Declaration officielle
Autres déclarations de cette vidéo 17 ▾
- 1:24 Pourquoi Google republie-t-il des guides sur robots.txt et meta robots maintenant ?
- 7:02 GoogleBot crawle-t-il des URLs que votre site n'a jamais générées ?
- 7:27 Pourquoi Search Console et Google Analytics affichent-ils des chiffres différents ?
- 7:27 GoogleBot crawle-t-il vraiment des URLs que votre site n'a jamais générées ?
- 8:07 Pourquoi Search Console et Google Analytics affichent-ils des données différentes ?
- 8:51 Combien de temps Google met-il vraiment à reconnaître une correction de balise noindex ?
- 9:49 Pourquoi Google met-il autant de temps à reconnaître la suppression d'une balise noindex ?
- 11:11 L'encodage des caractères spéciaux dans le code source nuit-il vraiment au référencement ?
- 11:11 L'encodage des caractères spéciaux dans le code source pose-t-il un problème pour le SEO ?
- 11:51 Faut-il vraiment bloquer les PDF avec robots.txt ou utiliser noindex ?
- 14:14 Combien de temps Google met-il vraiment à afficher votre nouveau nom de site ?
- 14:14 Comment forcer Google à afficher le bon nom de votre site dans les SERP ?
- 14:59 Pourquoi Google pénalise-t-il les noms de marque trop similaires dans les SERP ?
- 15:14 Faut-il éviter les noms de marque similaires pour ne pas nuire à son référencement naturel ?
- 19:01 Pourquoi Google refuse-t-il de détailler ses critères de classification adulte ?
- 20:13 Un site 100% HTTPS sans version HTTP est-il pénalisé par Google ?
- 20:30 Un site HTTPS-only pose-t-il un problème SEO ?
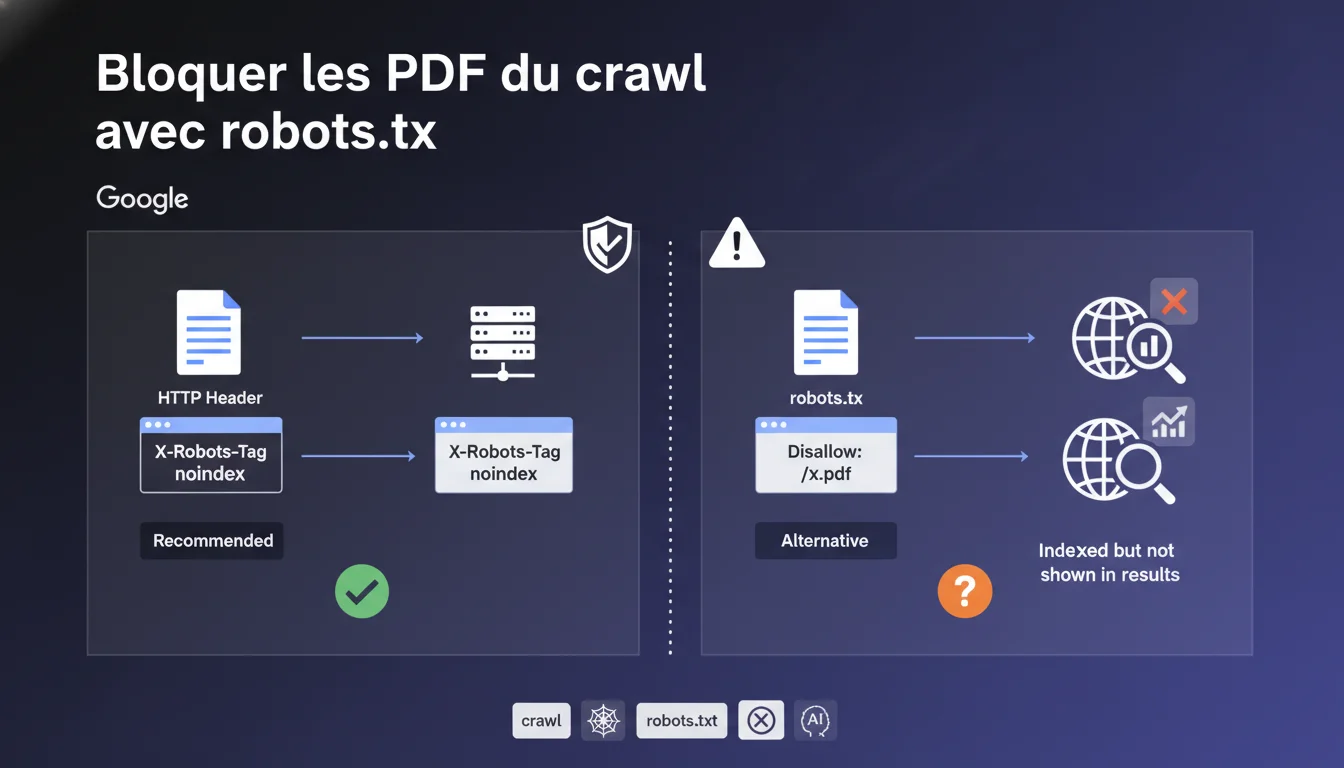
Google privilégie l'en-tête HTTP X-Robots-Tag avec noindex pour bloquer les PDF du crawl. Robots.txt est une solution de secours, mais attention : un PDF bloqué par robots.txt peut être indexé sans être affiché dans les résultats. Paradoxe à maîtriser absolument.
Ce qu'il faut comprendre
Pourquoi Google distingue-t-il crawl et indexation pour les PDF ?
La confusion vient d'un malentendu fondamental : bloquer le crawl ne bloque pas l'indexation. Quand vous utilisez robots.txt pour interdire l'accès à un PDF, Googlebot ne peut pas le télécharger. Logique.
