Official statement
Other statements from this video 22 ▾
- □ Pourquoi la position moyenne de Search Console ne reflète-t-elle pas un classement théorique mais des affichages réels ?
- □ Peut-on encore se permettre d'attendre qu'un classement instable se stabilise tout seul ?
- □ Faut-il vraiment produire plus de contenu pour améliorer son SEO ?
- □ Où placer son sitemap XML pour optimiser son crawl ?
- □ Faut-il vraiment utiliser l'outil d'inspection d'URL pour indexer un nouveau site ?
- □ Combien de temps faut-il attendre pour voir les backlinks dans Search Console ?
- □ Pourquoi les données Search Console et Analytics ne concordent-elles jamais vraiment ?
- □ Search Console collecte-t-elle vraiment toutes les données sur les gros sites e-commerce ?
- □ Faut-il vraiment préférer noindex à disallow pour contrôler l'indexation ?
- □ Les produits en rupture de stock peuvent-ils vraiment être traités comme des soft 404 par Google ?
- □ Les outils de test Google crawlent-ils vraiment en temps réel ou utilisent-ils un cache ?
- □ Google utilise-t-il des algorithmes différents selon votre secteur d'activité ?
- □ Google compte-t-il vraiment les clics sur les rich results comme des clics organiques ?
- □ L'ordre des liens dans le HTML influence-t-il vraiment la priorité de crawl de Google ?
- □ Faut-il vraiment éviter les URLs avec paramètres pour le SEO ?
- □ Pourquoi robots.txt bloque le crawl mais n'empêche pas l'indexation de vos pages ?
- □ Les produits en rupture de stock nuisent-ils au classement global de votre site e-commerce ?
- □ Le contenu dupliqué partiel pénalise-t-il vraiment vos pages ?
- □ Pourquoi Google refuse-t-il d'indexer plusieurs versions d'une même page malgré une canonicalisation correcte ?
- □ Comment Google choisit-il réellement quelle URL canoniser parmi vos contenus dupliqués ?
- □ Les mentions de marque sans lien ont-elles une valeur SEO ?
- □ Pourquoi un lien sans URL indexée ne sert strictement à rien ?
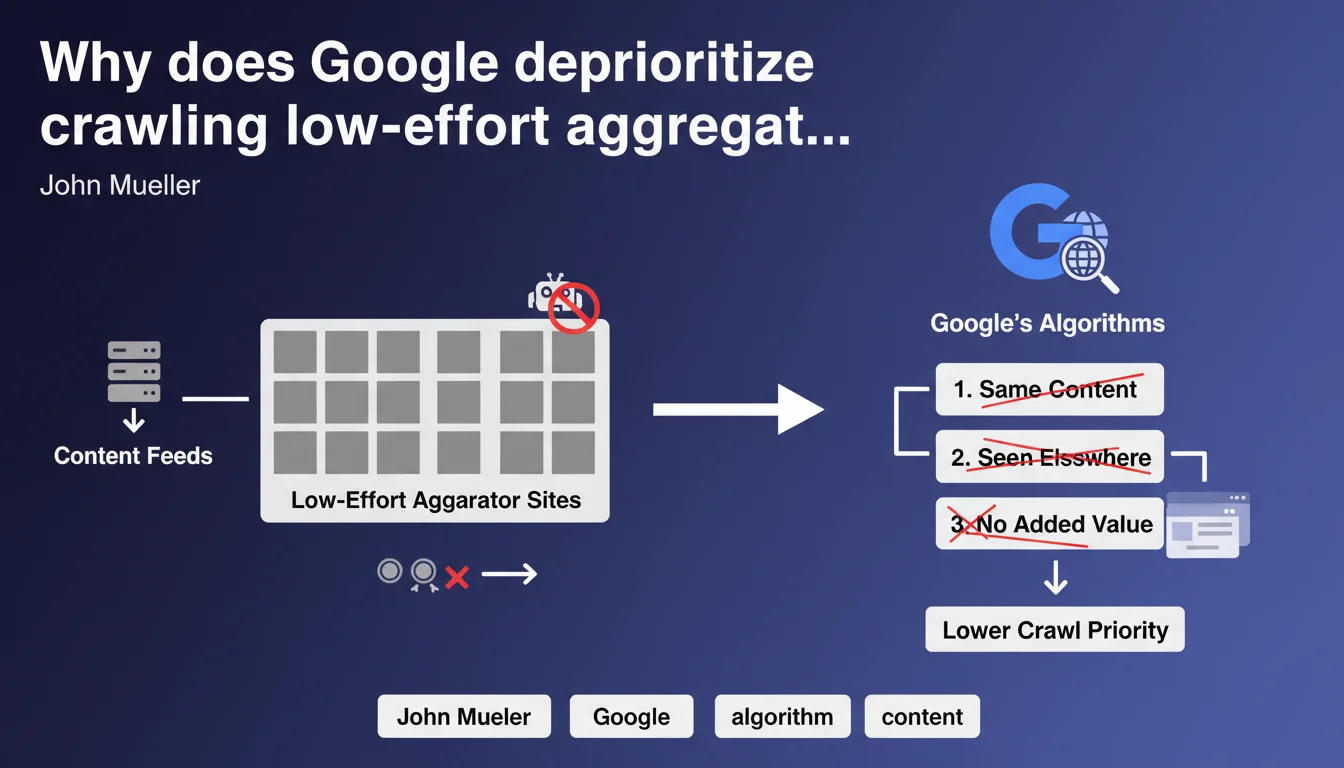
Google does not prioritize crawling and indexing aggregator sites that simply republish content feeds already available elsewhere. The position is clear: if your platform merely duplicates content without adding value, you won't be in algorithmic priorities. This directly impacts crawl budget and organic visibility.
What you need to understand
John Mueller confirms a reality that many aggregators discover the hard way: Google does not invest resources in crawling and indexing content already present elsewhere on the web. This statement specifically targets sites that automate RSS feed retrieval, API scraping, or web scraping without editorial enrichment.
The term "low-effort" deserves attention. It's not solely about technical duplication, but a qualitative assessment of content handling. An aggregator can technically modify a feed while remaining in this category if human or algorithmic intervention stays minimal.
What constitutes a low-effort aggregator in Google's view?
