Declaration officielle
Autres déclarations de cette vidéo 17 ▾
- 1:24 Pourquoi Google republie-t-il des guides sur robots.txt et meta robots maintenant ?
- 7:02 GoogleBot crawle-t-il des URLs que votre site n'a jamais générées ?
- 7:27 Pourquoi Search Console et Google Analytics affichent-ils des chiffres différents ?
- 7:27 GoogleBot crawle-t-il vraiment des URLs que votre site n'a jamais générées ?
- 8:07 Pourquoi Search Console et Google Analytics affichent-ils des données différentes ?
- 9:49 Pourquoi Google met-il autant de temps à reconnaître la suppression d'une balise noindex ?
- 11:11 L'encodage des caractères spéciaux dans le code source nuit-il vraiment au référencement ?
- 11:11 L'encodage des caractères spéciaux dans le code source pose-t-il un problème pour le SEO ?
- 11:47 Comment bloquer efficacement les PDF du crawl Google sans risquer l'indexation ?
- 11:51 Faut-il vraiment bloquer les PDF avec robots.txt ou utiliser noindex ?
- 14:14 Combien de temps Google met-il vraiment à afficher votre nouveau nom de site ?
- 14:14 Comment forcer Google à afficher le bon nom de votre site dans les SERP ?
- 14:59 Pourquoi Google pénalise-t-il les noms de marque trop similaires dans les SERP ?
- 15:14 Faut-il éviter les noms de marque similaires pour ne pas nuire à son référencement naturel ?
- 19:01 Pourquoi Google refuse-t-il de détailler ses critères de classification adulte ?
- 20:13 Un site 100% HTTPS sans version HTTP est-il pénalisé par Google ?
- 20:30 Un site HTTPS-only pose-t-il un problème SEO ?
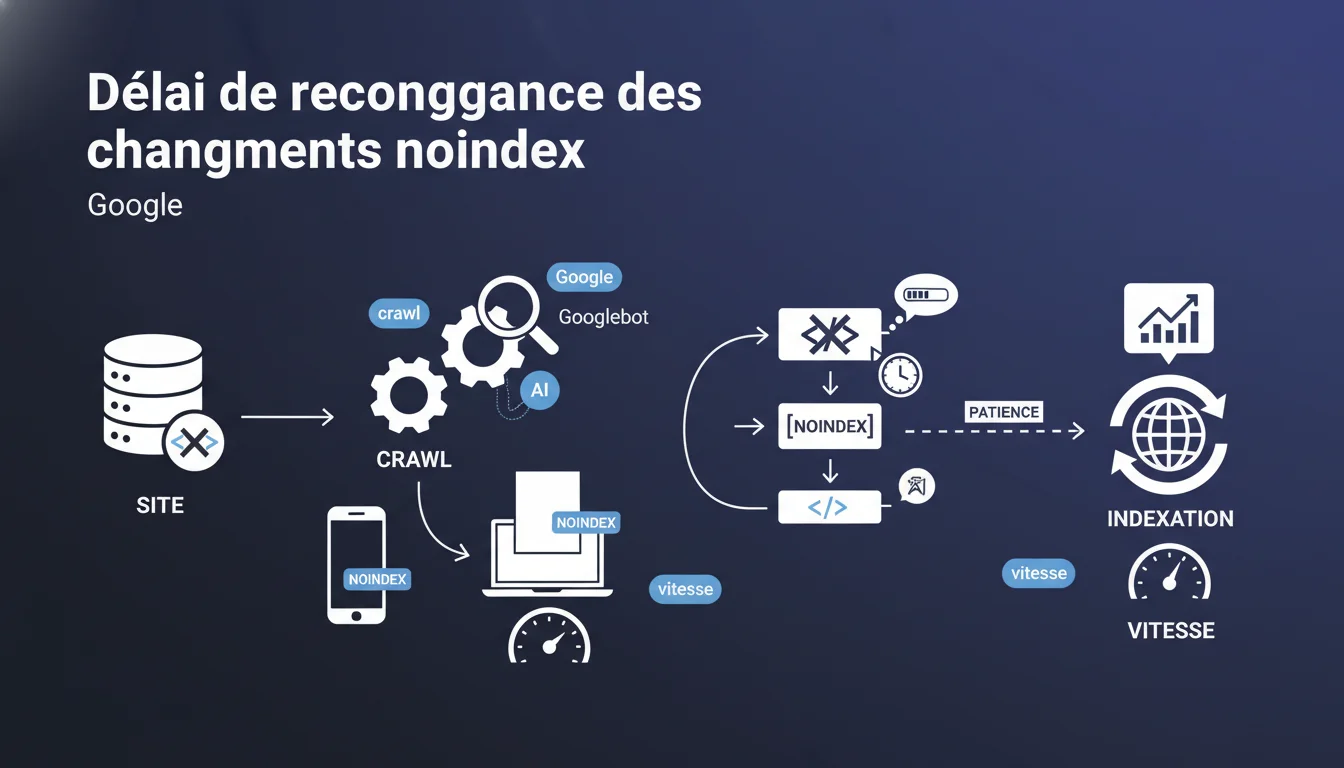
Google confirme que la reconnaissance d'une correction d'erreur noindex peut prendre un temps variable selon les sections du site et la vitesse de crawl allouée. Pas de délai garanti — il faut patienter et surveiller. Ce flou témoigne d'une logique de priorisation opaque côté Googlebot.
