Official statement
Other statements from this video 22 ▾
- □ Why doesn't Google Search Console's average position reflect a theoretical ranking but actual display results instead?
- □ Can you really afford to wait for an unstable ranking to stabilize on its own?
- □ Does boosting your SEO really require producing more content?
- □ Does the location of your XML sitemap really affect crawl efficiency?
- □ Should you really use the URL inspection tool to index a brand new website?
- □ How long does it really take to see your new backlinks in Google Search Console?
- □ Why do Search Console and Analytics data never really match up?
- □ Should you really prefer noindex over disallow to control indexation in Google?
- □ Can out-of-stock product pages really trigger soft 404 errors in Google's eyes?
- □ Do Google's testing tools really crawl in real-time or do they rely on cached data?
- □ Does Google really use different ranking algorithms depending on your industry?
- □ Why does Google deprioritize crawling low-effort aggregator sites?
- □ Does Google really count clicks on rich results the same way as organic clicks?
- □ Does the order of links in your HTML code really affect Google's crawl priority?
- □ Should you really avoid URLs with parameters for SEO?
- □ Why does robots.txt prevent Google from crawling your pages but still allow them to be indexed?
- □ Are out-of-stock products hurting your e-commerce site's overall search rankings?
- □ Does partial duplicate content really hurt your search rankings?
- □ Does Google really ignore your canonical tags when it decides pages are too similar?
- □ Does Google really use just one signal to choose which URL to canonicalize among your duplicate content?
- □ Do brand mentions without backlinks actually help your SEO rankings?
- □ Why does a link without an indexed URL essentially do nothing for your SEO?
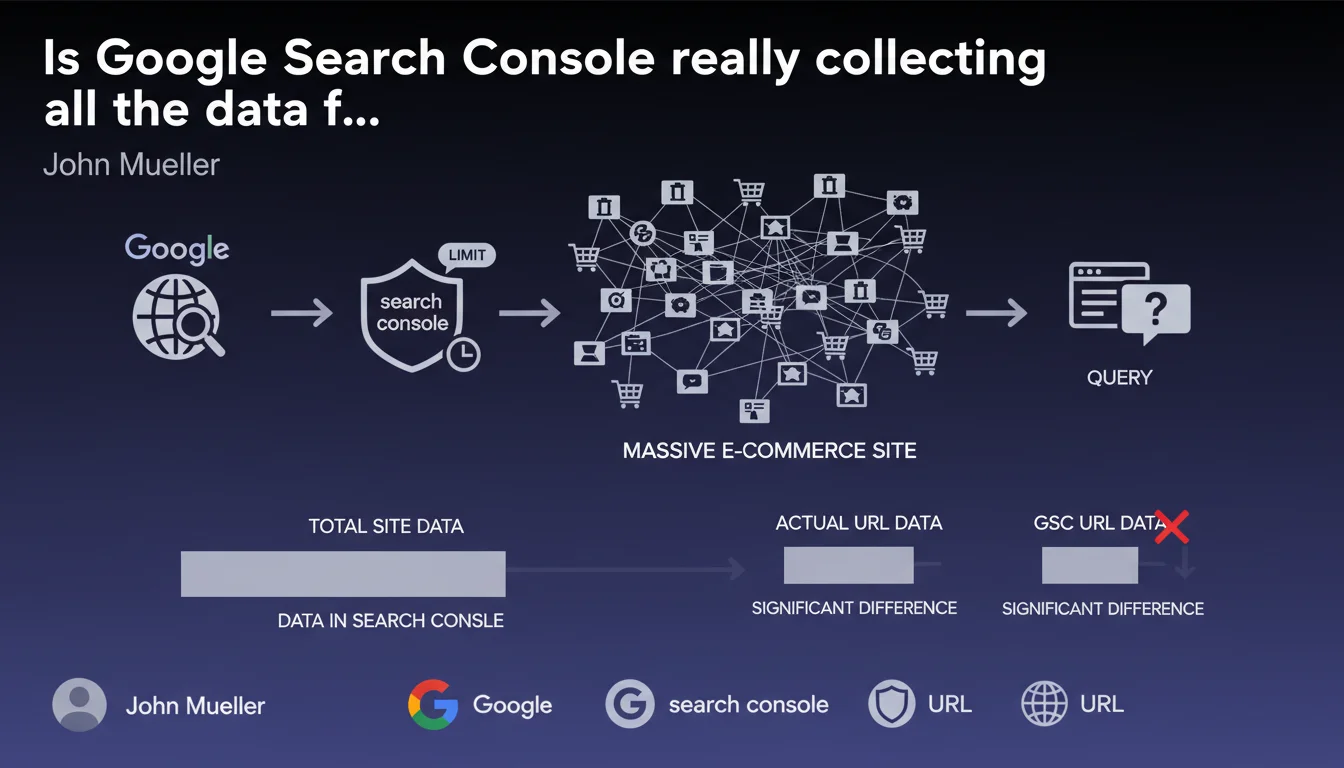
Google Search Console imposes daily data collection limits on very large e-commerce sites. If you analyze performance at the URL or individual query level, the displayed figures may be incomplete and show significant discrepancies compared to reality. Your dashboards only show part of the picture.
