Official statement
What you need to understand
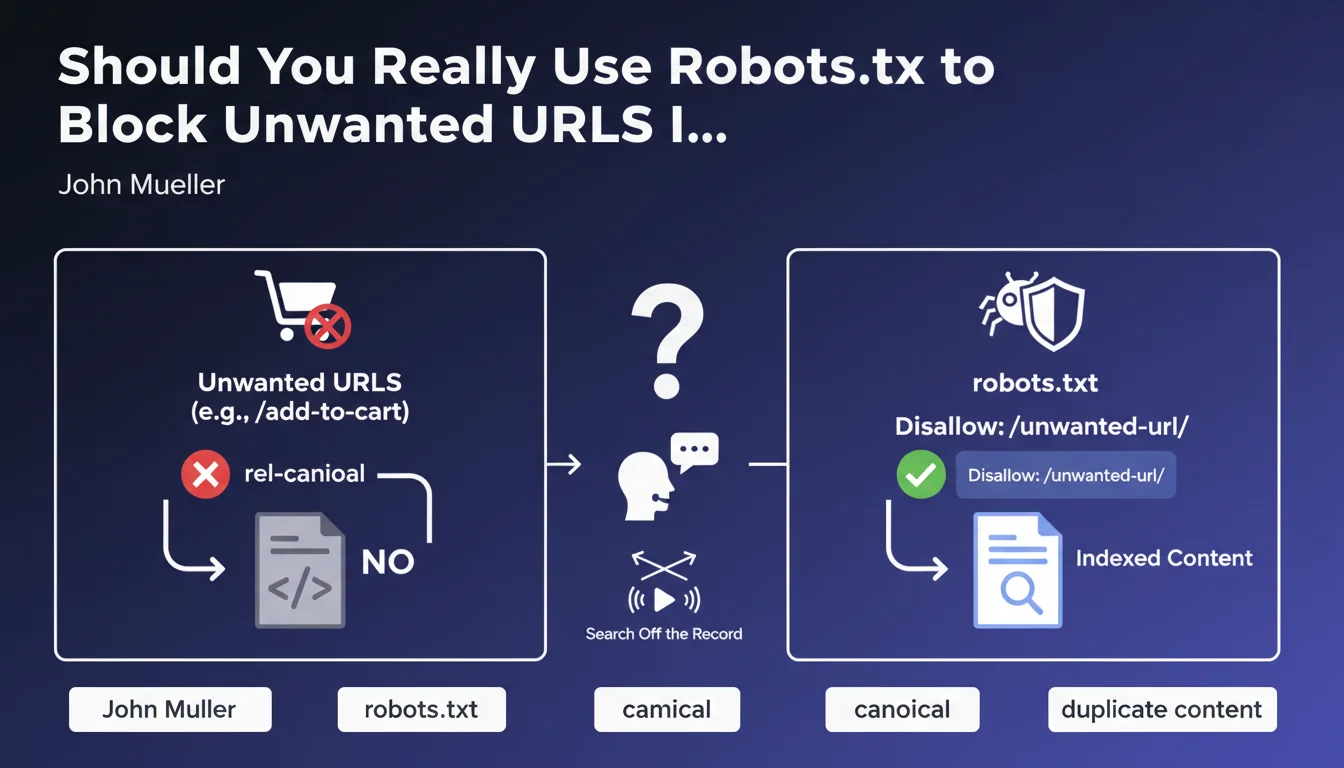
Google explicitly recommends using the robots.txt file to block indexation of unwanted URLs, such as "add to cart" pages or other functional pages with no SEO value.
This approach clearly differs from using the rel-canonical tag, which many SEO practitioners reflexively employ to handle these situations. According to this statement, canonicalization is not the appropriate solution for this type of issue.
Context matters: these are pages that have no reason to be indexed in the first place. Pages like "add to cart", session parameters, and intermediate form steps create no value for users arriving from Google.
- Robots.txt purely and simply prevents crawling of these URLs
- The canonical tag suggests a preferred version but allows Google to crawl all variants
- This recommendation aims to optimize crawl budget by preventing Googlebot from wasting time on these pages
- It follows a logic of proactive indexation management rather than corrective
SEO Expert opinion
This recommendation is perfectly consistent with SEO best practices observed in the field. Robots.txt is indeed the most effective tool to prevent wasting crawl budget on valueless URLs.
However, an important nuance must be added: if these URLs are already massively indexed, blocking via robots.txt alone won't immediately remove them from the index. In this case, a combined approach may be temporarily necessary.
Furthermore, the canonical tag remains relevant for managing legitimate variants of the same content (www/non-www versions, sorting parameters, pagination). This recommendation only applies to pages that fundamentally have no reason to exist in the index.
Practical impact and recommendations
- Audit your site to identify all functional URLs without SEO value (cart, checkout, session parameters, useless filters)
- Check the indexation status of these URLs via Search Console (URL inspection and coverage reports)
- For URLs not yet indexed: add them immediately to robots.txt with appropriate Disallow directives
- For already indexed URLs: first implement a noindex tag, wait for deindexation (2-4 weeks), then switch to robots.txt blocking
- Don't canonicalize to main pages URLs that simply shouldn't exist in the index
- Use patterns in robots.txt to efficiently block groups of similar URLs (e.g., /cart/, /*?add-to-cart=*, /checkout/*)
- Document your strategy: create a spreadsheet listing which URLs are blocked, why, and which method is used
- Test your robots.txt rules in Search Console before deployment to avoid accidentally blocking important pages
- Monitor regularly newly crawled URLs to detect new patterns to block
💬 Comments (0)
Be the first to comment.