Official statement
Other statements from this video 17 ▾
- 1:24 Pourquoi Google republie-t-il des guides sur robots.txt et meta robots maintenant ?
- 7:27 Pourquoi Search Console et Google Analytics affichent-ils des chiffres différents ?
- 7:27 GoogleBot crawle-t-il vraiment des URLs que votre site n'a jamais générées ?
- 8:07 Pourquoi Search Console et Google Analytics affichent-ils des données différentes ?
- 8:51 Combien de temps Google met-il vraiment à reconnaître une correction de balise noindex ?
- 9:49 Pourquoi Google met-il autant de temps à reconnaître la suppression d'une balise noindex ?
- 11:11 L'encodage des caractères spéciaux dans le code source nuit-il vraiment au référencement ?
- 11:11 L'encodage des caractères spéciaux dans le code source pose-t-il un problème pour le SEO ?
- 11:47 Comment bloquer efficacement les PDF du crawl Google sans risquer l'indexation ?
- 11:51 Faut-il vraiment bloquer les PDF avec robots.txt ou utiliser noindex ?
- 14:14 Combien de temps Google met-il vraiment à afficher votre nouveau nom de site ?
- 14:14 Comment forcer Google à afficher le bon nom de votre site dans les SERP ?
- 14:59 Pourquoi Google pénalise-t-il les noms de marque trop similaires dans les SERP ?
- 15:14 Faut-il éviter les noms de marque similaires pour ne pas nuire à son référencement naturel ?
- 19:01 Pourquoi Google refuse-t-il de détailler ses critères de classification adulte ?
- 20:13 Un site 100% HTTPS sans version HTTP est-il pénalisé par Google ?
- 20:30 Un site HTTPS-only pose-t-il un problème SEO ?
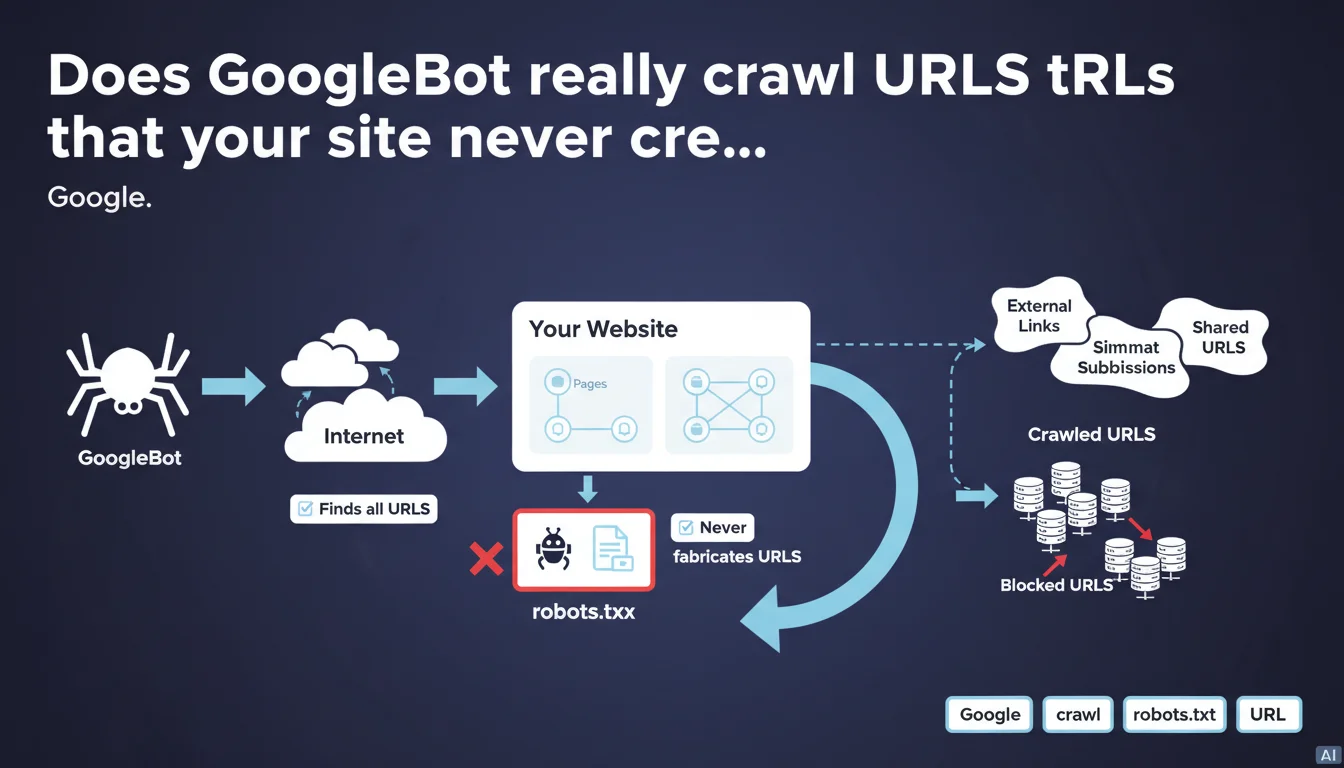
Google crawls all URLs it finds on the web, even if your site never created them. The search engine never fabricates URLs itself, but follows links discovered everywhere on the Internet. If certain URLs pose problems, it's the robots.txt file's job to block them.
