Declaration officielle
Autres déclarations de cette vidéo 17 ▾
- 1:24 Pourquoi Google republie-t-il des guides sur robots.txt et meta robots maintenant ?
- 7:02 GoogleBot crawle-t-il des URLs que votre site n'a jamais générées ?
- 7:27 Pourquoi Search Console et Google Analytics affichent-ils des chiffres différents ?
- 7:27 GoogleBot crawle-t-il vraiment des URLs que votre site n'a jamais générées ?
- 8:07 Pourquoi Search Console et Google Analytics affichent-ils des données différentes ?
- 8:51 Combien de temps Google met-il vraiment à reconnaître une correction de balise noindex ?
- 9:49 Pourquoi Google met-il autant de temps à reconnaître la suppression d'une balise noindex ?
- 11:11 L'encodage des caractères spéciaux dans le code source nuit-il vraiment au référencement ?
- 11:11 L'encodage des caractères spéciaux dans le code source pose-t-il un problème pour le SEO ?
- 11:47 Comment bloquer efficacement les PDF du crawl Google sans risquer l'indexation ?
- 11:51 Faut-il vraiment bloquer les PDF avec robots.txt ou utiliser noindex ?
- 14:14 Combien de temps Google met-il vraiment à afficher votre nouveau nom de site ?
- 14:14 Comment forcer Google à afficher le bon nom de votre site dans les SERP ?
- 14:59 Pourquoi Google pénalise-t-il les noms de marque trop similaires dans les SERP ?
- 15:14 Faut-il éviter les noms de marque similaires pour ne pas nuire à son référencement naturel ?
- 19:01 Pourquoi Google refuse-t-il de détailler ses critères de classification adulte ?
- 20:13 Un site 100% HTTPS sans version HTTP est-il pénalisé par Google ?
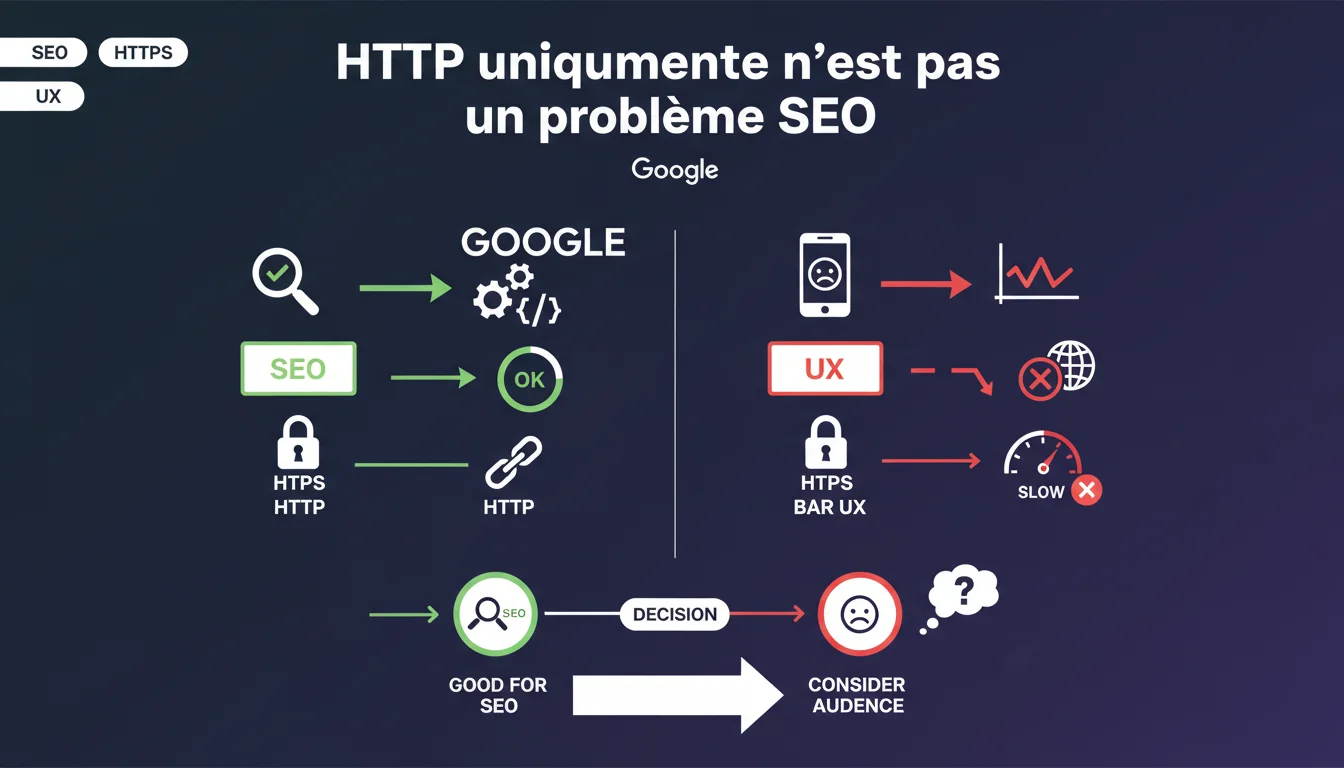
Google affirme qu'un site accessible uniquement en HTTPS (qui retourne une erreur en HTTP) ne pénalise pas le référencement. En revanche, cette configuration peut dégrader l'expérience utilisateur selon votre audience. La décision doit être prise en fonction du contexte technique et du profil des visiteurs.
Ce qu'il faut comprendre
Que signifie concrètement "HTTP uniquement n'est pas un problème SEO" ?
