Official statement
Other statements from this video 22 ▾
- □ Pourquoi la position moyenne de Search Console ne reflète-t-elle pas un classement théorique mais des affichages réels ?
- □ Peut-on encore se permettre d'attendre qu'un classement instable se stabilise tout seul ?
- □ Faut-il vraiment produire plus de contenu pour améliorer son SEO ?
- □ Faut-il vraiment utiliser l'outil d'inspection d'URL pour indexer un nouveau site ?
- □ Combien de temps faut-il attendre pour voir les backlinks dans Search Console ?
- □ Pourquoi les données Search Console et Analytics ne concordent-elles jamais vraiment ?
- □ Search Console collecte-t-elle vraiment toutes les données sur les gros sites e-commerce ?
- □ Faut-il vraiment préférer noindex à disallow pour contrôler l'indexation ?
- □ Les produits en rupture de stock peuvent-ils vraiment être traités comme des soft 404 par Google ?
- □ Les outils de test Google crawlent-ils vraiment en temps réel ou utilisent-ils un cache ?
- □ Google utilise-t-il des algorithmes différents selon votre secteur d'activité ?
- □ Pourquoi Google ignore-t-il les sites agrégateurs de faible effort ?
- □ Google compte-t-il vraiment les clics sur les rich results comme des clics organiques ?
- □ L'ordre des liens dans le HTML influence-t-il vraiment la priorité de crawl de Google ?
- □ Faut-il vraiment éviter les URLs avec paramètres pour le SEO ?
- □ Pourquoi robots.txt bloque le crawl mais n'empêche pas l'indexation de vos pages ?
- □ Les produits en rupture de stock nuisent-ils au classement global de votre site e-commerce ?
- □ Le contenu dupliqué partiel pénalise-t-il vraiment vos pages ?
- □ Pourquoi Google refuse-t-il d'indexer plusieurs versions d'une même page malgré une canonicalisation correcte ?
- □ Comment Google choisit-il réellement quelle URL canoniser parmi vos contenus dupliqués ?
- □ Les mentions de marque sans lien ont-elles une valeur SEO ?
- □ Pourquoi un lien sans URL indexée ne sert strictement à rien ?
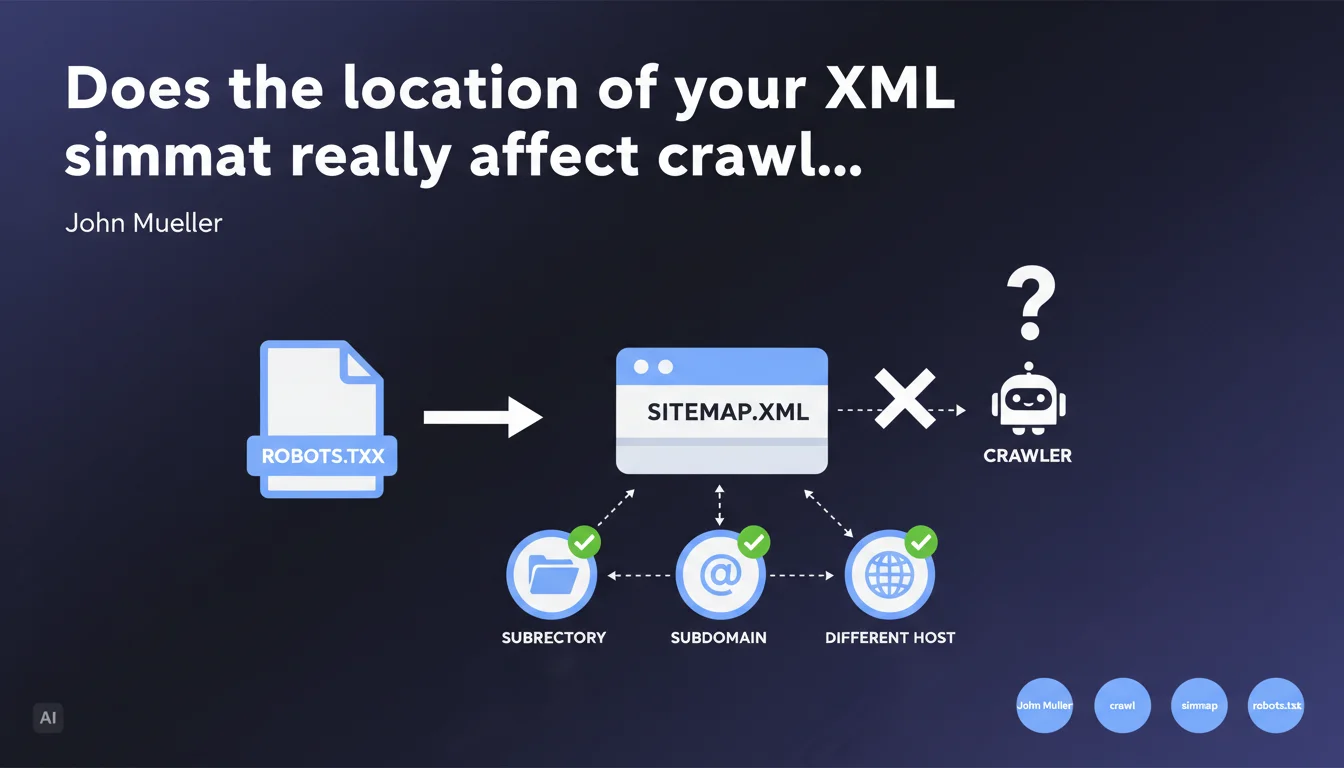
The physical location of the sitemap file has no impact on its effectiveness. Google can crawl it from a subdirectory, subdomain, or even a remote host, as long as it is declared in the robots.txt file. Only this declaration really matters.
