Official statement
Other statements from this video 17 ▾
- 1:24 Pourquoi Google republie-t-il des guides sur robots.txt et meta robots maintenant ?
- 7:02 GoogleBot crawle-t-il des URLs que votre site n'a jamais générées ?
- 7:27 Pourquoi Search Console et Google Analytics affichent-ils des chiffres différents ?
- 7:27 GoogleBot crawle-t-il vraiment des URLs que votre site n'a jamais générées ?
- 8:07 Pourquoi Search Console et Google Analytics affichent-ils des données différentes ?
- 9:49 Pourquoi Google met-il autant de temps à reconnaître la suppression d'une balise noindex ?
- 11:11 L'encodage des caractères spéciaux dans le code source nuit-il vraiment au référencement ?
- 11:11 L'encodage des caractères spéciaux dans le code source pose-t-il un problème pour le SEO ?
- 11:47 Comment bloquer efficacement les PDF du crawl Google sans risquer l'indexation ?
- 11:51 Faut-il vraiment bloquer les PDF avec robots.txt ou utiliser noindex ?
- 14:14 Combien de temps Google met-il vraiment à afficher votre nouveau nom de site ?
- 14:14 Comment forcer Google à afficher le bon nom de votre site dans les SERP ?
- 14:59 Pourquoi Google pénalise-t-il les noms de marque trop similaires dans les SERP ?
- 15:14 Faut-il éviter les noms de marque similaires pour ne pas nuire à son référencement naturel ?
- 19:01 Pourquoi Google refuse-t-il de détailler ses critères de classification adulte ?
- 20:13 Un site 100% HTTPS sans version HTTP est-il pénalisé par Google ?
- 20:30 Un site HTTPS-only pose-t-il un problème SEO ?
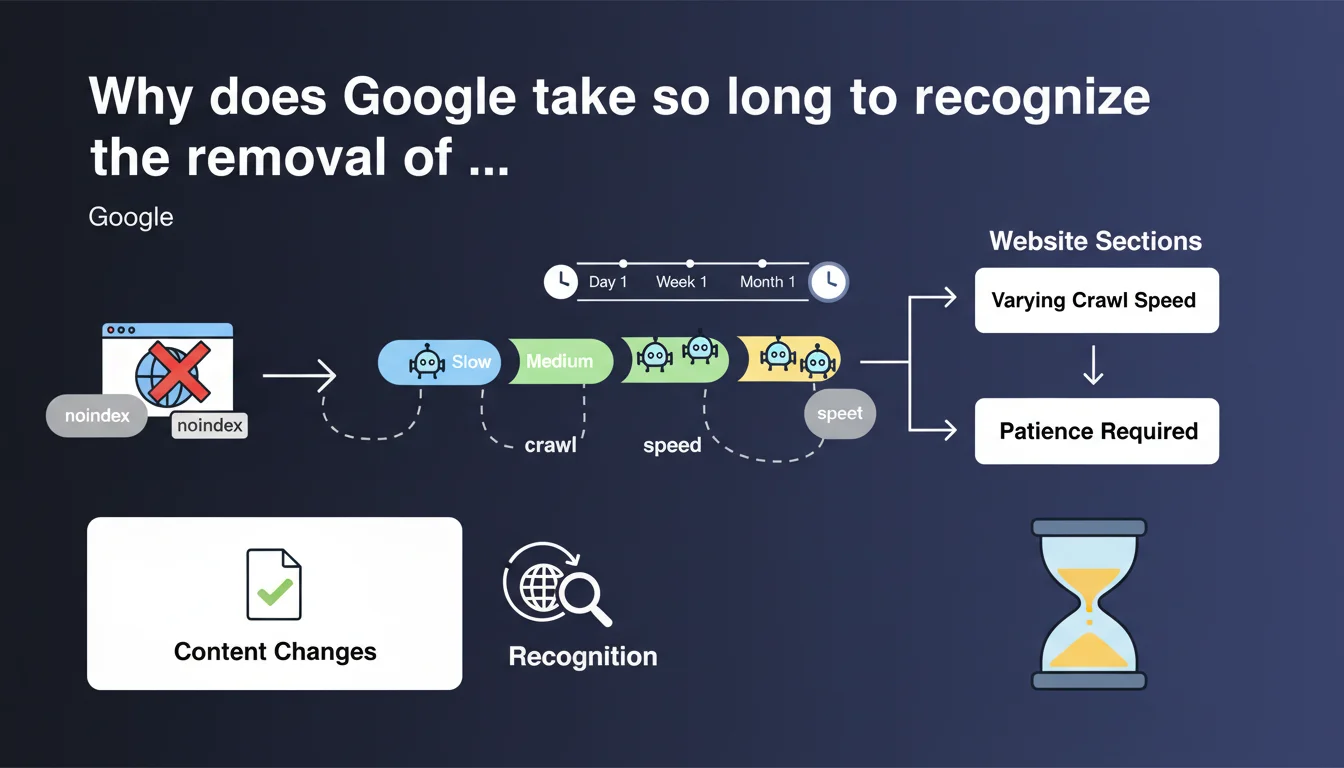
Google confirms that recognizing a noindex error correction can take variable time depending on site sections and allocated crawl speed. No guaranteed timeline — you need to wait and monitor. This vagueness reflects an opaque prioritization logic on the Googlebot side.
What you need to understand
Google acknowledges here a frustrating reality: correcting a noindex tag applied by mistake doesn't automatically trigger immediate reindexing. The engine must first recrawl the page, notice the directive is gone, then process it again.