Google précise ici qu'un site configuré pour rejeter les requêtes HTTP (redirection ou erreur) au profit exclusif du HTTPS ne subit aucune pénalité algorithmique. Le moteur de recherche est capable de crawler et indexer ces pages normalement.
Cette déclaration s'inscrit dans la continuité du passage progressif au HTTPS comme standard de facto. Depuis 2014, Google pousse activement les sites vers le chiffrement, notamment via le signal de ranking positif accordé aux sites HTTPS.
Pourquoi Google mentionne-t-il un problème UX potentiel ?
Le hic se situe du côté utilisateur. Certains navigateurs anciens, systèmes obsolètes ou configurations réseau spécifiques peuvent avoir des difficultés à établir une connexion HTTPS.
Pour un site B2B ciblant des entreprises avec infrastructures vieillissantes, bloquer totalement le HTTP peut créer des points de friction. À l'inverse, pour un site e-commerce grand public moderne, cette contrainte est quasi-inexistante.
Quelle est la différence avec la redirection HTTP vers HTTPS classique ?
La plupart des sites configurent une redirection 301 permanente de HTTP vers HTTPS. Cette approche permet aux navigateurs et robots qui tentent une connexion HTTP d'être automatiquement redirigés vers la version sécurisée.
La configuration "HTTPS uniquement" dont parle Google va plus loin : elle refuse purement et simplement la connexion HTTP (erreur de connexion ou timeout). C'est plus strict, mais potentiellement plus bloquant pour certains cas d'usage.
- Aucun impact négatif SEO confirmé pour les sites rejetant le HTTP
- Le crawl et l'indexation fonctionnent normalement en HTTPS exclusif
- La décision doit être guidée par l'analyse de votre audience réelle
- Les navigateurs modernes privilégient déjà HTTPS par défaut
- Vérifier vos logs serveur pour identifier les tentatives HTTP résiduelles
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, c'est cohérent. Les sites configurés en HSTS strict (HTTP Strict Transport Security) avec preload — qui forcent le navigateur à n'utiliser que HTTPS — ne subissent aucune pénalité observable dans les SERPs.
J'ai audité des dizaines de sites en HTTPS-only : leurs performances organiques dépendent des facteurs classiques (contenu, backlinks, technique), pas de ce choix de configuration. Google crawle via HTTPS depuis des années maintenant.
Quelles nuances méritent d'être apportées ?
Google reste volontairement vague sur la notion d'"audience cible". Aucune donnée chiffrée sur le pourcentage d'utilisateurs potentiellement impactés, ni de recommandations précises pour évaluer ce risque. [À vérifier] dans vos propres analytics.
La réalité : en 2025, moins de 1% du trafic web provient de navigateurs incapables de gérer HTTPS correctement. Sauf si vous ciblez des environnements ultra-spécifiques (administrations publiques avec postes figés depuis 15 ans, certains pays émergents avec infrastructures défaillantes).
Dans quels cas cette configuration pose-t-elle vraiment problème ?
Concrètement ? Si votre trafic inclut une part significative d'utilisateurs sur Windows XP, Internet Explorer 6-8, ou certains proxies d'entreprise mal configurés qui cassent le SSL. Vérifiez vos User-Agents dans Analytics.
Pour 95% des sites, c'est un non-sujet. Mais pour une plateforme B2B vendant à des PME industrielles peu digitalisées, ou un site gouvernemental devant rester accessible aux configurations les plus archaïques, la redirection HTTP → HTTPS reste plus prudente que le blocage pur.
Impact pratique et recommandations
Que faut-il faire concrètement avec cette information ?
Analysez d'abord vos logs serveur pour quantifier les requêtes HTTP résiduelles. Si ce volume est négligeable (< 0,5% du trafic) et provient majoritairement de bots, vous pouvez envisager le HTTPS-only sans risque.
Sinon, maintenez une redirection 301 HTTP vers HTTPS classique. Elle offre le même niveau de sécurité tout en préservant l'accessibilité maximale. C'est le meilleur des deux mondes pour la majorité des cas.
Comment vérifier que votre configuration actuelle est optimale ?
Testez votre site en HTTP depuis un navigateur classique. Trois comportements possibles :
- Redirection 301 vers HTTPS : configuration standard recommandée pour la plupart des sites
- Erreur de connexion/timeout : HTTPS-only strict, vérifier l'impact UX dans vos analytics
- Page accessible en HTTP : problème de configuration, à corriger rapidement
- Vérifier la présence du header Strict-Transport-Security dans vos réponses HTTPS
- Contrôler que vos sitemaps XML ne contiennent que des URLs HTTPS
- Auditer les backlinks pointant vers des URLs HTTP (Search Console, Ahrefs, Majestic)
- Tester la compatibilité HTTPS depuis différents navigateurs et appareils représentatifs de votre audience
Quelles erreurs éviter lors de la mise en place ?
Ne confondez pas HSTS (qui force HTTPS côté navigateur après première visite) et le blocage pur des requêtes HTTP. HSTS nécessite toujours une redirection initiale pour fonctionner correctement.
Évitez également de déployer un HTTPS-only strict sans avoir préalablement nettoyé vos backlinks. Un lien HTTP qui génère une erreur au lieu d'une redirection perd son autorité et pénalise votre netlinking.
❓ Questions frequentes
Un site HTTPS-only est-il pénalisé par Google ?
Dois-je absolument rediriger HTTP vers HTTPS ou puis-je bloquer HTTP ?
Comment savoir si mon audience est impactée par un HTTPS-only ?
Le HSTS est-il équivalent à bloquer les requêtes HTTP ?
Mes backlinks HTTP perdent-ils leur valeur si je bloque le HTTP ?
🎥 De la même vidéo 17
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 27/03/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.