Ce qu'il faut comprendre
Google rappelle ici une réalité frustrante : corriger une balise noindex appliquée par erreur ne déclenche pas automatiquement une réindexation immédiate. Le moteur doit d'abord recrawler la page, constater l'absence de la directive, puis la traiter à nouveau.
Ce délai varie considérablement d'un site à l'autre, voire d'une section à l'autre du même site. Aucun SLA communiqué, aucune promesse de traitement en 48h ou 7 jours. Juste : "soyez patient".
Pourquoi Google ne donne-t-il pas de délai précis ?
Parce que la vitesse de crawl dépend de centaines de signaux : popularité du site, fréquence de mise à jour, santé technique, budget crawl alloué, niveau de priorité de la section concernée. Une page enterrée à 5 clics de la home mettra plus de temps qu'une catégorie phare.
Google ne veut pas s'engager sur un chiffre qu'il ne pourrait tenir pour tous. Résultat : une déclaration prudente, presque tautologique — "ça prend du temps, attendez".
Qu'est-ce qui influence concrètement ce délai de reconnaissance ?
Plusieurs facteurs entrent en jeu. La fréquence de crawl de la section concernée est décisive : si Googlebot ne passe qu'une fois par mois, vous attendrez un mois. La profondeur de la page dans l'arborescence joue aussi : plus elle est loin, plus elle est recrawlée tardivement.
Enfin, le contexte global du site compte : un site lent, bourré d'erreurs ou avec un crawl budget épuisé sur des redirections en chaîne verra ses corrections traitées mollement. Google ne priorise pas ce qui n'est pas stratégique.
- Le crawl n'est pas instantané — même après correction, il faut attendre le passage de Googlebot
- Les sections peu visitées ou profondes sont recrawlées moins souvent
- Le budget crawl global du site conditionne la vitesse de traitement des changements
- Aucun délai garanti — Google refuse de s'engager sur un chiffre précis
- La patience est obligatoire — forcer le crawl via Search Console aide, mais ne garantit rien
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées ?
Oui, malheureusement. Sur le terrain, on observe régulièrement des délais de plusieurs semaines entre la correction d'une erreur noindex et la réapparition effective de la page dans l'index. Parfois plus rapide sur des sites premium, parfois interminable sur des sites mal entretenus.
Ce qui agace, c'est le manque total de visibilité : Search Console affiche "Page exclue par la balise noindex" tant que Google n'a pas recrawlé, et entre-temps, aucun moyen de savoir si Googlebot a même prévu de repasser. [A vérifier] : Google prétend que demander une inspection d'URL accélère le processus, mais dans la pratique, l'effet est aléatoire.
Quelles nuances faut-il apporter à cette affirmation ?
Soyons honnêtes : tous les sites ne sont pas égaux devant le crawl. Un média d'actualité avec un taux de crawl élevé verra ses corrections traitées en quelques jours. Un site vitrine B2B mis à jour une fois par trimestre attendra des semaines.
Par ailleurs, Google ne dit rien sur les cas d'urgence. Si vous avez accidentellement noindexé 10 000 pages produits en production, la patience n'est pas une option. Dans ce genre de scénario, multiplier les demandes d'inspection URL et relancer des crawls via sitemap XML peut accélérer — mais sans garantie.