Mais si ce fichier est lié depuis d'autres pages, Google peut créer une entrée fantôme dans son index — sans jamais avoir lu le contenu. Le PDF existe dans la base de données, simplement il ne ressort pas dans les SERP. C'est ce que Google appelle pudiquement « indexé mais non affiché ».
Quelle est la différence concrète entre X-Robots-Tag et robots.txt ?
L'en-tête HTTP X-Robots-Tag: noindex s'applique au moment où Googlebot accède au fichier. Il crawle, lit l'en-tête, comprend l'instruction et n'indexe pas. Propre, net.
Robots.txt intervient avant : il empêche carrément le crawl. Googlebot n'ouvre jamais le PDF. Problème ? Sans accès au fichier, il ne peut pas lire d'éventuelle directive noindex embarquée. Si des backlinks pointent vers ce PDF, Google peut quand même le référencer par défaut — avec titre générique et URL visible.
Pourquoi robots.txt reste une option si X-Robots-Tag est supérieur ?
Parce que tout le monde n'a pas la main sur la configuration serveur. Modifier les en-têtes HTTP d'un type MIME spécifique demande un accès .htaccess, nginx.conf ou équivalent — luxe pas toujours disponible sur des CMS mutualisés.
Robots.txt est un pis-aller universel, éditable via FTP basique. Google le tolère, mais prévient des limites. En clair : si vous avez le choix technique, prenez X-Robots-Tag. Sinon, assumez le risque d'indexation fantôme.
- X-Robots-Tag noindex : méthode recommandée, contrôle total sur l'indexation
- Robots.txt : solution de repli, risque d'indexation sans affichage dans les résultats
- Un PDF bloqué par robots.txt peut apparaître dans l'index Google avec URL visible mais sans snippet
- L'indexation fantôme survient surtout si le PDF reçoit des liens externes
Avis d'un expert SEO
Cette directive résout-elle vraiment tous les cas de figure ?
Non. Et Google ne détaille pas les zones grises. Prenons un PDF hébergé sur un CDN tiers — vous n'avez ni accès aux en-têtes HTTP ni fichier robots.txt dédié. Que faire ? La déclaration reste muette.
Autre angle mort : les PDF générés dynamiquement via paramètres d'URL. Bloquer par pattern dans robots.txt devient vite ingérable. X-Robots-Tag dynamique dans le script de génération serait idéal, mais ça suppose une stack technique maîtrisée. Beaucoup de sites se retrouvent coincés entre théorie propre et contraintes réelles.
