votre SSR est défaillant — et bloquer JavaScript serait catastrophique. Enfin, surveillez les logs serveur : si Googlebot génère beaucoup de requêtes vers vos bundles .js, c'est normal. Ce n'est pas un problème à corriger.
- Autoriser l'accès complet de Googlebot à tous les fichiers JavaScript (pas de Disallow dans robots.txt)
- Vérifier l'autonomie du HTML SSR : contenu critique présent sans exécution JavaScript
- Tester l'hydratation : aucun écrasement de contenu, pas de FOUC majeur
- Inspecter dans Search Console : comparer HTML brut et rendu final
- Monitorer les logs : accepter que Googlebot charge les bundles JavaScript
- Ne pas créer de règles complexes pour bloquer JavaScript spécifiquement pour Googlebot
En résumé : pour les SPA SSR, simplifiez votre approche. Laissez Googlebot accéder à tout, concentrez-vous sur un SSR robuste et une hydratation propre. La complexité supplémentaire d'un blocage JavaScript n'apporte rien.
Ces optimisations — SSR performant, hydratation maîtrisée, monitoring des logs — peuvent nécessiter une expertise technique approfondie et une connaissance fine des frameworks modernes. Si votre équipe manque de ressources ou d'expérience sur ces architectures, faire appel à une agence SEO spécialisée en JavaScript SEO peut s'avérer judicieux pour un accompagnement personnalisé et éviter les erreurs coûteuses.
❓ Questions frequentes
Dois-je bloquer les fichiers JavaScript pour économiser du crawl budget sur un SPA SSR ?
Que se passe-t-il si je bloque JavaScript pour Googlebot sur un SPA SSR ?
Comment vérifier que mon SPA SSR est correctement indexé sans bloquer JavaScript ?
Cette recommandation vaut-elle aussi pour les SPA sans SSR (CSR pur) ?
Le SSR élimine-t-il complètement les problèmes d'indexation JavaScript ?
🎥 De la même vidéo 20
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 21/10/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.