Declaration officielle
Autres déclarations de cette vidéo 8 ▾
- □ Google indexe-t-il vraiment le HTML rendu plutôt que le code source ?
- □ Comment l'outil d'inspection d'URL révèle-t-il la source de découverte de vos pages ?
- □ Google respecte-t-il vraiment votre balise canonical ou décide-t-il seul ?
- □ Comment vérifier efficacement les directives X-Robots dans vos en-têtes HTTP ?
- □ Faut-il vraiment s'inquiéter des erreurs de ressources dans la Search Console ?
- □ Les messages console JavaScript sont-ils devenus un signal SEO à surveiller ?
- □ Pourquoi le test d'URL en direct de Google Search Console donne-t-il des résultats différents à chaque fois ?
- □ Faut-il vraiment ignorer les captures d'écran dans les outils de test de Google ?
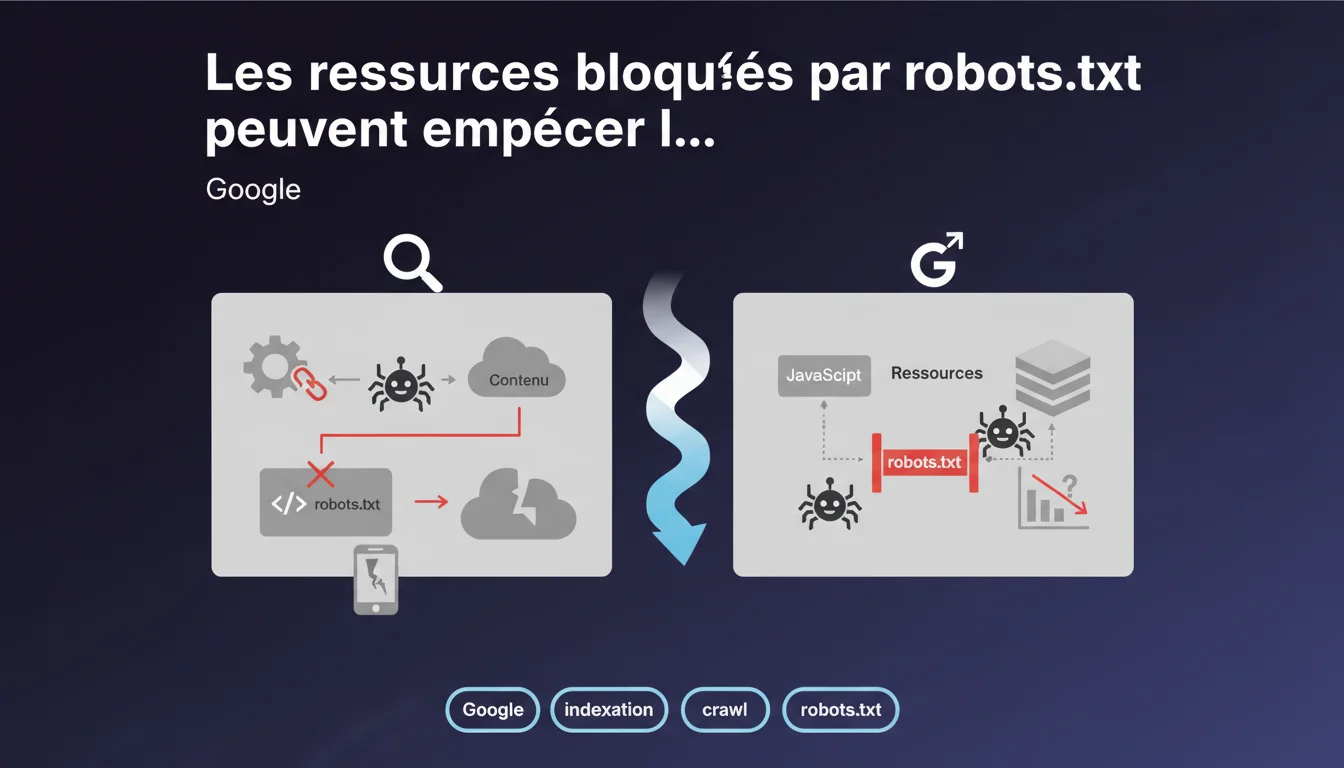
Google confirme que les ressources chargées via JavaScript et bloquées par robots.txt peuvent rendre du contenu invisible pour le moteur. Si des éléments critiques transitent par ces fichiers, ils ne seront jamais indexés. L'outil d'inspection d'URL révèle désormais quelles requêtes ont échoué pendant le crawl et le rendu.
Ce qu'il faut comprendre
Pourquoi Google mentionne-t-il explicitement JavaScript et robots.txt ensemble ?
Parce que le problème se situe à l'intersection de deux processus distincts : le crawl initial et le rendu JavaScript. Quand Googlebot charge une page, il télécharge d'abord le HTML, puis exécute le JavaScript pour révéler le contenu dynamique.
Si des fichiers JS, CSS ou autres ressources nécessaires au rendu sont bloqués par robots.txt, le bot ne peut pas reconstituer la page telle qu'elle apparaît aux utilisateurs. Résultat : du contenu disparaît purement et simplement de l'index.
Quel outil permet de détecter ces blocages ?
L'outil d'inspection d'URL dans Google Search Console affiche désormais un rapport détaillé des requêtes effectuées pendant le crawl et le rendu. Pour chaque ressource, vous voyez si elle a été téléchargée, bloquée ou si elle a échoué pour une autre raison.
Cette visibilité était inexistante avant — on devait deviner où ça coinçait. Maintenant, Google pointe directement les ressources problématiques.
Qu'est-ce qui constitue du "contenu important" dans ce contexte ?
