Official statement
What you need to understand
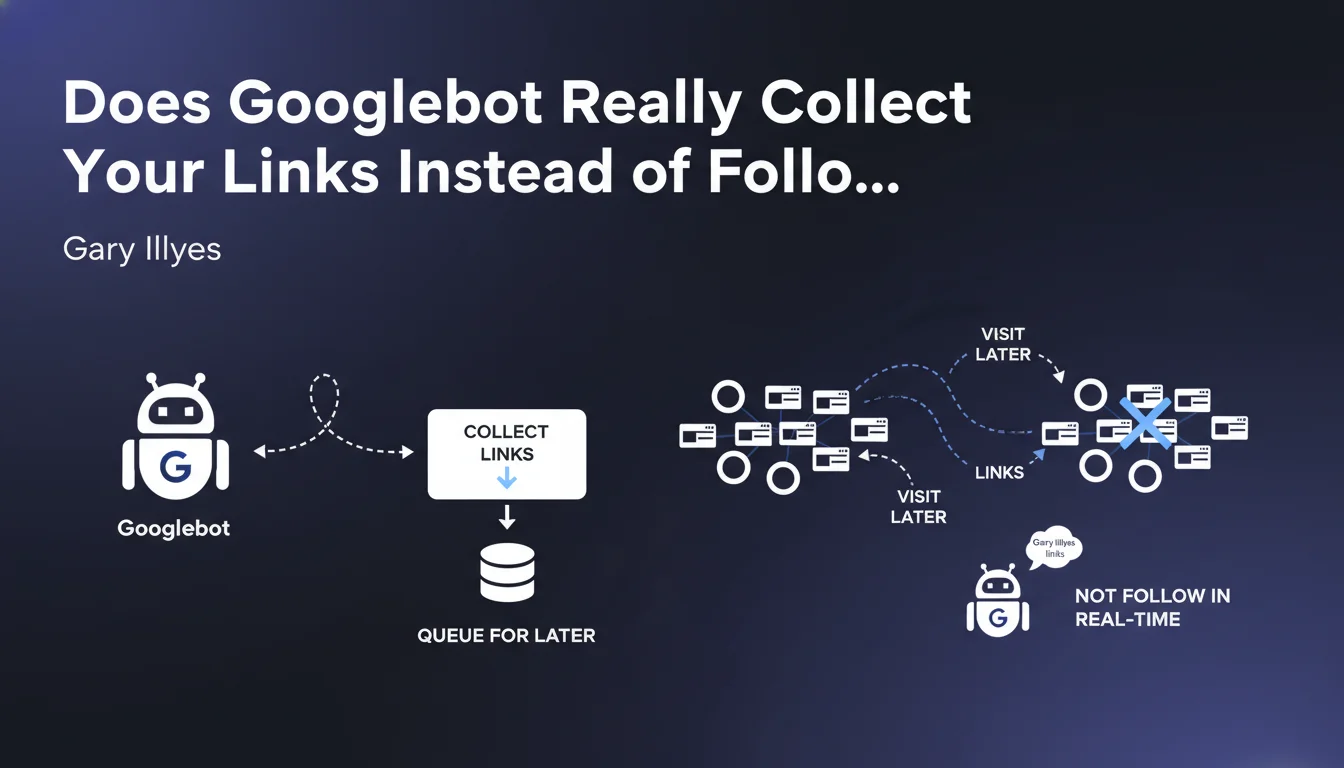
Google has always used the term "following links" in its official documentation, which suggests that Googlebot navigates from page to page in real-time, just as a user would. This revelation fundamentally changes our understanding of the process.
In reality, Googlebot first collects the links it discovers on a page, then stores them in a queue for later processing. It doesn't immediately move from one page to another via the links found.
This distinction may seem minor, but it has major implications for the speed of discovery and indexing of your content. The delay between discovering a link and actually visiting it depends on many factors such as crawl budget and the priority given to your site.
- Googlebot doesn't navigate continuously: it crawls in separate sessions
- Discovered links are queued before processing
- The delay between discovery and actual crawl varies depending on your site's crawl budget
- The concept of "crawl depth" takes on a different meaning with this collection system
- Link architecture influences crawl priority rather than immediate navigation
SEO Expert opinion
This clarification is completely consistent with behaviors observed in the field. It explains why new content isn't instantly crawled even when added to a page already well-explored by Google.
This also confirms why XML sitemaps remain crucial: they don't serve to guide Googlebot in real-time, but to feed its discovery queue. Similarly, this explains the variable delays observed between publishing content and its actual indexing.
This collection-based approach rather than sequential following allows Google to optimize its crawl resources and intelligently prioritize URLs to explore. The system can thus evaluate the priority of each collected link before deciding when and how often to visit it.
Practical impact and recommendations
This revelation should make you rethink your discoverability strategy and abandon the idea that placing a link is enough to guarantee a quick crawl. The focus must be on prioritization signals.
- Systematically use XML sitemaps to directly signal your priority URLs to Google, without waiting for them to be collected through crawling
- Leverage the URL inspection tool in Search Console to request immediate indexing of your strategic pages
- Pay particular attention to your internal linking so that links to your important pages are collected from pages with high crawl budget
- Place your strategic links early in the HTML and in frequently crawled areas to increase their chances of being collected quickly
- Optimize your crawl budget by eliminating unnecessary pages, redirect chains, and errors that waste Google's resources
- Diversify your discovery channels: don't rely solely on internal links, but combine sitemap, Indexing API, and quality external links
- Monitor discovery delays in Search Console to identify pages that take too long to be collected and then crawled
- Prioritize freshness in strategic areas: content regularly updated in well-crawled areas will see their links collected more frequently
Implementing these technical optimizations requires thorough analysis of your architecture and crawl patterns specific to your site. Given the complexity of these issues that directly impact your visibility, engaging a specialized SEO agency can prove valuable to benefit from a personalized diagnosis and tailored support in optimizing your crawlability.
💬 Comments (0)
Be the first to comment.