Declaration officielle
Autres déclarations de cette vidéo 17 ▾
- 1:24 Pourquoi Google republie-t-il des guides sur robots.txt et meta robots maintenant ?
- 7:27 Pourquoi Search Console et Google Analytics affichent-ils des chiffres différents ?
- 7:27 GoogleBot crawle-t-il vraiment des URLs que votre site n'a jamais générées ?
- 8:07 Pourquoi Search Console et Google Analytics affichent-ils des données différentes ?
- 8:51 Combien de temps Google met-il vraiment à reconnaître une correction de balise noindex ?
- 9:49 Pourquoi Google met-il autant de temps à reconnaître la suppression d'une balise noindex ?
- 11:11 L'encodage des caractères spéciaux dans le code source nuit-il vraiment au référencement ?
- 11:11 L'encodage des caractères spéciaux dans le code source pose-t-il un problème pour le SEO ?
- 11:47 Comment bloquer efficacement les PDF du crawl Google sans risquer l'indexation ?
- 11:51 Faut-il vraiment bloquer les PDF avec robots.txt ou utiliser noindex ?
- 14:14 Combien de temps Google met-il vraiment à afficher votre nouveau nom de site ?
- 14:14 Comment forcer Google à afficher le bon nom de votre site dans les SERP ?
- 14:59 Pourquoi Google pénalise-t-il les noms de marque trop similaires dans les SERP ?
- 15:14 Faut-il éviter les noms de marque similaires pour ne pas nuire à son référencement naturel ?
- 19:01 Pourquoi Google refuse-t-il de détailler ses critères de classification adulte ?
- 20:13 Un site 100% HTTPS sans version HTTP est-il pénalisé par Google ?
- 20:30 Un site HTTPS-only pose-t-il un problème SEO ?
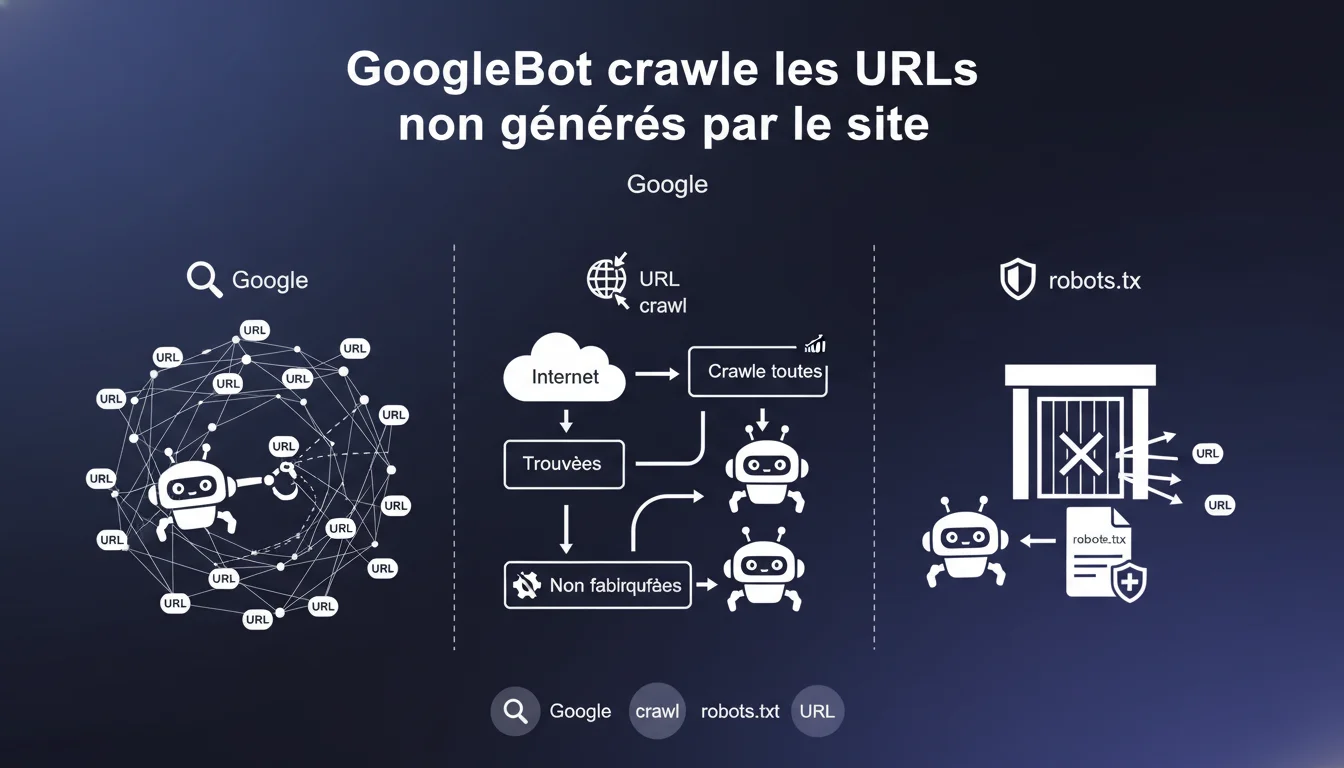
Google crawle toutes les URLs qu'il trouve sur le web, même si votre site ne les a pas créées. Le moteur ne fabrique jamais d'URLs lui-même, mais suit les liens découverts partout sur Internet. Si certaines URLs posent problème, c'est au robots.txt de les bloquer.
