Official statement
Other statements from this video 23 ▾
- □ Google compte-t-il vraiment tous les liens visibles dans Search Console ?
- □ Faut-il vraiment concentrer son contenu sur moins de pages pour ranker ?
- □ Les critères d'avis produits Google s'appliquent-ils même si votre site n'est pas classé comme site d'avis ?
- □ L'API Indexing de Google fonctionne-t-elle vraiment pour tous les contenus ?
- □ L'E-A-T influence-t-il vraiment le classement Google ou n'est-ce qu'un mythe ?
- □ Les mentions de marque sans lien ont-elles un impact sur votre référencement ?
- □ Les commentaires d'utilisateurs améliorent-ils vraiment le classement dans Google ?
- □ Les certificats SSL premium influencent-ils vraiment le référencement Google ?
- □ PDF et HTML avec le même contenu : faut-il craindre une cannibalisation dans les SERPs ?
- □ Peut-on vraiment piloter l'indexation des PDF via les headers HTTP ?
- □ Faut-il encore utiliser rel=next et rel=prev pour la pagination ?
- □ Googlebot peut-il vraiment indexer vos contenus en défilement infini ?
- □ Faut-il vraiment indexer toutes les pages de son site ?
- □ Faut-il s'inquiéter de la page référente affichée dans Google Search Console ?
- □ Faut-il vraiment rediriger l'ancien sitemap en 301 ou soumettre le nouveau directement ?
- □ Comment Google détermine-t-il réellement la vitesse de crawl de votre site ?
- □ Vitesse de crawl et Core Web Vitals : pourquoi Google fait-il la distinction ?
- □ Pourquoi Google ralentit-il son crawl après un changement d'hébergement ?
- □ Le paramètre de taux de crawl est-il vraiment un plafond et non un objectif ?
- □ Le CTR peut-il vraiment pénaliser le reste de votre site ?
- □ Le maillage interne est-il vraiment l'élément le plus déterminant pour le SEO ?
- □ Le linking interne agit-il vraiment instantanément après recrawl ?
- □ Faut-il s'inquiéter si Google ne crawle pas toutes vos pages ?
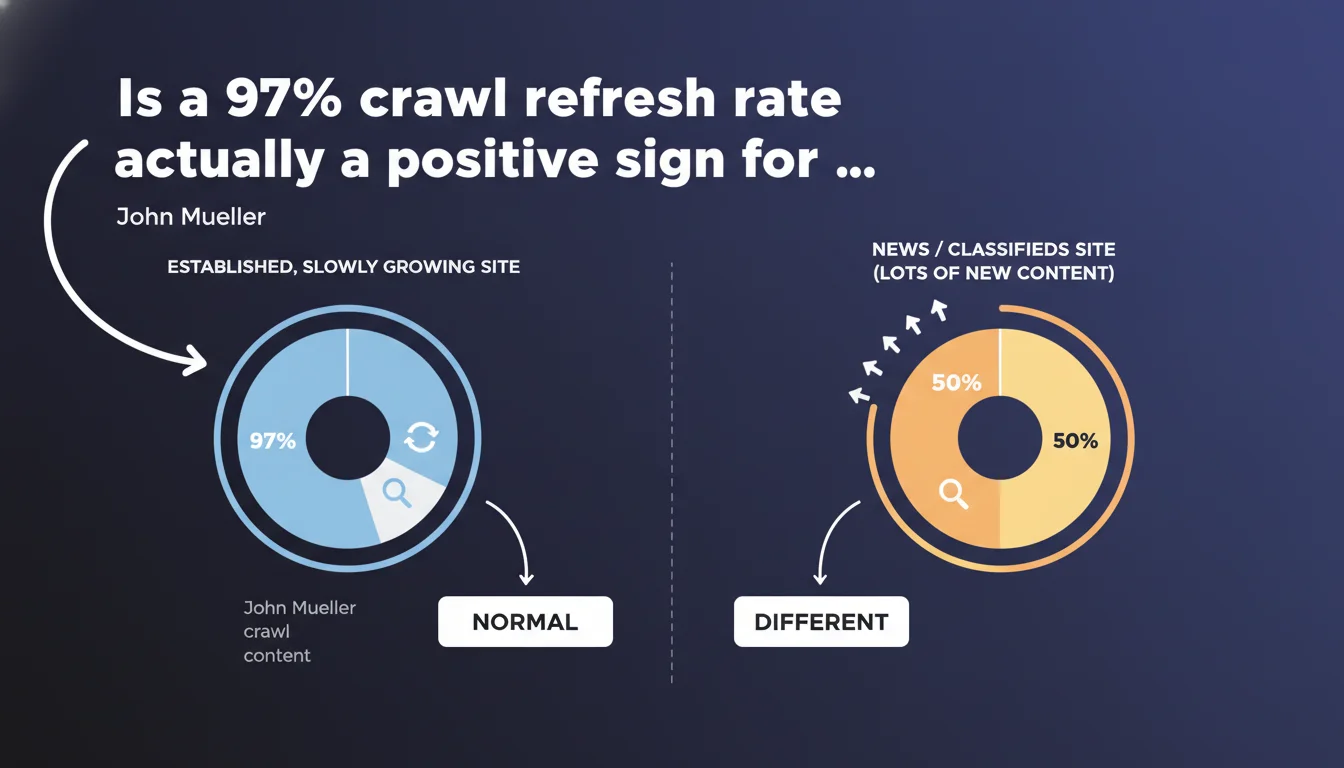
Google confirms that an established site with normal organic growth typically displays 97% crawl refresh versus only 3% discovery. This distribution is not a problem — it's a sign of maturity. News sites or classifieds with massive streams of new content show inverted ratios, but this isn't the norm for most websites.