L'indexation sans affichage est-elle réellement neutre en SEO ?
[A vérifier] Google affirme qu'un PDF indexé mais non affiché ne pollue pas les SERP. Techniquement vrai. Mais qu'en est-il du crawl budget consommé sur ces URLs fantômes ? Aucune donnée officielle.
Sur de gros sites avec milliers de PDFs, cette indexation parasite pourrait théoriquement diluer l'attention du bot. Rien de prouvé, mais le silence de Google sur ce point précis n'inspire pas confiance. En terrain incertain, mieux vaut éviter toute indexation non intentionnelle.
Robots.txt bloque-t-il vraiment l'indexation dans tous les cas ?
Soyons honnêtes : non. Si un PDF circule massivement via backlinks avant d'être bloqué, Google peut avoir déjà crawlé et indexé. Bloquer après coup via robots.txt empêche le re-crawl, mais ne force pas la désindexation de l'entrée existante.
Pour purger l'index, il faut soit lever temporairement le blocage robots.txt et ajouter X-Robots-Tag noindex (contradiction technique délicate), soit passer par Search Console avec demande de suppression manuelle. Processus lourd, souvent mal documenté par Google lui-même.
Impact pratique et recommandations
Quelle méthode privilégier selon votre configuration serveur ?
Si vous contrôlez Apache ou Nginx : ajoutez X-Robots-Tag: noindex dans la configuration pour tous les .pdf. Exemple Apache dans .htaccess :
<FilesMatch "\.pdf$">
Header set X-Robots-Tag "noindex"
</FilesMatch>
Sur serveurs mutualisés ou CMS bridés (WordPress.com gratuit, Wix, etc.), passez par robots.txt. Mais auditez régulièrement avec site:votredomaine.fr filetype:pdf dans Google pour détecter toute indexation fantôme malgré le blocage.
Comment gérer les PDF déjà indexés qu'on veut retirer ?
Trois étapes — et c'est là que ça coince souvent :
1. Si bloqué par robots.txt, lever temporairement le blocage
2. Ajouter X-Robots-Tag noindex sur ces fichiers
3. Attendre le re-crawl (forcer via Search Console si urgent), puis remettre robots.txt si souhaité
Procédure contre-intuitive : il faut autoriser le crawl pour injecter la directive de non-indexation. Google ne le précise jamais clairement dans ses guides, ce qui génère erreurs à répétition.
Quels pièges éviter absolument ?
Ne bloquez pas par robots.txt et X-Robots-Tag simultanément sur un PDF déjà indexé. Googlebot ne pourra jamais lire l'en-tête noindex puisque robots.txt l'empêche d'accéder au fichier — cercle vicieux.
Autre erreur classique : croire que Disallow: /*.pdf dans robots.txt suffit à désindexer. Non. Ça empêche nouveaux crawls, mais l'index historique persiste. Toujours vérifier l'état réel via Search Console, section Couverture.
- Auditer l'accès serveur : avez-vous les droits pour modifier les en-têtes HTTP ?
- Si oui : implémenter X-Robots-Tag noindex pour tous les PDF sensibles
- Si non : utiliser robots.txt en assumant le risque d'indexation sans affichage
- Vérifier mensuellement avec site:domaine.fr filetype:pdf les indexations non souhaitées
- Pour désindexer un PDF bloqué par robots.txt : lever le blocage, ajouter noindex, attendre re-crawl
- Ne jamais cumuler robots.txt et X-Robots-Tag sur un même fichier déjà présent dans l'index
- Documenter la stratégie choisie dans un process interne pour éviter incohérences futures
❓ Questions frequentes
Peut-on utiliser meta robots noindex directement dans un PDF ?
Un PDF bloqué par robots.txt apparaît-il dans Google Images ?
Faut-il bloquer les PDF internes type documentation technique ?
Combien de temps faut-il pour qu'un PDF bloqué disparaisse de l'index ?
Un PDF avec X-Robots-Tag noindex consomme-t-il du crawl budget ?
🎥 De la même vidéo 17
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 27/03/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.