Enfin, attention : cette déclaration ne couvre que le délai de reconnaissance, pas le délai de réindexation complète. Une fois la directive supprimée constatée, Google doit encore décider si la page mérite d'être indexée. Ce sont deux étapes distinctes.
Dans quels cas cette règle ne s'applique-t-elle pas vraiment ?
Si vous contrôlez le budget crawl de manière chirurgicale — via robots.txt, paramètres Search Console, optimisation technique poussée — vous pouvez forcer une réaction plus rapide. Mais cela suppose une maîtrise avancée et des leviers que 90% des sites n'actionnent jamais.
De même, les sites qui déploient du server-side rendering ou des architectures JavaScript mal gérées peuvent voir des délais encore plus longs, car Googlebot doit d'abord render la page pour constater l'absence de noindex. Ce cas n'est pas mentionné par Google, mais il complique tout.
Impact pratique et recommandations
Que faut-il faire concrètement après avoir corrigé une erreur noindex ?
D'abord, vérifiez que la correction est bien déployée en crawlant vous-même la page avec Screaming Frog ou Oncrawl. Contrôlez à la fois le code source HTML et les en-têtes HTTP — un X-Robots-Tag: noindex persiste parfois même si le meta est supprimé.
Ensuite, demandez une inspection d'URL dans Search Console pour signaler à Google que la page a changé. Faites-le sur les URLs prioritaires, pas sur 10 000 pages d'un coup — ça n'accélérera rien et risque d'être ignoré.
Enfin, surveillez l'évolution dans Search Console via le rapport "Pages" et les logs serveur si vous y avez accès. Vous verrez quand Googlebot repasse, et si la page bascule de "Exclue" à "Indexée".
Quelles erreurs éviter pendant cette période d'attente ?
Ne multipliez pas les modifications entre-temps. Si vous changez 15 paramètres en parallèle — contenu, maillage, meta description — vous ne saurez plus ce qui a (ou n'a pas) fonctionné. Isoler la variable est essentiel pour analyser proprement.
Évitez aussi de bombarder Google de demandes d'inspection répétées toutes les 48h. Ça ne sert à rien et Google ne crawle pas à la demande comme un service premium. Une fois par semaine sur les URLs critiques suffit amplement.
Et surtout, ne concluez pas trop vite qu'une page est "perdue" si elle n'est pas réindexée en 10 jours. Ce délai est court pour Google — attendez au moins 3-4 semaines avant de paniquer.
Comment optimiser la vitesse de reconnaissance des corrections ?
Travaillez votre budget crawl global : supprimez les pages inutiles, bloquez les URL parasites en robots.txt, corrigez les redirections en chaîne, accélérez le temps de réponse serveur. Plus Googlebot crawle efficacement, plus vite il détectera vos corrections.
Renforcez le maillage interne vers les pages corrigées depuis des sections fréquemment crawlées (home, catégories phares). Cela augmente les chances qu'elles soient découvertes rapidement lors du prochain passage.
Poussez un sitemap XML mis à jour incluant uniquement les URLs corrigées avec une balise récente. Google ne garantit rien, mais dans certains cas, ça accélère la redécouverte.
- Crawlez vous-même le site pour confirmer la suppression de la balise noindex (HTML + headers HTTP)
- Demandez une inspection d'URL dans Search Console sur les pages prioritaires
- Surveillez les logs serveur pour détecter le retour de Googlebot
- Ne modifiez rien d'autre en parallèle — isolez la variable pour mesurer l'effet
- Optimisez le budget crawl global : vitesse serveur, redirections, arborescence propre
- Renforcez le maillage interne vers les pages corrigées
- Soumettez un sitemap XML à jour avec lastmod récent
- Attendez 3-4 semaines avant de conclure à un échec — la patience est obligatoire
❓ Questions frequentes
Combien de temps faut-il attendre après avoir corrigé une balise noindex ?
Demander une inspection d'URL dans Search Console accélère-t-il vraiment la réindexation ?
Pourquoi certaines pages sont-elles réindexées rapidement et d'autres mettent des semaines ?
Que faire si la page n'est toujours pas indexée après un mois ?
Peut-on forcer Google à crawler une page immédiatement après correction ?
🎥 De la même vidéo 17
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 27/03/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.