Declaration officielle
Autres déclarations de cette vidéo 17 ▾
- 1:24 Pourquoi Google republie-t-il des guides sur robots.txt et meta robots maintenant ?
- 7:02 GoogleBot crawle-t-il des URLs que votre site n'a jamais générées ?
- 7:27 Pourquoi Search Console et Google Analytics affichent-ils des chiffres différents ?
- 7:27 GoogleBot crawle-t-il vraiment des URLs que votre site n'a jamais générées ?
- 8:07 Pourquoi Search Console et Google Analytics affichent-ils des données différentes ?
- 8:51 Combien de temps Google met-il vraiment à reconnaître une correction de balise noindex ?
- 9:49 Pourquoi Google met-il autant de temps à reconnaître la suppression d'une balise noindex ?
- 11:11 L'encodage des caractères spéciaux dans le code source nuit-il vraiment au référencement ?
- 11:11 L'encodage des caractères spéciaux dans le code source pose-t-il un problème pour le SEO ?
- 11:47 Comment bloquer efficacement les PDF du crawl Google sans risquer l'indexation ?
- 14:14 Combien de temps Google met-il vraiment à afficher votre nouveau nom de site ?
- 14:14 Comment forcer Google à afficher le bon nom de votre site dans les SERP ?
- 14:59 Pourquoi Google pénalise-t-il les noms de marque trop similaires dans les SERP ?
- 15:14 Faut-il éviter les noms de marque similaires pour ne pas nuire à son référencement naturel ?
- 19:01 Pourquoi Google refuse-t-il de détailler ses critères de classification adulte ?
- 20:13 Un site 100% HTTPS sans version HTTP est-il pénalisé par Google ?
- 20:30 Un site HTTPS-only pose-t-il un problème SEO ?
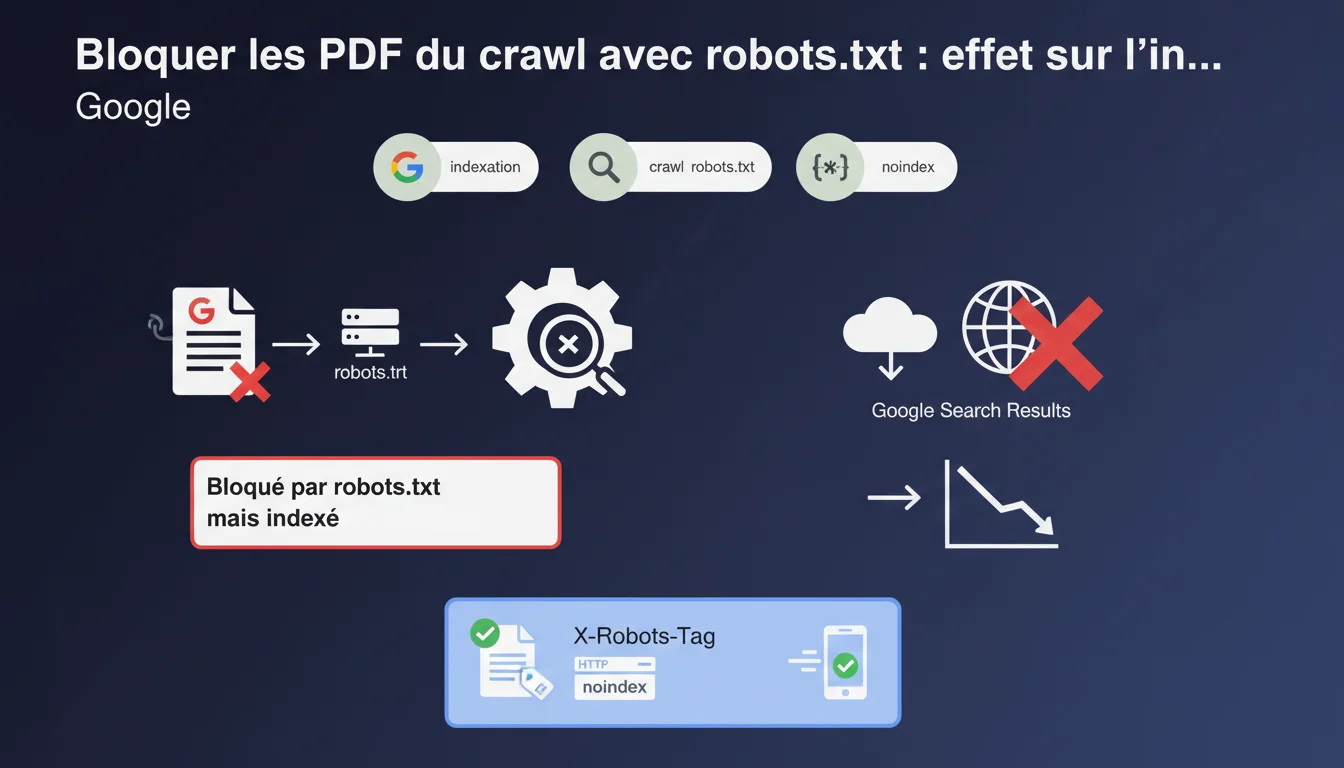
Bloquer un PDF via robots.txt n'empêche pas Google de l'indexer — il peut le faire sans le crawler, mais la page ne sera pas affichée en résultats. Google recommande plutôt d'utiliser X-Robots-Tag: noindex dans l'en-tête HTTP pour contrôler proprement l'indexation des fichiers PDF.
