Official statement
Other statements from this video 23 ▾
- □ Google compte-t-il vraiment tous les liens visibles dans Search Console ?
- □ Faut-il vraiment concentrer son contenu sur moins de pages pour ranker ?
- □ Les critères d'avis produits Google s'appliquent-ils même si votre site n'est pas classé comme site d'avis ?
- □ L'API Indexing de Google fonctionne-t-elle vraiment pour tous les contenus ?
- □ L'E-A-T influence-t-il vraiment le classement Google ou n'est-ce qu'un mythe ?
- □ Les mentions de marque sans lien ont-elles un impact sur votre référencement ?
- □ Les commentaires d'utilisateurs améliorent-ils vraiment le classement dans Google ?
- □ Les certificats SSL premium influencent-ils vraiment le référencement Google ?
- □ PDF et HTML avec le même contenu : faut-il craindre une cannibalisation dans les SERPs ?
- □ Peut-on vraiment piloter l'indexation des PDF via les headers HTTP ?
- □ Faut-il encore utiliser rel=next et rel=prev pour la pagination ?
- □ Googlebot peut-il vraiment indexer vos contenus en défilement infini ?
- □ Faut-il vraiment indexer toutes les pages de son site ?
- □ Faut-il vraiment rediriger l'ancien sitemap en 301 ou soumettre le nouveau directement ?
- □ Pourquoi 97% de crawl refresh est-il un signal positif pour votre site ?
- □ Comment Google détermine-t-il réellement la vitesse de crawl de votre site ?
- □ Vitesse de crawl et Core Web Vitals : pourquoi Google fait-il la distinction ?
- □ Pourquoi Google ralentit-il son crawl après un changement d'hébergement ?
- □ Le paramètre de taux de crawl est-il vraiment un plafond et non un objectif ?
- □ Le CTR peut-il vraiment pénaliser le reste de votre site ?
- □ Le maillage interne est-il vraiment l'élément le plus déterminant pour le SEO ?
- □ Le linking interne agit-il vraiment instantanément après recrawl ?
- □ Faut-il s'inquiéter si Google ne crawle pas toutes vos pages ?
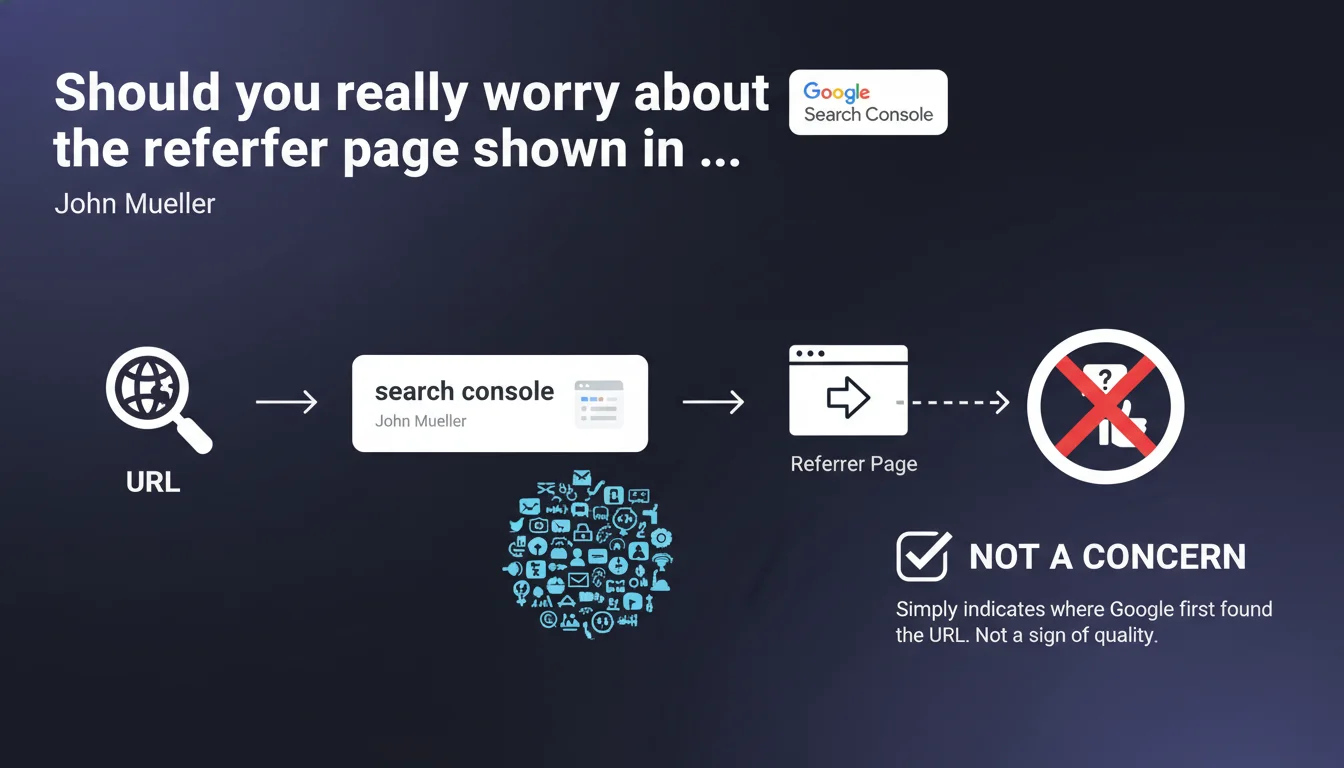
The referrer page in Search Console's URL inspection tool simply indicates where Google first discovered a URL. It's neither a quality signal nor a ranking criterion, even if the source seems dubious or random.
