Declaration officielle
Autres déclarations de cette vidéo 8 ▾
- □ Google indexe-t-il vraiment le HTML rendu plutôt que le code source ?
- □ Google respecte-t-il vraiment votre balise canonical ou décide-t-il seul ?
- □ Comment vérifier efficacement les directives X-Robots dans vos en-têtes HTTP ?
- □ Les ressources JavaScript bloquées par robots.txt sabotent-elles vraiment votre indexation ?
- □ Faut-il vraiment s'inquiéter des erreurs de ressources dans la Search Console ?
- □ Les messages console JavaScript sont-ils devenus un signal SEO à surveiller ?
- □ Pourquoi le test d'URL en direct de Google Search Console donne-t-il des résultats différents à chaque fois ?
- □ Faut-il vraiment ignorer les captures d'écran dans les outils de test de Google ?
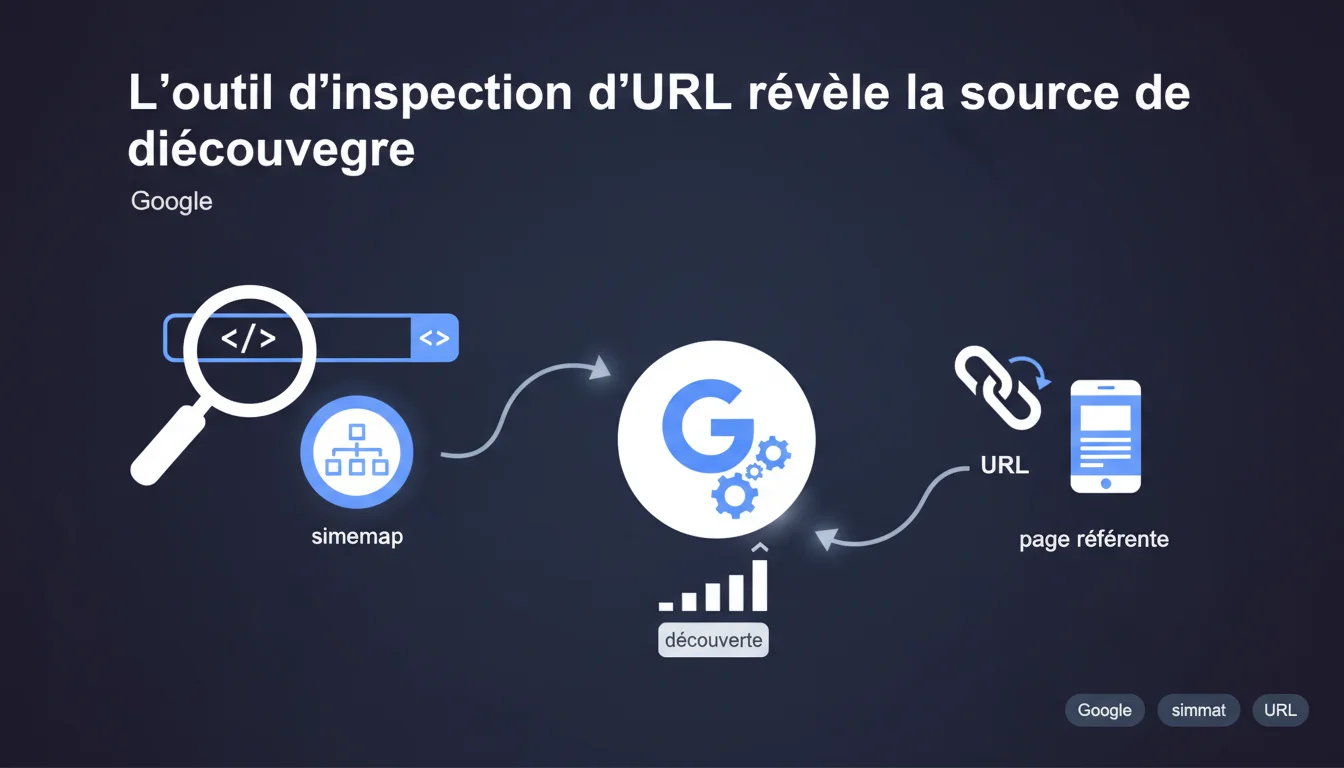
L'outil d'inspection d'URL de Google Search Console affiche désormais comment Googlebot a découvert chaque page indexée : via un sitemap XML ou via une page référente spécifique. Cette transparence permet d'identifier les problèmes de crawl et d'optimiser la façon dont Google accède à vos contenus stratégiques.
Ce qu'il faut comprendre
Que révèle exactement cette nouvelle information ?
L'outil d'inspection d'URL ne se contente plus de dire si une page est indexée. Il indique maintenant la méthode de découverte utilisée par Googlebot : soit un fichier sitemap XML, soit une page référente identifiée précisément.
Concrètement, vous savez si Google a trouvé votre page parce que vous l'avez soumise activement via sitemap, ou parce qu'il l'a découverte en suivant un lien depuis une autre page de votre site (ou externe). Cette distinction n'est pas anodine.
Pourquoi cette granularité change-t-elle la donne ?
Jusqu'ici, diagnostiquer pourquoi certaines pages n'étaient pas crawlées relevait souvent du tâtonnement. Vous aviez des hypothèses : profondeur de clic excessive, liens orphelins, problèmes de budget crawl.
Désormais, vous disposez d'une preuve factuelle. Si une page stratégique n'apparaît que via sitemap et jamais via découverte naturelle, c'est qu'elle souffre d'un problème de maillage interne. À l'inverse, si Google la trouve par découverte mais pas via sitemap, votre fichier XML mérite un audit.
