Declaration officielle
Autres déclarations de cette vidéo 8 ▾
- □ Google indexe-t-il vraiment le HTML rendu plutôt que le code source ?
- □ Comment l'outil d'inspection d'URL révèle-t-il la source de découverte de vos pages ?
- □ Google respecte-t-il vraiment votre balise canonical ou décide-t-il seul ?
- □ Les ressources JavaScript bloquées par robots.txt sabotent-elles vraiment votre indexation ?
- □ Faut-il vraiment s'inquiéter des erreurs de ressources dans la Search Console ?
- □ Les messages console JavaScript sont-ils devenus un signal SEO à surveiller ?
- □ Pourquoi le test d'URL en direct de Google Search Console donne-t-il des résultats différents à chaque fois ?
- □ Faut-il vraiment ignorer les captures d'écran dans les outils de test de Google ?
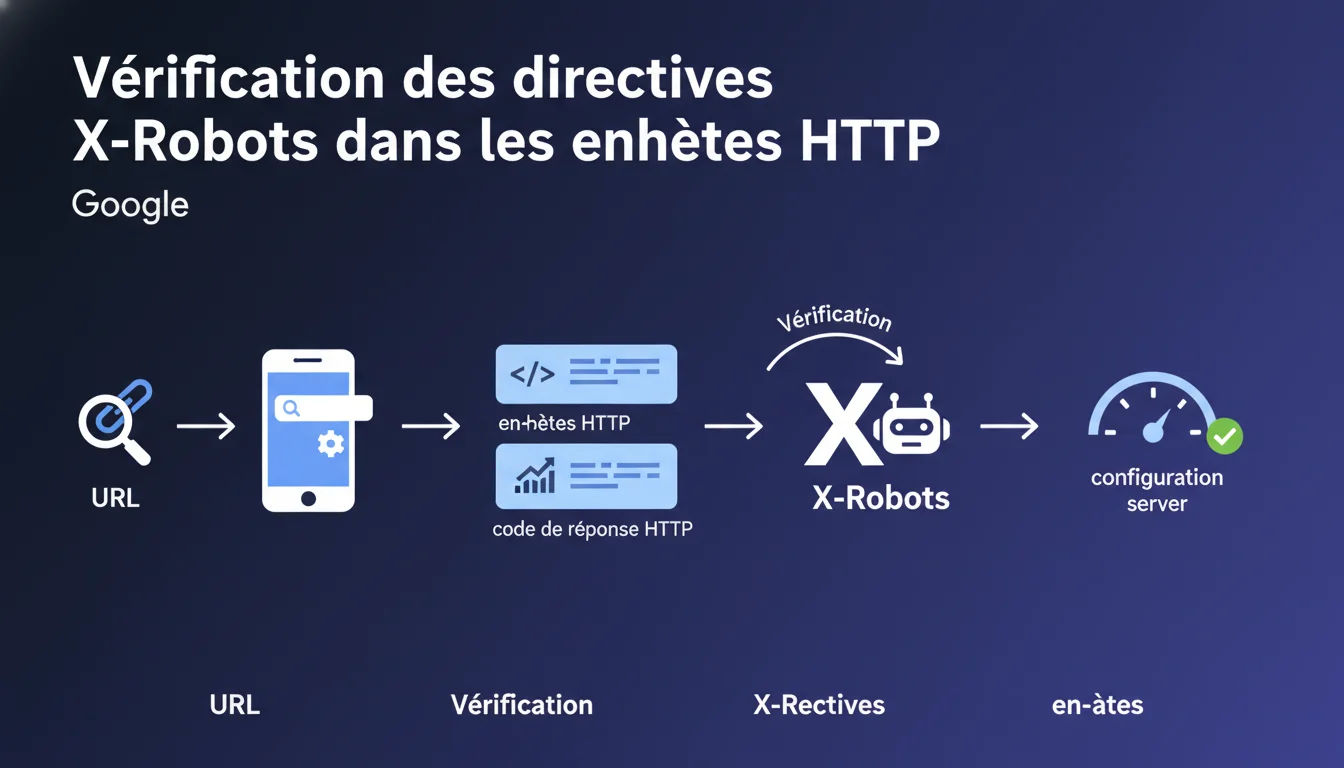
Google confirme que l'outil d'inspection d'URL affiche les en-têtes de réponse HTTP, permettant de diagnostiquer les directives X-Robots et autres problèmes de configuration serveur. Cette fonctionnalité est essentielle pour identifier rapidement les blocages d'indexation liés aux en-têtes plutôt qu'aux balises meta robots.
Ce qu'il faut comprendre
Pourquoi les en-têtes HTTP sont-ils critiques pour l'indexation ?
Les directives X-Robots passent souvent sous le radar, contrairement aux balises meta robots visibles dans le code HTML. Pourtant, elles ont exactement le même pouvoir : bloquer l'indexation, empêcher le suivi des liens, interdire les snippets.
La différence ? Elles sont invisibles dans le source HTML. Un développeur peut configurer un X-Robots-Tag: noindex au niveau du serveur (Apache, Nginx, IIS) et personne ne le verra en inspectant la page. Résultat : des sections entières d'un site peuvent disparaître de l'index sans qu'on comprenne pourquoi.
Que permet concrètement l'outil d'inspection d'URL ?