This delay varies considerably from site to site, even across different sections of the same site. No communicated SLA, no promise of processing within 48 hours or 7 days. Just: "be patient".
Why won't Google provide a specific timeline?
Because crawl speed depends on hundreds of signals: site popularity, update frequency, technical health, allocated crawl budget, priority level of the section in question. A page buried 5 clicks from the homepage will take longer than a flagship category.
Google doesn't want to commit to a number it couldn't deliver for everyone. Result: a cautious statement, almost tautological — "it takes time, just wait".
What specifically influences this recognition delay?
Several factors come into play. The crawl frequency of the affected section is decisive: if Googlebot only passes once a month, you'll wait a month. The page depth in your site structure matters too: the deeper it sits, the later it gets recrawled.
Finally, your site's overall context counts: a slow site, full of errors, or with exhausted crawl budget on redirect chains will see corrections processed sluggishly. Google doesn't prioritize what isn't strategic.
- Crawling isn't instantaneous — even after fixing, you must wait for Googlebot to return
- Poorly visited or deeply nested sections get recrawled less frequently
- Your site's overall crawl budget determines how fast changes are processed
- No guaranteed timeline — Google refuses to commit to a specific number
- Patience is mandatory — forcing crawls via Search Console helps, but guarantees nothing
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes, unfortunately. In practice, we regularly observe delays of several weeks between fixing a noindex error and the page actually reappearing in the index. Sometimes faster on premium sites, sometimes endless on neglected ones.
What's frustrating is the complete lack of visibility: Search Console shows "Page excluded by noindex tag" until Google recrawls, and meanwhile, there's no way to know if Googlebot even plans to return. [To verify]: Google claims that requesting a URL inspection speeds things up, but in practice, results are inconsistent.
What nuances should we add to this claim?
Let's be honest: not all sites are equal when it comes to crawling. A news outlet with high crawl rates will see corrections processed within days. A B2B brochure site updated once a quarter will wait weeks.
Furthermore, Google says nothing about emergency scenarios. If you accidentally noindex 10,000 product pages in production, patience isn't an option. In such cases, multiplying URL inspection requests and resubmitting crawls via XML sitemap can accelerate things — but without guarantees.
Finally, be careful: this statement covers only the delay to recognize the change, not the delay for complete reindexing. Once Google detects the directive is gone, it still must decide whether the page deserves indexing. These are two distinct steps.
In what cases doesn't this rule really apply?
If you control crawl budget with surgical precision — via robots.txt, Search Console settings, advanced technical optimization — you can force faster action. But this requires advanced mastery and levers that 90% of sites never pull.
Similarly, sites deploying server-side rendering or poorly managed JavaScript architectures may see even longer delays, since Googlebot must first render the page to notice the missing noindex. Google doesn't mention this case, but it complicates everything.
Practical impact and recommendations
What should you do concretely after fixing a noindex error?
First, verify the fix is properly deployed by crawling the page yourself with Screaming Frog or Oncrawl. Check both the HTML source code and HTTP headers — sometimes an X-Robots-Tag: noindex persists even if the meta tag is removed.
Next, request a URL inspection in Search Console to signal Google that the page has changed. Do this on priority URLs, not 10,000 pages at once — it won't speed things up and risks being ignored.
Finally, monitor progress in Search Console via the "Pages" report and server logs if accessible. You'll see when Googlebot returns and whether the page shifts from "Excluded" to "Indexed".
What mistakes should you avoid during this waiting period?
Don't make multiple changes in parallel. If you tweak 15 parameters simultaneously — content, internal links, meta description — you won't know what worked (or didn't). Isolating the variable is essential for proper analysis.
Also avoid bombarding Google with repeated inspection requests every 48 hours. It's pointless — Google doesn't crawl on demand like a premium service. Once weekly on critical URLs is plenty.
And above all, don't conclude a page is "lost" if it isn't reindexed within 10 days. That's a short timeline for Google — wait at least 3-4 weeks before panicking.
How can you optimize the speed at which corrections are recognized?
Work on your overall crawl budget: eliminate unnecessary pages, block parasitic URLs in robots.txt, fix redirect chains, speed up server response time. The more efficiently Googlebot crawls, the faster it detects your fixes.
Strengthen internal linking to corrected pages from frequently crawled sections (homepage, flagship categories). This increases the odds they'll be discovered quickly on Googlebot's next pass.
Push an updated XML sitemap including only corrected URLs with a recent
- Crawl your site yourself to confirm noindex tag removal (HTML + HTTP headers)
- Request URL inspection in Search Console for priority pages
- Monitor server logs to detect Googlebot's return
- Change nothing else in parallel — isolate the variable to measure impact
- Optimize overall crawl budget: server speed, redirects, clean architecture
- Strengthen internal linking to corrected pages
- Submit an updated XML sitemap with recent lastmod date
- Wait 3-4 weeks before concluding failure — patience is mandatory
❓ Frequently Asked Questions
Combien de temps faut-il attendre après avoir corrigé une balise noindex ?
Demander une inspection d'URL dans Search Console accélère-t-il vraiment la réindexation ?
Pourquoi certaines pages sont-elles réindexées rapidement et d'autres mettent des semaines ?
Que faire si la page n'est toujours pas indexée après un mois ?
Peut-on forcer Google à crawler une page immédiatement après correction ?
🎥 From the same video 17
Other SEO insights extracted from this same Google Search Central video · published on 27/03/2025
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.