Declaration officielle
Ce qu'il faut comprendre
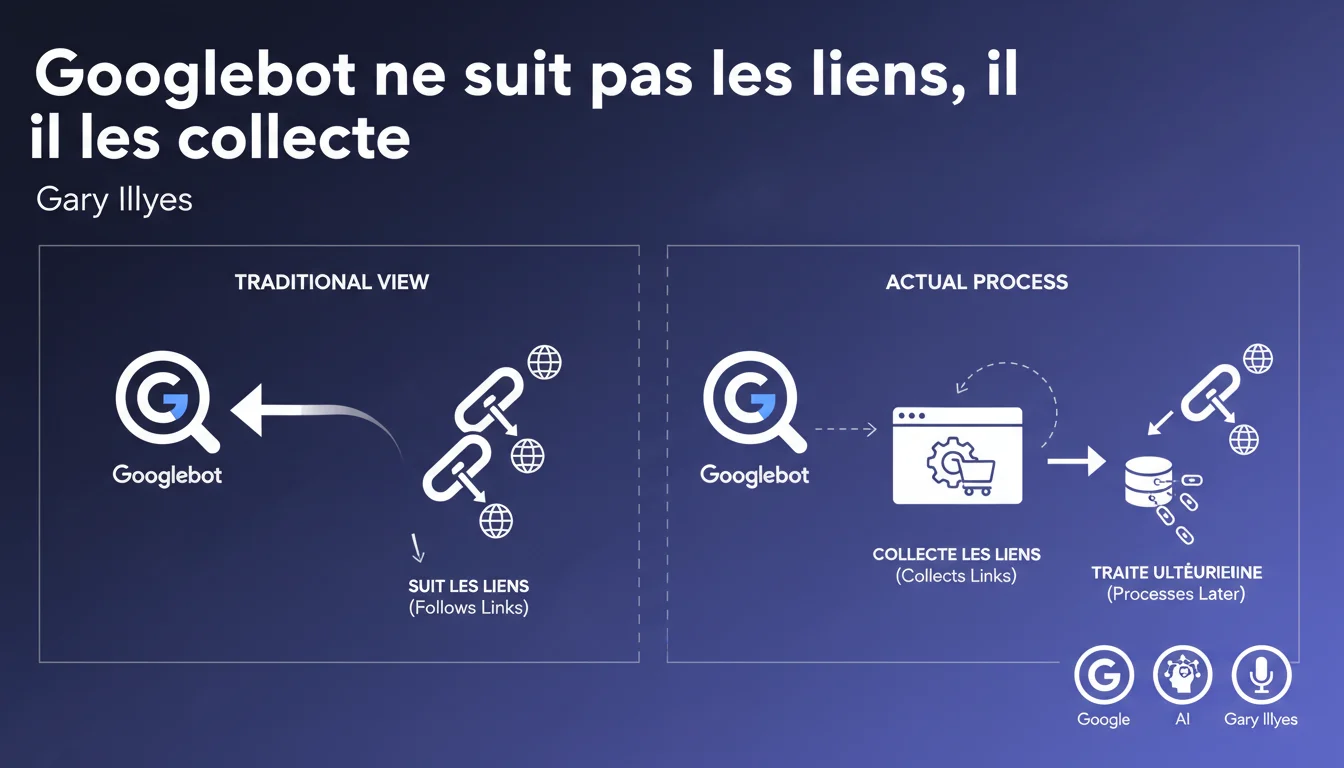
Google utilise depuis toujours le terme "suivre des liens" dans sa documentation officielle, ce qui laisse penser que Googlebot navigue de page en page en temps réel, comme le ferait un internaute. Cette révélation change fondamentalement notre compréhension du processus.
En réalité, Googlebot collecte d'abord les liens qu'il découvre sur une page, puis les stocke dans une file d'attente pour un traitement ultérieur. Il ne passe pas immédiatement d'une page à l'autre via les liens trouvés.
Cette distinction peut sembler mineure, mais elle a des implications majeures sur la vitesse de découverte et d'indexation de vos contenus. Le délai entre la découverte d'un lien et sa visite effective dépend de nombreux facteurs comme le budget crawl et la priorité accordée à votre site.
- Googlebot ne navigue pas en continu : il explore par sessions distinctes
- Les liens découverts sont mis en file d'attente avant traitement
- Le délai entre découverte et crawl effectif varie selon le budget crawl de votre site
- La notion de "profondeur de crawl" prend un sens différent avec ce système de collecte
- L'architecture de liens influe sur la priorité d'exploration plutôt que sur le parcours immédiat
Avis d'un expert SEO
Cette clarification est totalement cohérente avec les comportements observés sur le terrain. Elle explique pourquoi un nouveau contenu n'est pas instantanément crawlé même quand on l'ajoute à une page déjà bien explorée par Google.
Cela confirme également pourquoi les sitemaps XML restent cruciaux : ils ne servent pas à guider Googlebot en temps réel, mais à alimenter sa file d'attente de découverte. De même, cela explique les délais variables observés entre la publication d'un contenu et son indexation effective.
Cette approche par collecte plutôt que par suivi séquentiel permet à Google d'optimiser ses ressources de crawl et de prioriser intelligemment les URLs à explorer. Le système peut ainsi évaluer la priorité de chaque lien collecté avant de décider quand et à quelle fréquence le visiter.
Impact pratique et recommandations
Cette révélation doit vous faire repenser votre stratégie de découvrabilité et abandonner l'idée que placer un lien suffit à garantir un crawl rapide. L'accent doit être mis sur les signaux de priorisation.
- Utilisez systématiquement les sitemaps XML pour signaler directement vos URLs prioritaires à Google, sans attendre qu'elles soient collectées via le crawl
- Exploitez l'outil d'inspection d'URL dans la Search Console pour demander l'indexation immédiate de vos pages stratégiques
- Soignez particulièrement votre maillage interne pour que les liens vers vos pages importantes soient collectés depuis des pages à fort budget crawl
- Placez vos liens stratégiques en début de HTML et dans des zones fréquemment crawlées pour augmenter leur chance d'être collectés rapidement
- Optimisez votre budget crawl en éliminant les pages inutiles, les chaînes de redirections et les erreurs qui gaspillent les ressources de Google
- Diversifiez vos canaux de découverte : ne comptez pas uniquement sur les liens internes, mais combinez sitemap, API Indexing, et liens externes de qualité
- Surveillez les délais de découverte dans la Search Console pour identifier les pages qui mettent trop de temps à être collectées puis crawlées
- Priorisez la fraîcheur des zones stratégiques : les contenus mis à jour régulièrement dans des zones bien crawlées verront leurs liens collectés plus fréquemment
La mise en œuvre de ces optimisations techniques nécessite une analyse approfondie de votre architecture et des patterns de crawl spécifiques à votre site. Face à la complexité de ces enjeux qui impactent directement votre visibilité, faire appel à une agence SEO spécialisée peut s'avérer judicieux pour bénéficier d'un diagnostic personnalisé et d'un accompagnement sur mesure dans l'optimisation de votre crawlabilité.
💬 Commentaires (0)
Soyez le premier à commenter.