What you need to understand
What are these collection limits Mueller is talking about?
Google Search Console does not record the entirety of search events on massive sites. There is a daily collection ceiling that varies depending on site size and organic traffic volume.
Concretely, if your catalog contains hundreds of thousands of products with as many distinct URLs, GSC will sample the data. Certain pages or queries will appear with impressions, others won't — not because they didn't perform, but because they fell outside the quota.
Why is this limit problematic in practice?
The impact becomes critical when you attempt to optimize at a granular level. You export a report by URL or by query to identify opportunities — and you discover gaping holes in your data.
Long-tail analysis becomes unreliable. Pages with few impressions can completely disappear from the radar, even though they might be contributing to your revenue. This uncertainty skews SEO prioritization.
How do you know if your site is affected?
Mueller speaks of "very large e-commerce sites." No specific threshold, but field experience suggests that sites beyond 100,000 indexable URLs begin to encounter these limitations.
If you notice significant variations between your server logs and GSC data, or if entire categories seem underrepresented in reports, you are likely capped.
- GSC applies daily collection quotas on very large sites
- URL-level and query-level reports are most impacted by sampling
- Sites exceeding 100k indexable URLs are the first to be affected
- Discrepancies between server logs and GSC are a warning signal
- This limit does not affect crawling or indexation — only data visibility
SEO Expert opinion
Is this limitation really technically justified?
Let's be honest: Google processes billions of queries per day and stores astronomical amounts of data. Capping GSC data collection on a few hundred thousand URLs seems... arbitrary.
The technical argument holds up — storing and exposing granular data for every giant e-commerce site represents a significant infrastructure cost. But other analytics tools handle these volumes without breaking a sweat. It's probably more a matter of product priority than a real technical impossibility.
What data actually remains reliable in GSC?
Aggregated views — overall site performance, monthly trends — remain usable. It's at the micro level that things break down: analysis by specific URL, long-tail queries, cannibalization detection.
For deep SEO audits, you need to cross-reference GSC with other sources: server logs, Google Analytics 4, third-party tools like Semrush or Sistrix. GSC becomes one piece of the puzzle, not absolute truth.
[To verify] : Google publishes nowhere the exact thresholds of these quotas, nor the sampling methodology. It's impossible to know if certain site sections are systematically underrepresented or if it's purely random.
In what cases does this statement really change the game?
If you manage a media site or blog, even with 50,000 articles, you probably won't see these limits. E-commerce sites with massive catalogs and multiple product variants are the real victims.
The problem worsens if your SEO strategy relies on optimizing thousands of low-traffic individual product pages. You're flying blind on part of your inventory.
Practical impact and recommendations
How do you work around these collection limitations?
First priority: set up server log analysis. This is the only exhaustive source that captures 100% of Googlebot visits and actual organic clicks. Tools like Oncrawl, Botify, or homemade scripts on your Apache/Nginx logs.
Then cross-reference GSC with GA4 by filtering the organic channel. Discrepancies will indicate the extent of sampling. If GA4 reports 30% more organic traffic in certain categories, you know GSC is underreporting that area.
For query analysis, use third-party tools that pull their own SERP data — not perfect, but it gives complementary insight into average positions and search volumes.
What errors should you avoid in data interpretation?
Never draw definitive conclusions about a specific URL or query based solely on GSC if your site exceeds 100k pages. "Zero impressions" could simply mean data not collected.
Also avoid directly comparing two periods at a granular level — sampling can vary week to week. Macro trends remain valid, but micro-fluctuations are noisy.
Never deindex a page because GSC shows zero performance. Check your server logs first to confirm it's truly receiving no organic traffic.
What should you concretely do to effectively manage a large site?
- Deploy a server log analysis solution to capture 100% of crawls and traffic
- Systematically cross-reference GSC with GA4 and logs to detect collection gaps
- Use third-party tools (Semrush, Ahrefs, Sistrix) to supplement query data
- Segment the site into priority zones and analyze each segment separately
- Automate GSC API exports to maintain untruncated historical data
- Prioritize aggregated analysis (categories, product families) over URL-by-URL
- Document known limitations in your reporting to prevent misinterpretation
❓ Frequently Asked Questions
À partir de combien d'URLs Search Console commence-t-il à échantillonner les données ?
Les données de performance globale du site sont-elles fiables malgré ces limites ?
Peut-on augmenter le quota de collecte GSC en contactant Google ?
Les logs serveur donnent-ils vraiment une vision complète si GSC est limité ?
Cette limitation impacte-t-elle le crawl ou l'indexation des pages ?
🎥 From the same video 22
Other SEO insights extracted from this same Google Search Central video · published on 28/03/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.