Tout élément qui modifie la structure ou le sens de la page : textes chargés en Ajax, blocs de contenu conditionnels, menus de navigation générés côté client, fils d'Ariane dynamiques, schémas JSON-LD injectés via JS.
Si ces éléments dépendent de fichiers bloqués, Google ne les verra jamais. Et contrairement à une idée reçue, le bot ne fait pas d'exception pour du "contenu important" — bloqué est bloqué.
- Les ressources JavaScript bloquées par robots.txt empêchent le rendu complet de la page
- L'outil d'inspection d'URL révèle précisément quelles requêtes ont échoué et pourquoi
- Le contenu chargé via ces ressources devient invisible pour l'index
- Aucune exception n'est faite pour du contenu jugé "important" — la règle robots.txt prime
- Cela concerne aussi bien les fichiers JS que CSS, images ou APIs externes
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec ce qu'on observe sur le terrain ?
Totalement. On voit régulièrement des sites qui bloquent /wp-includes/ ou /assets/js/ par reflexe sécuritaire, sans réaliser qu'ils sabotent leur indexation. Le problème est particulièrement vicieux sur les SPAs (React, Vue, Angular) où tout le contenu transite par JavaScript.
Ce qui est nouveau, c'est que Google le dit explicitement et fournit un outil pour le diagnostiquer. Avant, les SEO devaient utiliser des solutions artisanales (Screaming Frog avec rendu JS, comparaison HTML source vs DOM final). Maintenant, Search Console fait le boulot.
Quelles nuances faut-il apporter à cette règle ?
Soyons honnêtes : Google ne précise pas à quel point une ressource doit être importante pour affecter l'indexation. Si un fichier JS bloqué modifie seulement la couleur d'un bouton, aucun impact. Mais s'il charge les 2000 mots de contenu principal ? Catastrophe.
Autre point flou : que se passe-t-il quand une ressource bloquée génère une erreur JS qui casse tout le rendu ? Google indexe-t-il la version partielle ou abandonne-t-il ? [À vérifier] — la documentation reste évasive sur les scénarios de dégradation gracieuse.
Dans quels cas ce problème ne se pose-t-il pas ?
Si votre site sert du contenu en HTML statique avec JavaScript utilisé uniquement pour des interactions (accordéons, sliders, animations), vous êtes tranquille. Le contenu existe dans le source, donc Google l'indexe même si le JS est bloqué.
Idem pour le rendu côté serveur (SSR) — Next.js, Nuxt, etc. — où le HTML final contient déjà tout le contenu. Le JavaScript sert alors à l'hydratation, pas à la génération de contenu. Bloquer ces fichiers dégrade l'UX mais n'affecte pas l'indexation.
Impact pratique et recommandations
Comment vérifier que vos ressources JavaScript sont accessibles à Google ?
Première étape : ouvrez Search Console, sélectionnez une URL stratégique, lancez l'inspection d'URL, puis cliquez sur "Tester l'URL en direct". Une fois le test terminé, consultez l'onglet "Plus d'informations" puis "Ressources demandées".
Vous verrez trois colonnes : ressources téléchargées, ressources non téléchargées, et ressources bloquées par robots.txt. Si des fichiers JS ou CSS critiques apparaissent dans la colonne "bloqués", vous avez un problème.
Que faire concrètement si des ressources critiques sont bloquées ?
Modifiez votre robots.txt pour autoriser explicitement ces ressources. Évitez les directives Disallow: /wp-includes/ ou Disallow: /assets/ trop larges — préférez des exclusions ciblées.
Si vous bloquez volontairement certains répertoires pour des raisons de sécurité, déplacez les fichiers critiques ailleurs. Par exemple, sortez les scripts de rendu de contenu hors de /admin/ ou /private/.
- Testez vos principales landing pages avec l'outil d'inspection d'URL
- Identifiez les ressources bloquées dans l'onglet "Ressources demandées"
- Comparez le HTML source et le DOM rendu pour détecter le contenu manquant
- Modifiez robots.txt pour autoriser les fichiers JS/CSS critiques
- Re-testez l'URL en direct et vérifiez que les ressources sont maintenant téléchargées
- Demandez une réindexation si du contenu important était invisible
- Mettez en place une surveillance mensuelle des ressources bloquées
Le blocage de ressources JavaScript par robots.txt n'est pas un problème théorique — c'est une cause réelle et fréquente de perte de contenu indexable. L'outil d'inspection d'URL lève enfin le voile sur ce qui se passe côté Googlebot.
Concrètement : auditez vos règles robots.txt, testez vos pages stratégiques, et assurez-vous que tout ce qui sert du contenu est accessible. Si vous n'êtes pas à l'aise avec le rendu JavaScript ou que votre stack technique est complexe (React, Vue, Angular, hydratation partielle), ces diagnostics peuvent vite devenir techniques. Une agence SEO spécialisée sur les architectures JavaScript saura identifier les ressources critiques, optimiser votre robots.txt sans compromettre la sécurité, et mettre en place un monitoring adapté — ce qui évite de passer des heures à débugger des problèmes d'indexation invisibles.
❓ Questions frequentes
Faut-il systématiquement autoriser tous les fichiers JavaScript et CSS dans robots.txt ?
Si Google affiche une erreur de ressource bloquée, est-ce que cela pénalise le classement ?
L'outil d'inspection montre des ressources tierces bloquées (Google Analytics, Facebook Pixel). Est-ce grave ?
Comment savoir si du contenu important manque dans le rendu Googlebot ?
Est-ce que débloquer des ressources dans robots.txt nécessite une nouvelle indexation ?
🎥 De la même vidéo 8
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 02/08/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.