Declaration officielle
Autres déclarations de cette vidéo 17 ▾
- 1:24 Pourquoi Google republie-t-il des guides sur robots.txt et meta robots maintenant ?
- 7:02 GoogleBot crawle-t-il des URLs que votre site n'a jamais générées ?
- 7:27 Pourquoi Search Console et Google Analytics affichent-ils des chiffres différents ?
- 8:07 Pourquoi Search Console et Google Analytics affichent-ils des données différentes ?
- 8:51 Combien de temps Google met-il vraiment à reconnaître une correction de balise noindex ?
- 9:49 Pourquoi Google met-il autant de temps à reconnaître la suppression d'une balise noindex ?
- 11:11 L'encodage des caractères spéciaux dans le code source nuit-il vraiment au référencement ?
- 11:11 L'encodage des caractères spéciaux dans le code source pose-t-il un problème pour le SEO ?
- 11:47 Comment bloquer efficacement les PDF du crawl Google sans risquer l'indexation ?
- 11:51 Faut-il vraiment bloquer les PDF avec robots.txt ou utiliser noindex ?
- 14:14 Combien de temps Google met-il vraiment à afficher votre nouveau nom de site ?
- 14:14 Comment forcer Google à afficher le bon nom de votre site dans les SERP ?
- 14:59 Pourquoi Google pénalise-t-il les noms de marque trop similaires dans les SERP ?
- 15:14 Faut-il éviter les noms de marque similaires pour ne pas nuire à son référencement naturel ?
- 19:01 Pourquoi Google refuse-t-il de détailler ses critères de classification adulte ?
- 20:13 Un site 100% HTTPS sans version HTTP est-il pénalisé par Google ?
- 20:30 Un site HTTPS-only pose-t-il un problème SEO ?
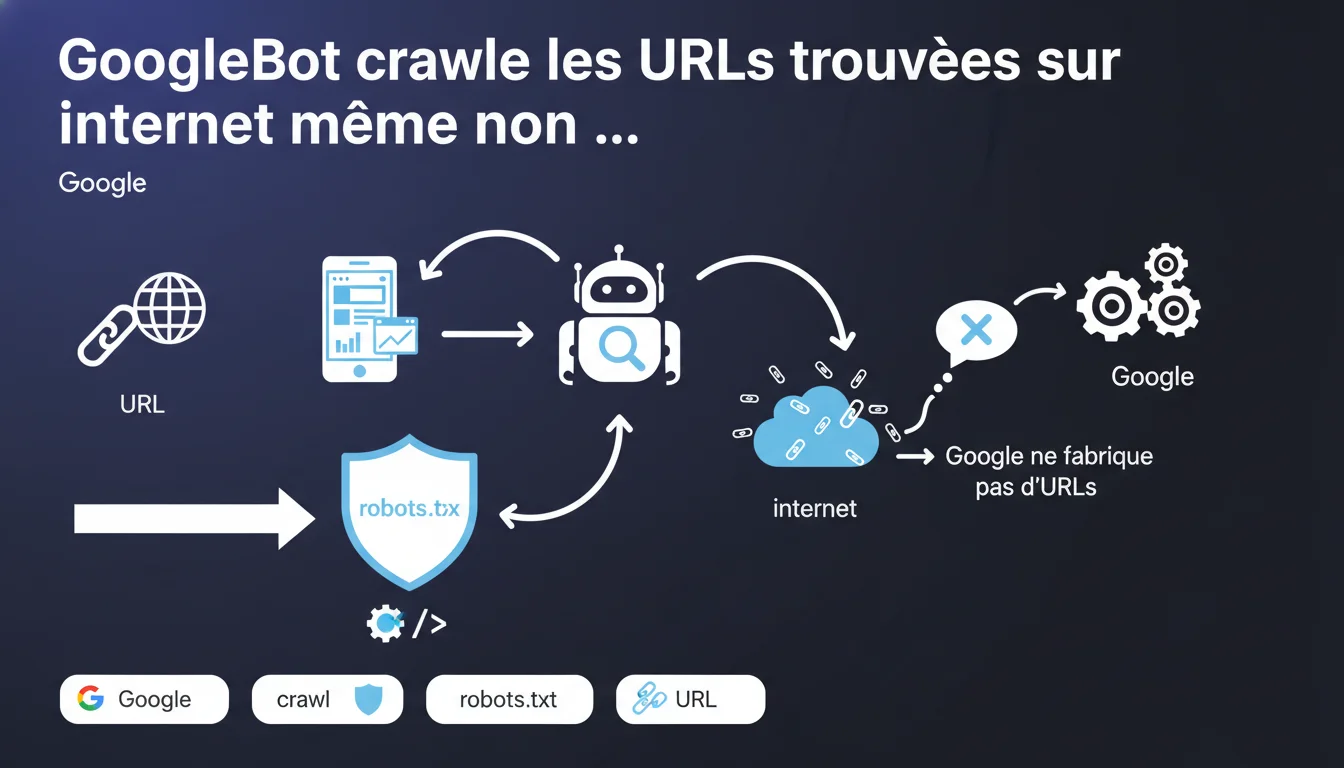
GoogleBot crawle toutes les URLs qu'il découvre sur le web, qu'elles proviennent de votre site ou non. Google ne fabrique pas d'URLs de toutes pièces, mais suit celles qu'il trouve via des liens externes, des redirections ou des références tierces. Pour bloquer le crawl d'URLs indésirables, robots.txt reste votre seul levier.
Ce qu'il faut comprendre
GoogleBot invente-t-il des URLs pour crawler votre site ?
Non. Cette déclaration met fin à un mythe tenace : Google ne génère pas d'URLs arbitraires pour tester votre site. Le bot suit exclusivement les URLs qu'il rencontre dans son exploration du web.