What you need to understand
What's the difference between crawl refresh and discovery crawl?
The crawl refresh refers to Googlebot's passage over already known and indexed URLs to check whether content has changed. Discovery crawl, meanwhile, concerns new URLs never visited before.
John Mueller clarifies that a 97/3 ratio is normal for an established site that evolves gradually. Many SEOs panic at these figures in Search Console, thinking Google is ignoring their new content. This is a misreading.
Why does this ratio vary depending on site type?
A news site or classifieds generates hundreds or thousands of URLs daily. The ratio then tilts toward discovery — logically, since the volume of new content explodes.
A corporate site, standard e-commerce platform, or blog adding 10-20 pages per month? The bulk of crawl budget focuses on refreshing existing content. It's mathematical: 500 established pages spread over 30 days = lots of refresh, little discovery.
Does this distribution mean my new content is being ignored?
No. 3% discovery on a site crawled 10,000 times per week = 300 crawls of new URLs. More than enough to index your new articles or product pages.
The problem doesn't come from the ratio but from signal quality: poor internal linking, outdated XML sitemap, orphaned content. If your new pages take 3 weeks to index, it's not because of the refresh/discovery ratio.
- A 97/3 ratio is normal and healthy for an established site with moderate growth
- High-volume sites (news, classifieds) show inverted ratios — but these are special cases
- Crawl refresh allows Google to detect content updates on existing pages, which remains critical for freshness
- A refresh-heavy ratio doesn't prevent rapid indexing if your site architecture is clean
SEO Expert opinion
Is this statement consistent with what we observe in the field?
Yes, completely. Clients who contact me in panic with a 95/5 ratio often have a 200-300 page site publishing 2 articles per week. They compare their metrics to a media outlet pushing 50 pieces daily — an absurd comparison.
The problem is that Google provides no benchmarked figures in Search Console. SEOs interpret this data without context and jump to hasty conclusions. Mueller finally provides a frame of reference.
What nuances should we apply to this rule?
An established site that suddenly adds 500 pages (redesign, new section, migration) should see its ratio temporarily shift. If it doesn't budge, that's where you have a problem — poor linking, unsubmitted sitemap, crawl budget saturated by useless facets.
Another point: Mueller talks about a "slowly growing site." What does "slowly" mean? [To verify] — no precise metric. 10 pages/month? 50? The wording remains vague.
Finally, this statement says nothing about refresh frequency. A site crawled 50 times/day for refresh is excellent. A site crawled twice per week with 97% refresh might signal Google's disinterest in your content. The ratio alone isn't enough.
In which cases should this ratio alert us?
If you launch a major content initiative (100+ new pages) and the ratio stays stuck at 97/3 after 4 weeks, dig deeper. Either your internal linking fails or your new URLs are technical (filters, pagination) and Google marks them as low-value.
Practical impact and recommendations
What should you concretely do with this information?
First, stop panicking over a 95/5 ratio if your site publishes 3 pages per week. It's normal. Focus instead on the average indexation lag of your new URLs — a far more actionable metric.
Next, verify your new content is properly linked from frequently crawled pages (homepage, category hubs). An orphaned page will never appear in discovery crawl, no matter its quality.
What mistakes should you avoid after this statement?
Don't try to "force" a higher discovery ratio by publishing low-grade content just to drive volume. Google will lower its crawl budget allocation if you flood the index with weak pages.
Also avoid blocking crawl refresh via robots.txt or meta noindex on established pages to "free up budget." Refresh lets Google catch your updates — it's a freshness signal essential, especially on commercial pages.
How do you optimize crawl to maximize useful discovery?
Submit your new content via the Indexing API (if eligible) or at least via a daily-updated XML sitemap. Add a "Latest articles" block on your homepage or main menu to guarantee a direct link.
Monitor server logs to spot URLs crawled in loops with no value (facets, session parameters, duplicates). Block them properly to concentrate budget on strategic content.
- Check your site's refresh/discovery ratio in Search Console
- Compare this ratio to your actual publishing pace (pages/month)
- Analyze average indexation lag for new URLs — if >7 days, investigate internal linking
- Ensure your XML sitemap updates automatically with each new page
- Audit server logs to spot useless crawls (facets, duplicates, parameters)
- Deploy internal links from high-crawl pages to new content
- Avoid blocking refresh on established pages — it's counterproductive
❓ Frequently Asked Questions
Un ratio 99% refresh / 1% découverte est-il inquiétant ?
Comment calculer le ratio refresh/découverte de mon site ?
Faut-il bloquer le crawl refresh pour libérer du budget découverte ?
Les sites e-commerce doivent-ils avoir un ratio différent ?
Comment forcer Google à crawler mes nouvelles pages plus vite ?
🎥 From the same video 23
Other SEO insights extracted from this same Google Search Central video · published on 18/02/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.