Official statement
Other statements from this video 22 ▾
- □ Pourquoi la position moyenne de Search Console ne reflète-t-elle pas un classement théorique mais des affichages réels ?
- □ Peut-on encore se permettre d'attendre qu'un classement instable se stabilise tout seul ?
- □ Faut-il vraiment produire plus de contenu pour améliorer son SEO ?
- □ Où placer son sitemap XML pour optimiser son crawl ?
- □ Faut-il vraiment utiliser l'outil d'inspection d'URL pour indexer un nouveau site ?
- □ Combien de temps faut-il attendre pour voir les backlinks dans Search Console ?
- □ Pourquoi les données Search Console et Analytics ne concordent-elles jamais vraiment ?
- □ Search Console collecte-t-elle vraiment toutes les données sur les gros sites e-commerce ?
- □ Faut-il vraiment préférer noindex à disallow pour contrôler l'indexation ?
- □ Les produits en rupture de stock peuvent-ils vraiment être traités comme des soft 404 par Google ?
- □ Les outils de test Google crawlent-ils vraiment en temps réel ou utilisent-ils un cache ?
- □ Google utilise-t-il des algorithmes différents selon votre secteur d'activité ?
- □ Pourquoi Google ignore-t-il les sites agrégateurs de faible effort ?
- □ Google compte-t-il vraiment les clics sur les rich results comme des clics organiques ?
- □ L'ordre des liens dans le HTML influence-t-il vraiment la priorité de crawl de Google ?
- □ Faut-il vraiment éviter les URLs avec paramètres pour le SEO ?
- □ Pourquoi robots.txt bloque le crawl mais n'empêche pas l'indexation de vos pages ?
- □ Les produits en rupture de stock nuisent-ils au classement global de votre site e-commerce ?
- □ Le contenu dupliqué partiel pénalise-t-il vraiment vos pages ?
- □ Pourquoi Google refuse-t-il d'indexer plusieurs versions d'une même page malgré une canonicalisation correcte ?
- □ Les mentions de marque sans lien ont-elles une valeur SEO ?
- □ Pourquoi un lien sans URL indexée ne sert strictement à rien ?
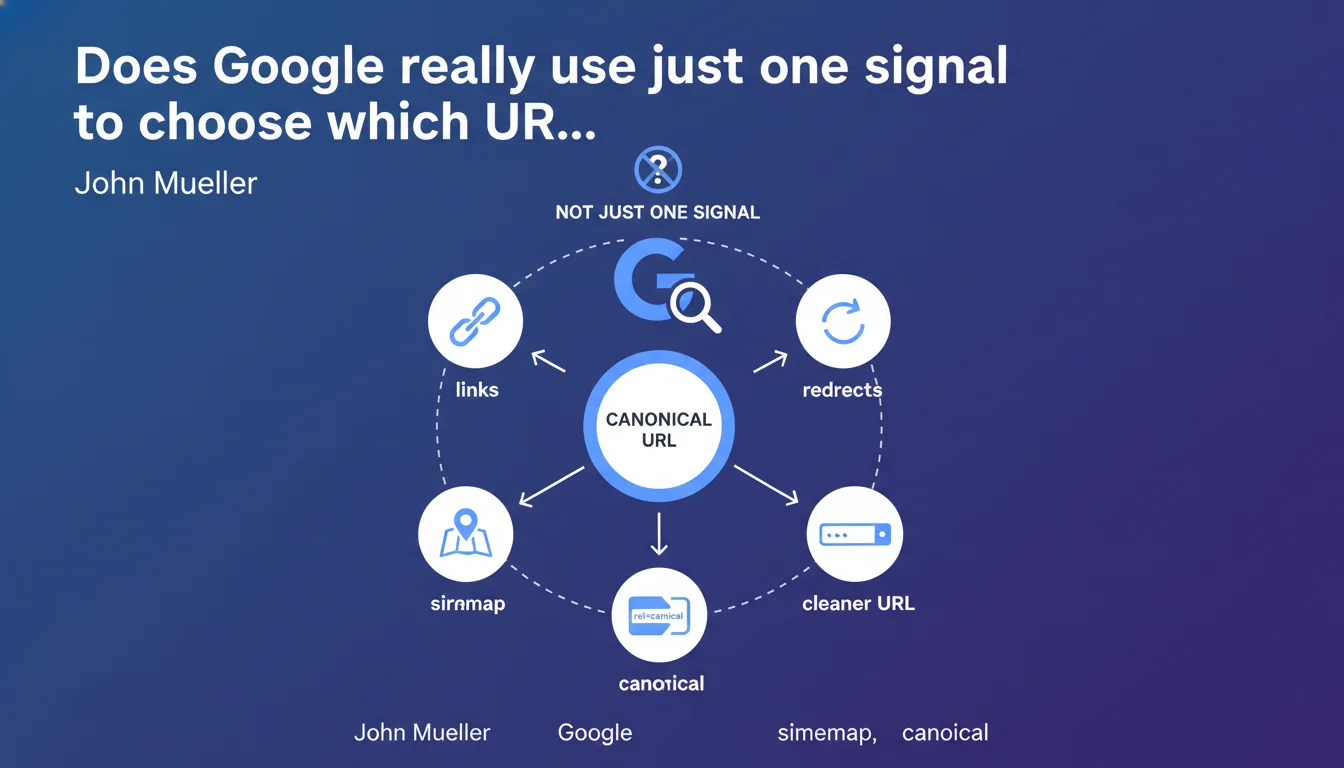
Google doesn't rely on a single signal to determine the canonical URL. The decision is based on a set of factors: rel canonical, internal/external links, presence in the sitemap, redirects, and even the perceived 'clarity' of the URL. No single signal has absolute weight — Google aggregates and arbitrates between them.