Concrètement ? Si une URL apparaît dans un lien externe, un sitemap tiers, une redirection mal configurée ou même une référence dans un fichier log accessible, GoogleBot la crawlera. Même si cette URL n'existe pas dans votre architecture initiale.
D'où viennent ces URLs que vous n'avez pas créées ?
Plusieurs sources courantes : des backlinks pointant vers des URLs erronées, des paramètres UTM ajoutés par des partenaires, des tests de développeurs exposés publiquement, ou encore des variantes d'URLs générées par des CMS (pagination infinie, filtres combinés, sessions).
Les scrapers et outils tiers peuvent aussi créer des liens vers des pages inexistantes. Une faute de frappe dans un article de blog externe ? GoogleBot tentera de crawler cette URL si elle est liée.
Robots.txt est-il vraiment le seul rempart ?
Oui, pour empêcher le crawl. Mais attention : robots.txt ne bloque pas l'indexation. Une URL peut apparaître dans les résultats même si elle n'a jamais été crawlée, tant qu'elle est mentionnée ailleurs sur le web.
- GoogleBot suit les URLs découvertes, quelle que soit leur origine
- Google ne fabrique pas d'URLs — il explore celles trouvées via liens, redirections, sitemaps externes
- Robots.txt bloque le crawl, pas l'indexation
- Les URLs indésirables proviennent souvent de backlinks erronés, paramètres UTM, tests dev ou CMS mal configurés
- Une URL jamais générée par vous peut quand même être crawlée si elle est référencée ailleurs
Avis d'un expert SEO
Cette déclaration colle-t-elle aux observations terrain ?
Globalement, oui. Les audits de logs montrent systématiquement que GoogleBot crawle des URLs jamais générées côté site : anciens chemins migrés, variantes de paramètres, pages de test oubliées. Ces URLs apparaissent toujours via une source externe identifiable.
Cependant — et Google reste évasif là-dessus — certains cas limites posent question. Les URLs de pagination extrême (page=9999) ou les combinaisons de filtres jamais linkées apparaissent parfois en crawl. Sont-elles vraiment découvertes par hasard ou GoogleBot teste-t-il certains patterns ? [A vérifier]
Quelles nuances cette déclaration omet-elle ?
