Official statement
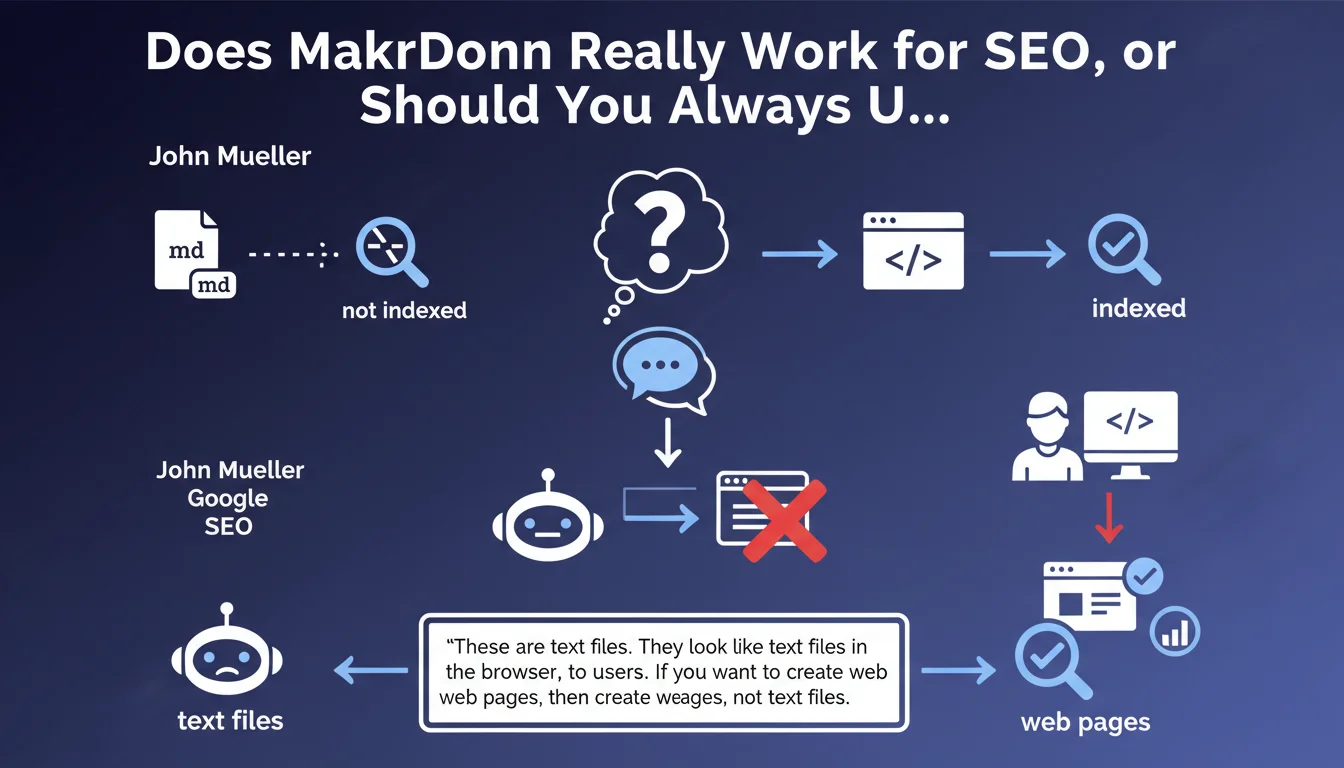
His answer: "These are text files. They look like text files in the browser, to users. If you want to create web pages, then create web pages, not text files."
John Mueller is unequivocal: .md files (Markdown) are plain text only for Googlebot and browsers. If you're creating web pages, use standard HTML, not text files. Markdown is not a viable substitute for HTML when pages are meant to be indexed.
What you need to understand
Why is this question being asked today?
Markdown has become ubiquitous in the modern development ecosystem — GitHub, static site generators, documentation systems. Some tools automatically convert .md to HTML, creating confusion: does Google index Markdown files directly?
Mueller's answer is clear-cut. For Googlebot, a .md file is a plain text file, exactly like a .txt. No semantic markup, no interpretable HTML structure, no exploitable SEO signals.
What's the fundamental difference between Markdown and HTML for Google?
HTML provides semantic structure: title tags (h1, h2), paragraphs, lists, links with attributes, metadata. Googlebot relies on this architecture to understand content hierarchy and extract relevance signals.