What you need to understand
Why has the sitemap location long been considered important?
Historically, many SEO guides recommended placing the sitemap.xml at the root of the domain (https://example.com/sitemap.xml). This practice came from a time when standards were not clearly defined and certain tools imposed technical constraints.
The convention persisted out of habit — and because most CMSs automatically generated the file at that location. Few people really questioned this standard placement.
What does Mueller's statement actually mean in practical terms?
Google relies exclusively on the declaration in robots.txt or via Search Console to locate your sitemap. The physical file path doesn't factor into the equation.
You can therefore host your sitemap at cdn.example.com/data/sitemap.xml, example.com/wp-content/uploads/2023/sitemap.xml, or even external-host.com/example-sitemap.xml — as long as the reference is correct in robots.txt, Googlebot will find it.
What are the implications for technical architecture?
This flexibility opens up possibilities for distributed architectures. Multilingual sites with distinct subdomains, headless platforms where content is served from multiple sources, complex CDN configurations — everything becomes simpler.
The only requirement remains that the file be accessible to Googlebot and explicitly declared. No magic, no automatic detection.
- The physical location of the sitemap does not affect its effectiveness
- Declaration in robots.txt or Search Console is the only discovery mechanism
- You can host the sitemap on a subdomain or distinct host
- This flexibility simplifies complex technical architectures
- The file must remain accessible without authentication or robots.txt blocking
SEO Expert opinion
Is this statement really surprising?
No, honestly. Any SEO who has already tested different configurations has probably observed this empirically. Google follows explicit instructions — it's consistent with its general crawling approach.
What's interesting is that Mueller formalizes this clearly. It puts an end to sterile debates about the "best" sitemap location and dogmatic recommendations that still appear in certain audits.
What nuances should be applied in practice?
Attention: not all search engines work the same way. Bing, Yandex, or Baidu may have their own constraints or preferences. Testing remains essential if you're targeting multiple engines.
Another point — technical accessibility. A sitemap hosted on an external CDN can introduce synchronization latencies or caching issues. If your file is updated every 10 minutes but the CDN invalidates its cache every hour, you have a freshness problem. [To be verified] depending on your technical stack.
In what cases does this flexibility cause problems?
On large sites with fragmented sitemaps (sitemap index plus multiple child sitemaps), hosting files across different domains can complicate tracking and maintenance. You multiply potential failure points.
If your dev team isn't rigorous about path and redirect management, you risk silently breaking your sitemap during a migration or refactoring. The "at the root" convention at least offers some predictability — that's not insignificant in organizations with high turnover.
Practical impact and recommendations
What should you do concretely with this information?
Nothing revolutionary. If your current sitemap is working and being properly crawled, don't change anything. Don't optimize what isn't broken.
On the other hand, if you have technical constraints that prevented you from placing the sitemap at the root (server access restrictions, proprietary CMS, microservices architecture), you now know you can work around the problem without SEO impact.
What errors should you avoid with this configuration?
Don't assume Google will "guess" where your sitemap is. Explicit declaration remains absolutely mandatory — either in robots.txt or via Search Console.
Another classic pitfall: moving the sitemap without updating robots.txt. Result: Google continues looking for the old file, gets a 404, and stops crawling your new URLs. Always verify consistency between your declaration and actual location.
Finally, if you host the sitemap on an external domain, ensure that domain is verified in Search Console. Otherwise, you risk security alerts or automatic blocking.
How can you verify that the configuration is working correctly?
- Test your sitemap's accessibility with a simple
curlorwgetfrom an external IP - Verify that the
Sitemap:directive in robots.txt points to the exact URL of the file - Check the Sitemaps report in Search Console: parsing errors, unindexed URLs, processing delays
- If you use a sitemap index, verify that all child sitemaps are accessible from their declared URLs
- Monitor server logs to confirm that Googlebot is actually crawling the sitemap at the expected frequency
- Test after any architecture change: migration, CDN change, refactoring
❓ Frequently Asked Questions
Puis-je héberger mon sitemap sur un CDN comme Cloudflare ou Amazon S3 ?
Faut-il déclarer le sitemap dans robots.txt ET dans Search Console ?
Si je déplace mon sitemap, dois-je mettre une redirection 301 depuis l'ancien emplacement ?
Un sitemap hébergé sur un sous-domaine peut-il indexer des URLs du domaine principal ?
Cette règle s'applique-t-elle aussi aux sitemaps vidéo, images ou actualités ?
🎥 From the same video 22
Other SEO insights extracted from this same Google Search Central video · published on 28/03/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.