Declaration officielle
Ce qu'il faut comprendre
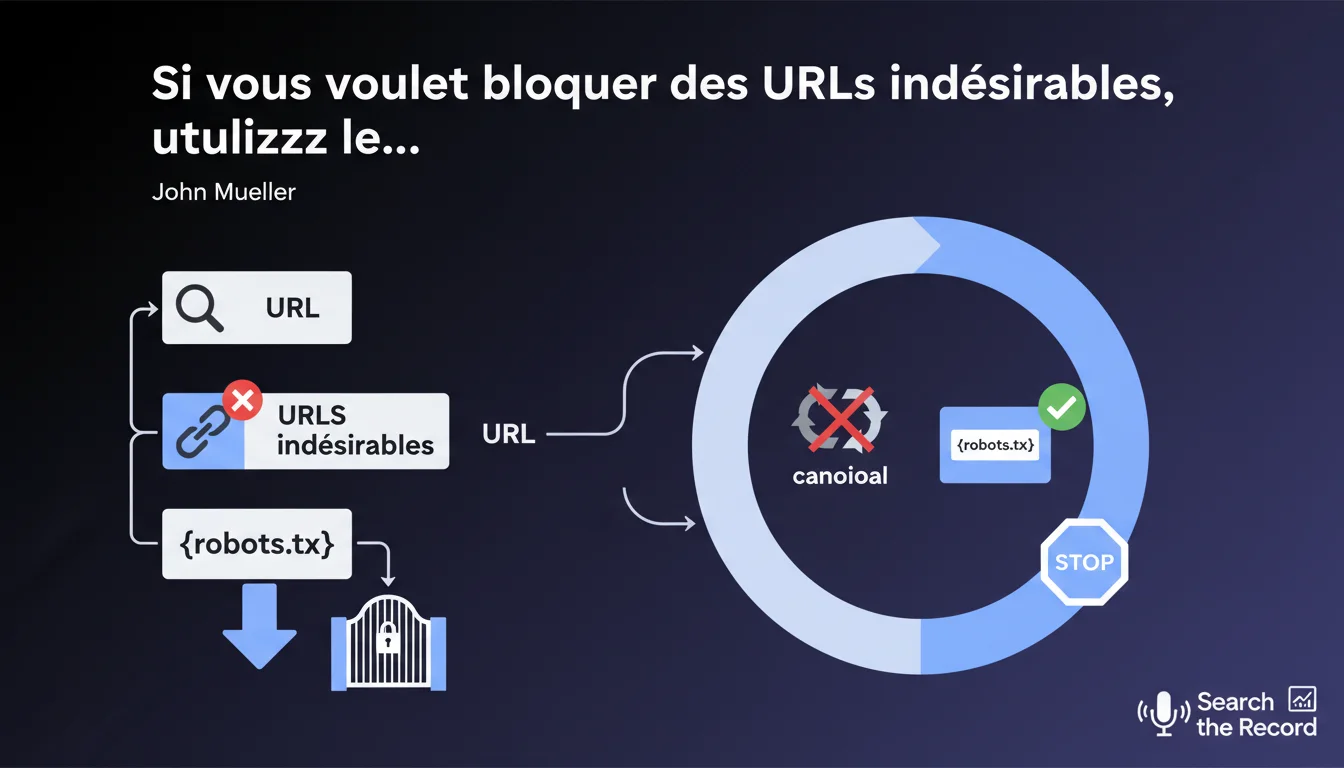
Google recommande explicitement d'utiliser le fichier robots.txt pour bloquer l'indexation des URLs indésirables, comme les pages "ajouter au panier" ou autres pages fonctionnelles sans valeur SEO.
Cette approche se distingue clairement de l'utilisation de la balise rel-canonical, que beaucoup de praticiens SEO emploient par réflexe pour gérer ces situations. Selon cette déclaration, la canonicalisation n'est pas la solution appropriée pour ce type de problématique.
Le contexte est important : il s'agit de pages qui n'ont aucune raison d'être indexées dès le départ. Les pages de type "add to cart", les paramètres de session, les étapes intermédiaires de formulaires ne créent aucune valeur pour l'utilisateur arrivant depuis Google.
- Le robots.txt empêche purement et simplement le crawl de ces URLs
- La balise canonical suggère une version préférée mais laisse Google crawler toutes les variantes
- Cette recommandation vise à optimiser le budget de crawl en évitant que Googlebot perde du temps sur ces pages
- Elle s'inscrit dans une logique de gestion proactive de l'indexation plutôt que corrective
Avis d'un expert SEO
Cette recommandation est parfaitement cohérente avec les meilleures pratiques SEO observées sur le terrain. Le robots.txt est effectivement l'outil le plus efficace pour empêcher le gaspillage de budget de crawl sur des URLs sans valeur.
Il faut toutefois apporter une nuance importante : si ces URLs sont déjà massivement indexées, bloquer via robots.txt seul ne les supprimera pas immédiatement de l'index. Dans ce cas, une approche combinée peut être nécessaire temporairement.
Par ailleurs, la balise canonical reste pertinente pour gérer les variantes légitimes d'un même contenu (versions avec/sans www, paramètres de tri, pagination). La recommandation ne s'applique qu'aux pages qui n'ont fondamentalement aucune raison d'exister dans l'index.
Impact pratique et recommandations
- Auditez votre site pour identifier toutes les URLs fonctionnelles sans valeur SEO (panier, checkout, paramètres de session, filtres inutiles)
- Vérifiez l'état d'indexation de ces URLs via Search Console (inspection d'URL et rapports de couverture)
- Pour les URLs non encore indexées : ajoutez-les immédiatement au robots.txt avec des directives Disallow appropriées
- Pour les URLs déjà indexées : implémentez d'abord une balise noindex, attendez la désindexation (2-4 semaines), puis basculez vers le blocage robots.txt
- Ne canonisez pas vers des pages principales des URLs qui ne devraient simplement pas exister dans l'index
- Utilisez les patterns dans robots.txt pour bloquer efficacement des groupes d'URLs similaires (ex: /cart/, /*?add-to-cart=*, /checkout/*)
- Documentez votre stratégie : créez un tableau listant quelles URLs sont bloquées, pourquoi, et quelle méthode est utilisée
- Testez vos règles robots.txt dans Search Console avant déploiement pour éviter de bloquer accidentellement des pages importantes
- Surveillez régulièrement les nouvelles URLs crawlées pour détecter de nouveaux patterns à bloquer
💬 Commentaires (0)
Soyez le premier à commenter.