L'outil affiche le code de réponse HTTP (200, 301, 404, etc.) et tous les en-têtes retournés par le serveur. Cela inclut les directives X-Robots-Tag, mais aussi les en-têtes de cache, les redirections, les CSP, les CORS.
Concrètement ? Vous entrez une URL, Google vous montre exactement ce que Googlebot voit quand il crawle cette page. Pas de mystère, pas d'interprétation : les données brutes du serveur.
Quelles sont les directives X-Robots les plus courantes ?
- X-Robots-Tag: noindex — bloque l'indexation, équivalent strict de meta robots noindex
- X-Robots-Tag: nofollow — empêche le suivi des liens sortants
- X-Robots-Tag: none — combine noindex et nofollow
- X-Robots-Tag: noarchive — interdit la mise en cache de la page
- X-Robots-Tag: nosnippet — supprime les extraits dans les SERP
- X-Robots-Tag: unavailable_after — définit une date d'expiration pour l'indexation
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées ?
Oui, totalement. L'outil d'inspection d'URL est le premier réflexe diagnostique pour toute page non indexée ou crawlée bizarrement. Il montre exactement ce que Googlebot reçoit, sans filtre.
Par contre — et c'est là que ça coince — Google ne donne aucun détail sur comment interpréter les conflits entre directives. Que se passe-t-il si une page a à la fois un X-Robots-Tag: noindex dans les en-têtes et un meta robots index dans le HTML ? Quelle directive prime ? [A vérifier] sur des cas terrain, car la documentation officielle reste floue.
Quelles limites faut-il connaître pour cet outil ?
L'outil d'inspection d'URL montre les en-têtes au moment du test. Si votre serveur change dynamiquement les en-têtes selon l'user-agent, le contexte ou l'heure, vous ne verrez qu'une seule version.
Autre point : l'outil ne stocke pas l'historique des en-têtes. Si un X-Robots-Tag: noindex a bloqué votre site pendant 3 semaines avant d'être retiré, vous n'aurez aucune trace. Il faut croiser avec les logs serveur ou des outils de monitoring tiers.
Dans quels cas cette approche ne suffit-elle pas ?
Quand le problème vient de couches intermédiaires : CDN, proxy, firewall applicatif. Ces systèmes peuvent injecter ou modifier des en-têtes HTTP sans que le serveur d'origine en soit responsable.
Exemple vécu : un Cloudflare mal configuré qui ajoutait un X-Robots-Tag: noindex sur toutes les pages en cache. Le serveur d'origine était clean, l'outil d'inspection affichait le problème, mais le développeur cherchait l'erreur au mauvais endroit. Il faut toujours remonter la chaîne technique jusqu'à la source réelle du header.
Impact pratique et recommandations
Comment vérifier les directives X-Robots sur votre site ?
Première étape : utilisez l'outil d'inspection d'URL dans la Search Console pour tester vos pages stratégiques. Entrez l'URL, cliquez sur "Tester l'URL en direct", puis consultez la section "Plus d'infos" pour voir les en-têtes HTTP.
Deuxième méthode : utilisez curl en ligne de commande — curl -I https://votresite.com/page — pour voir les en-têtes bruts. Plus rapide pour des tests en masse, mais ne garantit pas que Googlebot verra exactement la même chose.
Quelles erreurs éviter avec les X-Robots-Tag ?
- Ne jamais définir un X-Robots-Tag: noindex global sur l'environnement de production par copier-coller depuis la staging
- Vérifier que les directives ne s'appliquent pas aux fichiers CSS/JS — sinon Googlebot peut avoir du mal à rendre les pages
- Ne pas confondre X-Robots-Tag (en-tête HTTP) et meta robots (balise HTML) dans vos audits — les deux coexistent et peuvent entrer en conflit
- Documenter toutes les directives X-Robots dans un fichier de config versionné — sinon personne ne saura pourquoi une section est bloquée six mois plus tard
Quelle stratégie adopter pour un site complexe ?
Pour les sites avec plusieurs milliers de pages, impossible de tout vérifier manuellement. Il faut automatiser le crawl avec Screaming Frog ou Oncrawl en activant l'extraction des en-têtes HTTP.
Ensuite, croiser ces données avec les logs serveur pour repérer les incohérences : pages crawlées mais avec un X-Robots-Tag: noindex, pages indexées alors qu'elles devraient être bloquées, etc.
Les directives X-Robots sont puissantes mais insidieuses. Elles demandent une surveillance continue et une parfaite coordination entre équipes SEO et dev. Pour les sites e-commerce ou les plateformes multilingues, où une erreur de configuration peut faire disparaître des centaines de pages de l'index, il est souvent plus sûr de s'appuyer sur une agence SEO spécialisée qui maîtrise ces aspects techniques et sait auditer l'ensemble de la chaîne de diffusion.
❓ Questions frequentes
Quelle différence entre X-Robots-Tag et meta robots ?
Que faire si l'outil d'inspection affiche un X-Robots-Tag inattendu ?
Les X-Robots-Tag peuvent-ils bloquer le crawl en plus de l'indexation ?
Peut-on cibler des robots spécifiques avec X-Robots-Tag ?
Les X-Robots-Tag affectent-ils le référencement des images et PDF ?
🎥 De la même vidéo 8
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 02/08/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.