Ce qu'il faut comprendre
Pourquoi un PDF bloqué par robots.txt peut-il quand même être indexé ?
Google différencie crawl et indexation. Bloquer un fichier PDF avec robots.txt empêche Googlebot de le télécharger et d'en lire le contenu. Mais si ce PDF reçoit des liens externes ou internes, Google peut créer une entrée dans son index basée uniquement sur les signaux externes : texte d'ancre, contexte des liens, URL elle-même.
C'est ce que signifie le statut « Bloqué par robots.txt mais indexé » dans la Search Console. La page existe dans l'index, mais Google précise qu'elle ne sera pas affichée dans les résultats — du moins à terme. Ce mécanisme crée une zone grise qui déroute souvent les praticiens SEO.
Quelle différence entre « indexé » et « affiché dans les résultats » ?
Une URL peut être techniquement indexée sans jamais apparaître dans les SERP. Google maintient parfois des entrées fantômes dans son index, notamment pour préserver la structure de son graphe de liens ou pour des raisons techniques internes.
Dans le cas d'un PDF bloqué par robots.txt, l'URL peut subsister dans l'index tant que des liens pointent vers elle. Mais faute de contenu crawlé, Google ne peut pas évaluer sa pertinence — elle reste donc invisible pour les utilisateurs. C'est un état transitoire qui devrait se résorber avec le temps.
Pourquoi Google recommande-t-il X-Robots-Tag plutôt que robots.txt pour les PDF ?
L'en-tête HTTP X-Robots-Tag: noindex offre un contrôle propre et explicite sur l'indexation. Contrairement à robots.txt qui bloque le crawl sans empêcher l'indexation, le X-Robots-Tag permet à Google de crawler le fichier pour découvrir la directive, puis de respecter le noindex.
Cette approche évite les ambiguïtés. Google comprend clairement que vous ne souhaitez pas indexer le PDF, et aucune entrée fantôme ne subsiste dans l'index. C'est la méthode préconisée pour les fichiers PDF, images, ou tout contenu non-HTML que vous voulez exclure des résultats de recherche.
- Robots.txt bloque le crawl mais n'empêche pas une indexation partielle basée sur des signaux externes
- Le statut « Bloqué par robots.txt mais indexé » signale une URL indexée sans contenu crawlé, invisible à terme dans les SERP
- X-Robots-Tag: noindex dans l'en-tête HTTP garantit un contrôle explicite sur l'indexation des PDF
- Google peut maintenir des entrées fantômes dans son index tant que des liens pointent vers l'URL bloquée
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Sur le fond, oui. Le comportement décrit correspond à ce qu'on observe dans la Search Console depuis des années. Des PDF bloqués par robots.txt apparaissent régulièrement avec ce statut ambigu « indexé mais bloqué », surtout s'ils reçoivent des backlinks de qualité.
Par contre — et c'est là que ça coince — Google reste flou sur la temporalité. « Ne sera pas affiché dans les résultats à l'avenir » ne signifie pas grand-chose. Combien de temps une URL peut-elle rester dans cet état limbo ? Des semaines ? Des mois ? [A vérifier] Google ne donne aucun délai précis, ce qui complique le diagnostic pour les audits SEO.