What you need to understand
What does this "referrer page" in Search Console really mean?
The referrer page in the URL inspection tool corresponds to the first occurrence detected by Google when crawling a given URL. It's simply a historical marker of discovery — nothing more.
Google keeps track of the first entry point through which Googlebot encountered this URL. It could be a link from your XML sitemap, from a page on your own site, or from a completely random external site. This information is purely informative.
Why does this data appear in Search Console?
Search Console displays this metadata to help webmasters understand how Google discovers their content. It's useful for tracing the origin of unexpected indexing or for understanding crawl paths.
But be careful: just because a URL was discovered via a third-party site doesn't mean that link carries any particular SEO weight. Google completely separates discovery from qualitative evaluation.
Does this referrer page influence my URL's ranking?
No. The referrer page has no direct impact on ranking. Google evaluates your page on its own merits: content, relevance, user signals, overall backlinks — not based on the first link that allowed it to be found.
If your URL was discovered via a spam site or a dubious directory, it won't penalize your page. Google crawls, indexes, then evaluates independently.
- The referrer page is a historical marker, not a quality signal
- It affects neither crawl budget nor page ranking
- Google separates discovery from SEO evaluation
- No need to panic if the source seems random or unreliable
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes, absolutely. We regularly observe that pages indexed via improbable sources (automatic aggregators, mirrors, scrapers) rank perfectly well if their content is solid. The referrer page is just a technical crawl detail.
On the other hand, some SEOs still confuse "first discovery" with "most important link". This Mueller statement sets the record straight: Google doesn't get sentimental about the origin of the crawl.
What nuances should be added?
Let's be honest: if your page is only discovered via dubious external sites, it could signal a structural problem — poor internal linking, missing XML sitemap, robots.txt blocking. The referrer page itself isn't problematic, but it can reveal an architectural flaw.
Another point: a page that appears nowhere in your own internal linking, but is crawled via an external backlink, is a red flag. Not because the backlink is "bad", but because you've probably orphaned this URL.
In what cases could this rule be misleading?
Mueller talks about "referrer page" in Search Console, but some third-party tools use the same term to designate the most influential link or the main "referring domain". Don't mix the two up.
GSC referrer page ≠ the backlink that transmits the most PageRank. It's just the first point of contact. [To verify]: Google doesn't publicly communicate how it weighs links in its graph after the initial discovery.
Practical impact and recommendations
What should you concretely do with this information?
Stop monitoring the referrer page as a KPI. It tells you nothing about your URL's SEO performance. Focus instead on metrics that matter: impressions, clicks, average position, crawl rate.
If you notice that a strategic URL was discovered via an external site rather than your own architecture, ask yourself: why didn't Google find it through your internal linking or XML sitemap?
What mistakes should you avoid?
Don't disavow a domain simply because it appears as a referrer page. That link may have no SEO weight and Google probably already ignores it in its ranking calculation.
Don't reorganize your site to "control" the referrer page. It's historical data frozen at the moment of first discovery. Even if you later add internal links, the referrer page won't change in Search Console.
How can you verify that your site is properly structured?
- Verify that all your strategic pages are present in your XML sitemap
- Audit your internal linking: no orphaned pages, reasonable click depth
- Use the URL inspection tool to validate that Google can crawl and index your priority content
- Monitor discovery patterns: if too many URLs are found via external sources, it's an architecture issue
- Ignore the referrer page as a quality signal — focus on overall backlinks and their thematic distribution
❓ Frequently Asked Questions
La page référente change-t-elle si je crée ensuite des liens internes vers cette URL ?
Si une page est découverte via un site de spam, dois-je désavouer ce lien ?
Peut-on forcer Google à utiliser une page référente spécifique ?
La page référente a-t-elle un lien avec le concept de "seed site" ou de "trusted domain" ?
Pourquoi certaines pages n'affichent-elles aucune page référente dans Search Console ?
🎥 From the same video 23
Other SEO insights extracted from this same Google Search Central video · published on 18/02/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.