Quelle différence entre sitemap et page référente dans la pratique ?
Les sitemaps sont une suggestion — pas un ordre. Google les consulte mais ne garantit pas le crawl de toutes les URLs listées, surtout si votre budget crawl est serré.
La découverte via page référente, elle, indique que Googlebot a activement suivi un lien depuis une page déjà connue. C'est un signal que votre maillage fonctionne et que la page bénéficie d'une certaine autorité de crawl transmise par la page source.
- L'outil affiche la source précise : URL du sitemap ou URL de la page référente exacte
- Cela permet de tracer le chemin de découverte de Googlebot à travers votre arborescence
- Utile pour identifier les pages orphelines qui ne seraient découvertes que via sitemap
- Aide à prioriser le maillage interne vers les pages stratégiques mal découvertes
- Permet de détecter les incohérences entre votre sitemap et votre structure de liens réels
Avis d'un expert SEO
Cette transparence est-elle réellement nouvelle ?
Soyons honnêtes : Google a toujours su comment il découvrait vos pages. La nouveauté, c'est qu'il partage enfin cette donnée dans Search Console de façon accessible.
Avant, certains logs serveur permettaient de reconstituer cette information en croisant les requêtes Googlebot avec vos sitemaps et votre structure de liens. Mais c'était chronophage et réservé aux sites équipés d'infrastructures d'analyse solides. Désormais, c'est démocratisé.
Quelles limites faut-il anticiper avec cet outil ?
Premier point : l'outil d'inspection affiche la source de la dernière découverte connue. Si Googlebot a découvert votre page via sitemap il y a six mois, puis l'a re-crawlée via un lien interne hier, l'historique complet n'est pas forcément visible. [À vérifier] si Google conserve un historique des différentes méthodes de découverte ou seulement la plus récente.
Deuxième nuance : cette information ne dit rien sur la qualité ou la priorité accordée à la page. Une découverte via page référente n'est pas automatiquement synonyme d'indexation rapide ou de bon positionnement — elle confirme juste que le chemin de crawl existe.
Cette donnée remet-elle en question les pratiques actuelles ?
Pas vraiment. Les fondamentaux restent : maillage interne cohérent, sitemap XML propre, architecture plate, crawl budget optimisé. Ce que cet outil fait, c'est rendre visible ce qui était jusqu'ici opaque.
Mais il offre un levier diagnostique précieux. Si vous constatez que vos pages stratégiques ne sont découvertes que via sitemap, c'est un signal d'alarme clair : votre maillage interne ne fait pas son job. Inversement, si des pages secondaires ou inutiles sont massivement crawlées via découverte naturelle, vous gaspillez du budget crawl — et il faut revoir votre nofollow ou votre robots.txt.
Impact pratique et recommandations
Que faut-il auditer en priorité avec cette information ?
Commencez par vos pages stratégiques : fiches produits phares, landing pages SEO, contenus piliers. Inspectez-les une par une et notez la source de découverte affichée.
Si elles n'apparaissent que via sitemap, c'est que Google ne les trouve pas naturellement en naviguant sur votre site. Cela signifie qu'elles sont soit trop profondes dans l'arborescence, soit mal liées, soit totalement orphelines malgré leur présence dans le sitemap.
Comment corriger un problème de découverte défaillante ?
Si une page critique n'est découverte que via sitemap, renforcez son maillage interne. Ajoutez des liens depuis la page d'accueil, depuis des catégories principales, depuis des articles de blog connexes.
Vérifiez aussi la profondeur de clic : idéalement, aucune page importante ne devrait être à plus de 3 clics de la racine. Si c'est le cas, revoyez votre arborescence.
À l'inverse, si des pages parasites (archives de dates, tags inutiles, facettes générées automatiquement) sont découvertes massivement via pages référentes, demandez-vous si elles méritent d'être crawlées. Ajoutez des noindex, des nofollow sur les liens vers ces sections, ou bloquez-les dans robots.txt si pertinent.
Quelles erreurs éviter lors de l'interprétation de ces données ?
Ne tirez pas de conclusions hâtives sur une seule page. Inspectez un échantillon représentatif : 20-30 URLs réparties entre contenus stratégiques, pages transactionnelles, contenus éditoriaux.
Ne négligez pas non plus les délais de crawl. Une page récemment publiée peut apparaître comme découverte via sitemap simplement parce que Googlebot ne l'a pas encore trouvée par navigation naturelle. Laissez quelques semaines avant de paniquer.
- Auditer la source de découverte de 20-30 pages stratégiques via l'outil d'inspection
- Identifier les pages orphelines découvertes uniquement via sitemap
- Renforcer le maillage interne vers ces pages isolées
- Vérifier la profondeur de clic et l'accessibilité réelle depuis la page d'accueil
- Détecter les sections secondaires sur-crawlées via pages référentes
- Nettoyer les liens inutiles ou ajouter des nofollow/noindex si pertinent
- Croiser cette donnée avec les logs serveur pour une vision complète du comportement de Googlebot
- Réévaluer régulièrement : la source de découverte peut évoluer après optimisations
❓ Questions frequentes
Est-ce que la source de découverte influence directement le classement d'une page ?
Si une page n'apparaît que via sitemap, est-elle pénalisée par Google ?
Peut-on forcer Google à découvrir une page via une méthode plutôt qu'une autre ?
L'outil affiche-t-il toutes les sources de découverte ou seulement la dernière ?
Faut-il supprimer les pages découvertes uniquement via sitemap de ce fichier XML ?
🎥 De la même vidéo 8
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 02/08/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.