A raw Markdown file contains only text with lightweight formatting syntax. Without server-side conversion to HTML, there's no structure exploitable by the search engine. The browser displays it as plain text — and that's exactly what Google sees.
When can Markdown actually work for SEO?
If your tool (Jekyll, Hugo, Next.js, Gatsby) compiles Markdown to HTML at build time, then Google indexes the final HTML result, not the .md source file. This is a crucial distinction that Mueller doesn't elaborate on here.
The problem isn't the source format, but what's delivered to the browser. If you expose .md files directly without transformation, it's SEO suicide.
- Raw .md files are treated as plain text by Google
- No semantic structure exploitable without HTML conversion
- Static site generators that compile Markdown → HTML are acceptable
- What matters: what Googlebot receives, not what you write locally
- Don't confuse authoring format with delivery format
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes, and it's actually one of Mueller's rare messages that leaves no gray area. Empirical testing confirms it: serving raw .md = poor indexation or none at all, no rich snippets, no hierarchy understanding.
Where it gets tricky is that many developers confuse writing in Markdown with serving Markdown. You can write all your documentation in .md — as long as your build pipeline generates clean HTML, Google doesn't care about the source format.
What are the real limitations of this statement?
Mueller intentionally simplifies, but there are edge cases. Some GitHub repositories in .md are indexed — because GitHub serves a rendered HTML view of the file, with metadata and structure. It's not the raw file that Google crawls, it's the web page generated around it.
Similarly, if you use a service like GitBook or Read the Docs, Markdown is automatically transformed into semantic HTML. The initial format doesn't matter at all.
[To verify]: No official data on how Google handles .md files served with Content-Type text/html + client-side transformation. Probably ignored or poorly indexed, but no large-scale published testing.
Should you completely abandon Markdown for SEO?
No, and that's where Mueller's statement can be misleading. Markdown is an excellent authoring format — readable, versionable, portable. It just should never be the final format served to the browser.
Use it in your workflow (writing, Git versioning, collaboration), but make sure your technical stack compiles everything to HTML before production. That's what all modern headless CMS platforms and performant static generators do.
Practical impact and recommendations
How do you verify if your site serves raw Markdown or HTML?
Open your browser inspector (F12) and check the Network tab. Load a suspect page and verify the Content-Type of the HTTP response. If you see text/plain or text/markdown, that's a problem. You should see text/html.
Another method: view the source (Ctrl+U). If you see text with # for titles and ** for bold, Markdown isn't compiled. If you see <h1>, <p>, <strong> tags, you're good.
What if you're using a static site generator?
No changes needed if your build pipeline works correctly. Jekyll, Hugo, Eleventy, Astro — they all compile Markdown to HTML at build time. Just verify that your deployment serves the generated .html files, not the source .md.
For Next.js or Nuxt sites with MDX, make sure rendering happens server-side (SSR) or at generation time (SSG), not client-side only. The final HTML must be available on first load.
What mistakes should you absolutely avoid?
Never configure your server to serve .md files directly with Content-Type text/html without transformation. Some developers think renaming the extension is enough — it's not.
Also avoid JavaScript plugins that transform Markdown client-side after loading. Google can execute JS, but you're creating unnecessary dependency and indexation risks if the script fails.
- Verify that all your pages are served with Content-Type: text/html
- Inspect page source code: presence of semantic HTML tags
- Test your URLs in Google Search Console → URL Inspection
- If you use an SSG, confirm the build generates .html files
- Block raw .md file indexation with robots.txt if necessary
- Audit your templates for h1-h6 structure, meta tags, schema.org
- Never rely on Markdown transformation client-side alone
💬 Comments (1)
J'imagine que vous utiliser un RAG pour stocker l'ensemble des informations officielles du moteur de recherche pour ensuite les traduire et les clusteriser automatiquement ?
Si c'est le cas, est-ce que l'étape finale, qui serait à mon avis vraiment utile et pertinente pour l'ensemble de vos lecteurs, ne serait pas de leur permettre d'interroger l'ensemble de vos documents en langage naturel via un chatbot qui récupère les informations stockées dans votre base de données vectorielles afin de répondre de manière sourcée aux questions des utilisateurs ? C'est ce que je fais moi par exemple sur mon site : https://julien-gourdon.fr/chatbot-seo, mais y a sans doute moyen de faire :)
Encore bravo !