What you need to understand
What does this concretely mean for your website?
GoogleBot discovers URLs through external sources: links on other websites, redirects, parameters added by third-party tools, shares on social networks. These URLs can point to your domain without you ever having generated them yourself.
The robot doesn't create URLs from scratch. It follows what it finds. But this discovery can lead GoogleBot to crawl URL variants, test pages, poorly secured admin spaces, or unlikely tracking parameters.
Why does Google emphasize this point?
Because some webmasters are surprised to see bizarre URLs in their logs. They think Google "invents" paths. That's wrong.
If a URL appears in Search Console or your logs, it exists somewhere on the Internet. A broken link, an old backlink, a scraper — it doesn't matter. Google found it, didn't fabricate it.
What's the difference with canonical URLs or redirects?
Google can crawl a URL not generated by your site, but that doesn't mean it will index it. Canonicals, 301 redirects, and meta robots tags come into play after crawling.
Crawling is one thing, indexation is another. This statement speaks only to the behavior of discovery and crawling.
- GoogleBot follows all links it discovers, even if they point to URLs you never created.
- The search engine never generates URLs on its own.
- robots.txt is the tool to prevent crawling of these unwanted URLs.
- The presence of a URL in your logs doesn't mean it will be indexed.
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes, absolutely. We regularly see URLs with tracking parameters (utm_, fbclid, gclid) or poorly controlled facets appearing in Search Console. These URLs were never generated by the CMS, but by third-party tools or users.
Google follows these links because they exist on the web. It's consistent with how a crawler works, exploring the entire available link graph.
What nuances should be added to this statement?
Google doesn't fabricate URLs, agreed. But it can normalize certain forms (uppercase/lowercase, trailing slash) or follow redirect chains. The final result in the logs may seem different from the source URL.
Additionally, some JavaScript rendering tools can generate links on the client side that don't appear in raw HTML. GoogleBot crawls them anyway, which can give the impression that it "invents" paths. [To verify]: the distinction between URLs discovered via JS and URLs "fabricated" remains fuzzy in the official documentation.
In what cases does this rule cause problems?
When your site generates infinite dynamic URLs — calendars, combinatorial filters, user sessions. If these URLs are linked anywhere, GoogleBot will crawl them. Your crawl budget gets exhausted on pages with no value.
Practical impact and recommendations
What should you concretely do to control this crawl?
Identify the external link sources that point to URLs you don't want crawled. Use Search Console, your server logs, and tools like Screaming Frog to spot these URLs.
Then decide: block in robots.txt, redirect with 301, or canonicalize to the correct version. The choice depends on your objective — saving crawl budget or avoiding duplicate content.
What mistakes should you absolutely avoid?
Don't block in robots.txt URLs you want indexed. robots.txt prevents crawling, so Google can't read canonical tags or noindex tags on those pages.
Another trap: letting session or tracking parameters generate infinite URLs without managing them via the URL Parameters Tool in Search Console (even though Google deprecated it, the logic remains valid on the server side).
How can you verify that your site is compliant?
Audit your server logs regularly. Spot URLs crawled by GoogleBot that aren't part of your XML sitemap or normal site architecture.
Make sure your robots.txt properly blocks sensitive spaces (admin, test, staging). Test with Search Console's robots.txt testing tool.
- Audit your server logs to identify URLs not generated by your CMS.
- Block sensitive directories in robots.txt (admin, staging, dev).
- Use canonicals to consolidate URL variants.
- Redirect with 301 old or malformed URLs that still receive backlinks.
- Monitor Search Console for crawl errors on unexpected URLs.
- Clean up tracking parameters on the server side if possible (URL rewrites).
❓ Frequently Asked Questions
Google peut-il crawler une URL que mon site n'a jamais générée ?
Comment empêcher GoogleBot de crawler ces URLs indésirables ?
Pourquoi je vois des URLs bizarres avec des paramètres tracking dans Search Console ?
GoogleBot peut-il indexer une URL bloquée en robots.txt ?
Comment savoir quelles URLs GoogleBot crawle sur mon site ?
🎥 From the same video 17
Other SEO insights extracted from this same Google Search Central video · published on 27/03/2025
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.