Google dit ne pas "fabriquer" d'URLs, mais il normalise, combine et suit des redirections de manière agressive. Une URL avec session ID peut mener à 10 variantes crawlées. Est-ce de la fabrication ? Non. Est-ce du crawl découlant d'une découverte unique ? Techniquement oui, mais l'effet est le même.
Autre point : les sitemaps XML externes. Si un agrégateur référence votre site avec des URLs modifiées, GoogleBot les crawlera. Vous n'avez pas généré ces URLs, mais elles existent dans l'écosystème web — frontière floue.
Dans quels cas cette logique pose-t-elle problème ?
Les sites avec génération dynamique d'URLs (filtres, tri, search) sont vulnérables. Un seul lien externe vers une combinaison de paramètres peut déclencher un crawl massif de variantes. GoogleBot ne les invente pas, mais il explore systématiquement les liens trouvés dans les pages crawlées.
Les migrations mal gérées créent aussi des situations absurdes : d'anciens backlinks pointent vers des URLs obsolètes, GoogleBot les crawle indéfiniment malgré des 404. Techniquement conforme à cette déclaration, mais coûteux en crawl budget.
Impact pratique et recommandations
Que faut-il faire pour maîtriser le crawl d'URLs externes ?
Première étape : auditer vos logs serveur pour identifier les URLs crawlées que vous n'avez pas générées. Classez-les par source (backlinks, paramètres, redirections). Décidez ensuite URL par URL : bloquer, rediriger ou laisser.
Pour les URLs parasites, deux leviers principaux. Robots.txt si vous voulez empêcher le crawl définitivement. Redirections 301 vers la version canonique si ces URLs ont du jus SEO à récupérer.
Quelles erreurs éviter absolument ?
Ne bloquez jamais via robots.txt une URL que vous voulez désindexer. C'est le piège classique : en bloquant le crawl, vous empêchez GoogleBot de voir la balise noindex. Résultat ? L'URL reste indexée indéfiniment avec la mention "Aucune information disponible".
Autre erreur fréquente : ignorer les backlinks toxiques qui génèrent des URLs crawlées en masse. Un annuaire mal codé peut créer des milliers de variantes. Désavouez ces domaines si le crawl devient ingérable.
Comment vérifier que votre stratégie fonctionne ?
Surveillez l'évolution du crawl budget dans Google Search Console, section "Statistiques d'exploration". Si le nombre de pages crawlées par jour augmente sans raison, c'est souvent le signe d'URLs externes qui polluent le crawl.
Croisez avec un outil d'analyse de logs (Screaming Frog Log Analyzer, Botify, OnCrawl). Filtrez les URLs crawlées mais absentes de votre sitemap. Celles-ci proviennent forcément de sources externes.
- Auditez vos logs serveur mensuellement pour repérer les URLs crawlées non générées par votre site
- Identifiez la source de chaque URL parasite : backlink, paramètre UTM, redirection, référence externe
- Utilisez robots.txt uniquement pour bloquer le crawl d'URLs sans valeur SEO
- Redirigez en 301 les URLs avec backlinks de qualité vers leur équivalent canonique
- Pour désindexer une URL crawlée par erreur, utilisez noindex PUIS bloquez via robots.txt (jamais l'inverse)
- Surveillez Google Search Console pour détecter les pics de crawl anormaux
- Désavouez les domaines générant massivement des URLs parasites via backlinks
- Normalisez vos URLs côté CMS pour éviter la prolifération de variantes
❓ Questions frequentes
GoogleBot peut-il crawler une URL qui n'existe pas sur mon site ?
Bloquer une URL via robots.txt empêche-t-il son indexation ?
D'où viennent les URLs crawlées que je n'ai jamais créées ?
Comment savoir si mon crawl budget est gaspillé par des URLs externes ?
Faut-il rediriger ou bloquer les URLs découvertes par des backlinks ?
🎥 De la même vidéo 17
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 27/03/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.