What you need to understand
Why doesn't Google blindly follow rel=canonical?
Because rel=canonical is one signal among many, not an absolute directive. Google treats it as a strong recommendation, but the search engine can decide to ignore it if other signals point in the opposite direction.
In practice, if you declare URL A as canonical, but all your internal and external links point to URL B, your sitemap lists B, and a 301 redirect leads to B, Google will likely choose B. The engine seeks consistency — and when signals diverge, it makes a decision based on an internal weighting system.
What does 'which URL appears cleaner or clearer' really mean?
This is one of the fuzziest points in that statement. Google evaluates the URL structure itself: a short, readable URL without unnecessary parameters will be favored over a long URL with query strings.
Typical example: example.com/product-a beats example.com/index.php?id=123&ref=abc. But be careful — [To verify] — this rule has never been publicly quantified. We don't know what exact weight Google gives to this criterion versus an explicit rel=canonical.
What are the canonicalization signals you need to master?
- Rel=canonical in the
<head>or HTTP header - Internal links: which version are you linking to massively?
- External links: which URL do third-party sites cite?
- XML sitemap: list only canonical URLs
- 301/302 redirects: they consolidate signals toward a single version
- URL structure: prioritize short, descriptive URLs without unnecessary parameters
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes, completely. In the field, we regularly observe cases where Google ignores the declared rel=canonical. Typically: a site migrates from HTTP to HTTPS, declares HTTPS canonicals, but continues receiving backlinks to the old HTTP URLs — and Google sometimes still indexes the HTTP version.
Another classic case: multilingual sites with poorly configured hreflang tags. Google can choose an unexpected language version as canonical if internal signals (links, sitemap) don't converge toward the right version.
What nuances should be added to this statement?
Google doesn't detail the weighting of each signal. Is a rel=canonical worth as much as a sitemap entry? More than an internal link? Less than a 301 redirect? We don't know. [To verify] — this opacity complicates SEO audits, especially on complex sites with thousands of pages.
Second nuance: the notion of a 'clearer' URL remains subjective. Google has never published an evaluation grid. We assume that criteria like length, absence of special characters, human readability play a role — but nothing quantified.
In which cases doesn't this rule apply?
When Google detects an attempt at manipulation. If you declare URL A as canonical while it's empty or irrelevant, and URL B contains the actual indexable content, Google will choose B — regardless of your tags.
Another exception: sites with syndicated or scraped content. Google can decide that the external source URL is more legitimate than your own URL, even if you declare the canonical on your end. The engine prioritizes the presumed origin of the content.
Practical impact and recommendations
What should you do concretely to control canonicalization?
Ensure that all your signals converge toward the same URL version. If you want example.com/product-a to be canonical, then:
- Declare an explicit rel=canonical pointing to this URL on all variants (with/without trailing slash, with/without www, HTTP/HTTPS)
- Redirect all non-canonical variants with 301 to the canonical URL
- List only the canonical URL in your XML sitemap
- Ensure that your internal links point massively to this version — not to variants
- Monitor backlinks: if third-party sites point to a non-canonical variant, contact them for an update (or set up redirects)
- Prioritize short, descriptive URLs without unnecessary parameters
What mistakes should you absolutely avoid?
Mistake #1: declare a canonical, but continue making internal links to other variants. Google sees the inconsistency and may ignore your tag.
Mistake #2: list multiple versions of the same page in the sitemap. This sends a contradictory signal — Google doesn't know which version to prioritize.
Mistake #3: neglect redirects. If you migrated from HTTP to HTTPS but old URLs don't 301 redirect, Google may continue indexing both versions — or choose the wrong one.
How do you verify that your site is correctly configured?
Use Google Search Console to identify indexed URLs. If you see non-canonical variants appearing in the index, it means your signals aren't converging.
Audit your internal linking structure with a crawler (Screaming Frog, Oncrawl): every link should point to the declared canonical version. No exceptions.
Verify that your XML sitemap contains no duplicate URLs, no redirects, no non-canonical variants. Only the final indexable URLs should appear there.
Managing canonicalization requires perfect consistency across multiple technical layers — tags, redirects, sitemap, internal linking. On complex sites with thousands of pages, migrations, or multilingual architectures, this orchestration can quickly become tricky. Engaging a specialized SEO agency helps secure this consistency and avoid costly visibility mistakes in organic search.
❓ Frequently Asked Questions
Le rel=canonical suffit-il à forcer Google à choisir mon URL préférée ?
Dois-je supprimer toutes les URLs non-canoniques de mon sitemap ?
Que faire si Google indexe la mauvaise version malgré mes balises canonical ?
Les backlinks vers une URL non-canonique nuisent-ils à mon SEO ?
Qu'est-ce qu'une URL « plus claire » selon Google ?
🎥 From the same video 22
Other SEO insights extracted from this same Google Search Central video · published on 28/03/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.