Quels risques concrets avec robots.txt sur des PDF sensibles ?
Le vrai problème, c'est la fuite d'information. Si vous bloquez un PDF confidentiel avec robots.txt en pensant qu'il restera invisible, vous vous trompez. L'URL peut apparaître dans les résultats avec un snippet généré à partir du texte d'ancre ou de la structure de l'URL elle-même.
J'ai vu des cas où des documents internes apparaissaient dans Google avec des titres reconstruits à partir des backlinks, alors qu'ils étaient bloqués en robots.txt. Résultat : des clics, des erreurs 403 ou 404 côté utilisateur, et une confusion totale. Pour tout contenu que vous voulez réellement masquer, robots.txt ne suffit pas — il faut authentification serveur ou noindex explicite.
Pourquoi X-Robots-Tag reste la solution la plus fiable ?
Parce qu'elle coupe court à toute ambiguïté. Google crawl le fichier, lit la directive noindex dans l'en-tête, et supprime l'URL de l'index. Pas d'état intermédiaire, pas d'entrée fantôme qui traîne pendant des semaines.
L'implémentation est simple côté serveur — quelques lignes dans Apache ou Nginx. Le seul inconvénient : il faut que Google puisse crawler le fichier pour lire la directive. Si vous bloquez simultanément en robots.txt, la directive ne sera jamais lue. C'est pour ça que Google insiste sur cette méthode plutôt que sur robots.txt pour gérer l'indexation des PDF.
Impact pratique et recommandations
Que faire si vous voulez empêcher l'indexation de PDF ?
Oubliez robots.txt pour ce cas d'usage. Configurez plutôt un X-Robots-Tag: noindex dans l'en-tête HTTP de vos fichiers PDF. Sur Apache, ajoutez cette directive dans votre .htaccess ou dans la config du VirtualHost :
<FilesMatch "\.pdf$">
Header set X-Robots-Tag "noindex, nofollow"
</FilesMatch>
Sur Nginx, utilisez cette syntaxe dans votre bloc server ou location :
location ~* \.pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}
Vérifiez ensuite avec un curl -I https://votresite.com/fichier.pdf que l'en-tête est bien présent. Si vous gérez des milliers de PDF, automatisez cette vérification via un crawler comme Screaming Frog ou OnCrawl.
Comment corriger des PDF déjà bloqués par robots.txt ?
Commencez par identifier les URL concernées dans la Search Console, section Couverture, filtre « Bloqué par robots.txt mais indexé ». Notez la liste complète.
Supprimez ensuite les règles Disallow concernant ces PDF dans votre robots.txt. Ajoutez simultanément le X-Robots-Tag: noindex dans l'en-tête HTTP de ces fichiers. Google pourra alors les crawler, lire la directive noindex, et les supprimer proprement de l'index.
Attendez quelques semaines que Google recrawl. Si vous êtes pressé, soumettez manuellement les URL via l'outil d'inspection d'URL dans la Search Console. Attention : cette méthode ne fonctionne que pour un volume limité — au-delà de 50-100 PDF, il faut laisser le crawl naturel faire son travail.
Quelles erreurs éviter absolument ?
- Ne bloquez jamais un PDF sensible uniquement avec robots.txt — l'URL peut fuiter dans les SERP
- N'ajoutez pas X-Robots-Tag sur une URL déjà bloquée en robots.txt — Google ne pourra pas lire la directive
- Ne supprimez pas brutalement des règles robots.txt sans mettre en place une alternative (noindex ou authentification)
- N'ignorez pas le statut « Bloqué par robots.txt mais indexé » dans la Search Console — c'est un signal d'ambiguïté à traiter
- Ne confondez pas « indexé » et « affiché dans les résultats » — une URL peut être indexée sans jamais apparaître dans les SERP
❓ Questions frequentes
Peut-on bloquer un PDF en robots.txt tout en évitant qu'il soit indexé ?
Combien de temps une URL reste-t-elle dans l'état 'Bloqué par robots.txt mais indexé' ?
Le X-Robots-Tag fonctionne-t-il sur tous les types de fichiers ?
Que faire si mes PDF sont déjà indexés et je veux les supprimer ?
Peut-on combiner robots.txt et X-Robots-Tag sur un même PDF ?
🎥 De la même vidéo 17
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 27/03/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.