Google targets platforms that automatically republish content from third-party sources without significant processing. This includes real estate listing sites that duplicate MLS feeds, job portals pulling offers from APIs, or price comparison sites displaying product sheets identical to those from source e-commerce merchants.
The decisive criterion remains unique value contribution. If your content is interchangeable with the original source, you're in the red zone. Simple visual restructuring or adding a search filter isn't enough to escape this category.
How does Google detect these sites?
Combined signals enable this identification: large-scale textual similarity analysis, publication patterns (massive real-time volumes), absence of distinctive user behavior, low editorial refresh rate outside automated feeds.
Algorithms also measure the semantic distance between your version and the sources. Simple spinning or automatic paraphrasing fools no one — Google's language models have detected these manipulations for years.
What are the concrete consequences for indexation?
Concretely, your site experiences drastically reduced crawl budget. Google crawls less frequently, indexes fewer pages, and even indexed URLs benefit from low refresh priority. You notice indexation delays of weeks or even months for new content.
The cascading effect also touches rankings. Even when indexed, your pages systematically lose to original sources in SERPs. Google systematically prefers returning users to content creators rather than to intermediaries with no added value.
- Limited crawl budget for aggregators without differentiation
- Systematic prioritization of original sources in search results
- Detection based on textual similarity and publication patterns
- Simple visual reformatting does not constitute sufficient added value
- Measurable impact on indexation delays and crawl frequency
SEO Expert opinion
Is this statement consistent with real-world observations?
Absolutely. We've observed for years that aggregators struggle to maintain organic visibility, especially in competitive verticals. Real estate listing sites, job portals, and price comparison platforms experience progressive erosion of organic traffic if they don't offer substantial editorial layers.
The important nuance: some aggregators still perform well, but they invest heavily in curation, user reviews, editorialized comparisons, buying guides. They don't simply republish — they transform and contextualize. The difference between Leboncoin (which works) and random scrapers (which stagnate) lies in this value layer.
What gray areas remain in this statement?
Mueller doesn't specify the minimum threshold of transformation to escape the "low-effort" category. How many original words must you add? What proportion of content must be unique? These metrics remain fuzzy. [To verify]: Google teams have never communicated precise ratios, leaving operators uncertain.