Ce qu'il faut comprendre
Qu'est-ce que cela signifie concrètement pour votre site ?
GoogleBot découvre des URLs via des sources externes : liens sur d'autres sites, redirections, paramètres ajoutés par des outils tiers, partages sur réseaux sociaux. Ces URLs peuvent pointer vers votre domaine sans que vous les ayez jamais générées vous-même.
Le robot ne crée pas d'URLs de toutes pièces. Il suit ce qu'il trouve. Mais cette découverte peut amener GoogleBot à crawler des variantes d'URLs, des pages de test, des espaces admin mal sécurisés, ou des paramètres tracking improbables.
Pourquoi Google insiste-t-il sur ce point ?
Parce que certains webmasters s'étonnent de voir des URLs bizarres dans leurs logs. Ils pensent que Google « invente » des chemins. C'est faux.
Si une URL apparaît dans Search Console ou vos logs, c'est qu'elle existe quelque part sur Internet. Un lien cassé, un ancien backlink, un scraper — peu importe. Google l'a trouvée, pas fabriquée.
Quelle est la différence avec les URLs canoniques ou les redirections ?
Google peut crawler une URL non générée par votre site, mais ça ne signifie pas qu'il va l'indexer. Les canonicals, redirections 301, et balises meta robots entrent en jeu après le crawl.
Le crawl est une chose, l'indexation en est une autre. Cette déclaration parle uniquement du comportement de découverte et de crawl.
- GoogleBot suit tous les liens qu'il découvre, même s'ils pointent vers des URLs que vous n'avez jamais créées.
- Le moteur ne génère jamais d'URLs de son propre chef.
- Le robots.txt est l'outil pour empêcher le crawl de ces URLs indésirables.
- La présence d'une URL dans vos logs ne signifie pas qu'elle sera indexée.
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, totalement. On voit régulièrement des URLs avec des paramètres tracking (utm_, fbclid, gclid) ou des facettes mal contrôlées apparaître dans Search Console. Ces URLs n'ont jamais été générées par le CMS, mais par des outils tiers ou des utilisateurs.
Google suit ces liens parce qu'ils existent sur le web. C'est cohérent avec le fonctionnement d'un crawler qui explore l'ensemble du graphe de liens disponible.
Quelles nuances faut-il apporter à cette affirmation ?
Google ne fabrique pas d'URLs, d'accord. Mais il peut normaliser certaines formes (majuscules/minuscules, trailing slash) ou suivre des redirections en chaîne. Le résultat final dans les logs peut sembler différent de l'URL source.
De plus, certains outils de JavaScript rendering peuvent générer des liens côté client qui n'apparaissent pas dans le HTML brut. GoogleBot les crawle quand même, ce qui peut donner l'impression qu'il « invente » des chemins. [A vérifier] : la distinction entre URL découverte via JS et URL « fabriquée » reste floue dans la doc officielle.
Dans quels cas cette règle pose-t-elle problème ?
Quand votre site génère des URLs dynamiques infinies — calendriers, filtres combinatoires, sessions utilisateurs. Si ces URLs sont linkées quelque part, GoogleBot les crawlera. Le crawl budget s'épuise sur des pages sans valeur.
Impact pratique et recommandations
Que faut-il faire concrètement pour contrôler ce crawl ?
Identifiez les sources de liens externes qui pointent vers des URLs que vous ne voulez pas voir crawler. Utilisez Search Console, vos logs serveur, et des outils comme Screaming Frog pour repérer ces URLs.
Ensuite, décidez : bloquer en robots.txt, rediriger en 301, ou canonicaliser vers la bonne version. Le choix dépend de l'objectif — économiser du crawl budget ou éviter du contenu dupliqué.
Quelles erreurs éviter absolument ?
Ne bloquez pas en robots.txt des URLs que vous voulez indexer. Le robots.txt empêche le crawl, donc Google ne peut pas lire les balises canonical ou noindex sur ces pages.
Autre piège : laisser des paramètres de session ou de tracking générer des URLs infinies sans les gérer via le URL Parameters Tool de Search Console (même si Google l'a déprécié, la logique reste valable côté serveur).
Comment vérifier que mon site est conforme ?
Auditez vos logs serveur régulièrement. Repérez les URLs crawlées par GoogleBot qui ne font pas partie de votre sitemap XML ou de votre arborescence normale.
Vérifiez que votre robots.txt bloque bien les espaces sensibles (admin, test, staging). Testez avec l'outil de test robots.txt de Search Console.
- Auditez vos logs serveur pour identifier les URLs non générées par votre CMS.
- Bloquez en robots.txt les répertoires sensibles (admin, staging, dev).
- Utilisez des canonicals pour consolider les variantes d'URLs.
- Redirigez en 301 les URLs obsolètes ou mal formées qui reçoivent encore des backlinks.
- Surveillez Search Console pour repérer les erreurs de crawl sur des URLs inattendues.
- Nettoyez les paramètres de tracking côté serveur si possible (réécritures d'URL).
❓ Questions frequentes
Google peut-il crawler une URL que mon site n'a jamais générée ?
Comment empêcher GoogleBot de crawler ces URLs indésirables ?
Pourquoi je vois des URLs bizarres avec des paramètres tracking dans Search Console ?
GoogleBot peut-il indexer une URL bloquée en robots.txt ?
Comment savoir quelles URLs GoogleBot crawle sur mon site ?
🎥 De la même vidéo 17
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 27/03/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.