Another murky point: the distinction between aggregation and authorized syndication. Some publishers voluntarily distribute their content through partners with canonical tags or licenses. Does Google treat these cases differently? Practice shows that even with canonical, a site that merely republishes remains penalized in visibility — only indexation gets deduplicated, not ranking.
In what cases does this rule not fully apply?
High-traffic vertical aggregators sometimes receive different treatment. Google seems more tolerant of duplication when the site shows strong engagement signals: high session duration, low bounce rate, multi-page navigation. The engine interprets these behaviors as validation of usefulness despite duplicated content.
Platforms with interactive features (calculators, simulators, dynamic comparison tools) also partially escape this logic. Even if textual content remains duplicated, the tool itself constitutes differentiating value that Google seems to factor into prioritization criteria.
Practical impact and recommendations
What should you do concretely if you operate an aggregator?
First priority: audit the ratio of original content vs duplicated on your strategic pages. Identify templates where you republish feeds without modification. These pages are your main vulnerability points. Measure the percentage of text truly created by your team or users.
Next, systematically enrich each aggregated content entry. Add verified user reviews, editorialized comparisons, historical price analysis, contextual guides. The objective: ensure your version provides 30-40% additional content minimum compared to the source.
If your business model relies on large automated volumes, rethink your information architecture. Create category pages with strong editorial content, original thematic hubs, exclusive resources. Leave individual product pages in noindex if they're purely duplicated, and concentrate crawl budget on URLs with added value.
What mistakes must you absolutely avoid?
Don't fall into the automatic spinning trap. Replacing synonyms or restructuring sentences via generative AI without human oversight doesn't fool Google — and often degrades perceived quality. Algorithms detect these manipulations and may harden their treatment of your site.
Also avoid blocking crawl of original sources hoping to become the default reference. Google considers this manipulation and may apply manual penalties. Several documented cases show penalties for this type of practice.
Don't neglect user signals. An aggregator with 80% bounce rate and 15-second session duration confirms to Google that your version adds nothing. Invest in UX, navigation, features that encourage staying and exploring.
How do you verify your site isn't classified as a low-effort aggregator?
Monitor your indexation rate in Search Console. If you publish 1000 new URLs daily but only 10% get indexed after a month, that's a red flag. Compare indexation speed of your original editorial pages vs your aggregated pages — the gap reveals algorithmic treatment.
Analyze the distribution of organic traffic. If 90% of visits come from 5% of pages (editorial pages), while millions of aggregated sheets generate nothing, you have confirmation of the problem. Google votes with clicks.
Test crawl freshness on representative samples. Modify elements on aggregated pages and measure the delay before Google reflects changes. Delays exceeding 2-3 weeks on theoretically important pages indicate low algorithmic priority.
- Measure the ratio of unique vs duplicated content on each page type
- Systematically enrich aggregated content with analysis, reviews, comparisons
- Restructure architecture to concentrate crawl on value-added pages
- Absolutely avoid automatic spinning without human supervision
- Monitor indexation rate and crawl delays as priority KPIs
- Invest in user signals: session duration, navigation, engagement
- Prioritize interactive features that create real differentiation
Transforming a classic aggregator into a value-added platform requires deep strategic overhaul: editorial reorganization, technical investment in differentiating tools, information architecture restructuring. These projects can quickly become complex, especially when maintaining existing revenue during transition.
Many operators underestimate the scope of changes needed to escape the "low-effort" category. Support from an SEO agency specialized in aggregation challenges helps avoid costly missteps and accelerates transformation toward a sustainable model aligned with Google's algorithmic expectations.
❓ Frequently Asked Questions
Un agrégateur peut-il utiliser du contenu dupliqué si les sources donnent leur autorisation ?
Combien de contenu original faut-il ajouter pour sortir de la catégorie faible effort ?
Les avis utilisateurs suffisent-ils comme valeur ajoutée sur un agrégateur ?
Faut-il mettre en noindex les pages agrégées sans contenu unique ?
Comment Google distingue-t-il un agrégateur d'une marketplace légitime ?
🎥 From the same video 22
Other SEO insights extracted from this same Google Search Central video · published on 28/03/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.