Official statement
Other statements from this video 11 ▾
- □ Le fichier robots.txt empêche-t-il réellement l'indexation de vos pages ?
- □ Votre outil de test SEO est-il vraiment un crawler aux yeux de Google ?
- □ Googlebot suit-il vraiment les liens ou fonctionne-t-il autrement ?
- □ Le parser robots.txt open source de Google est-il vraiment utilisé en production ?
- □ Publier un site web équivaut-il juridiquement à autoriser Google à le crawler ?
- □ Comment Googlebot ajuste-t-il sa fréquence de crawl pour ne pas faire planter vos serveurs ?
- □ Peut-on indexer une page sans la crawler ?
- □ Pourquoi Google refuse-t-il des directives robots.txt trop granulaires ?
- □ Le robots.txt est-il vraiment suffisant pour contrôler le crawl de votre site ?
- □ Qui a vraiment créé le parser robots.txt de Google ?
- □ Pourquoi Google refuse-t-il catégoriquement de moderniser le format robots.txt ?
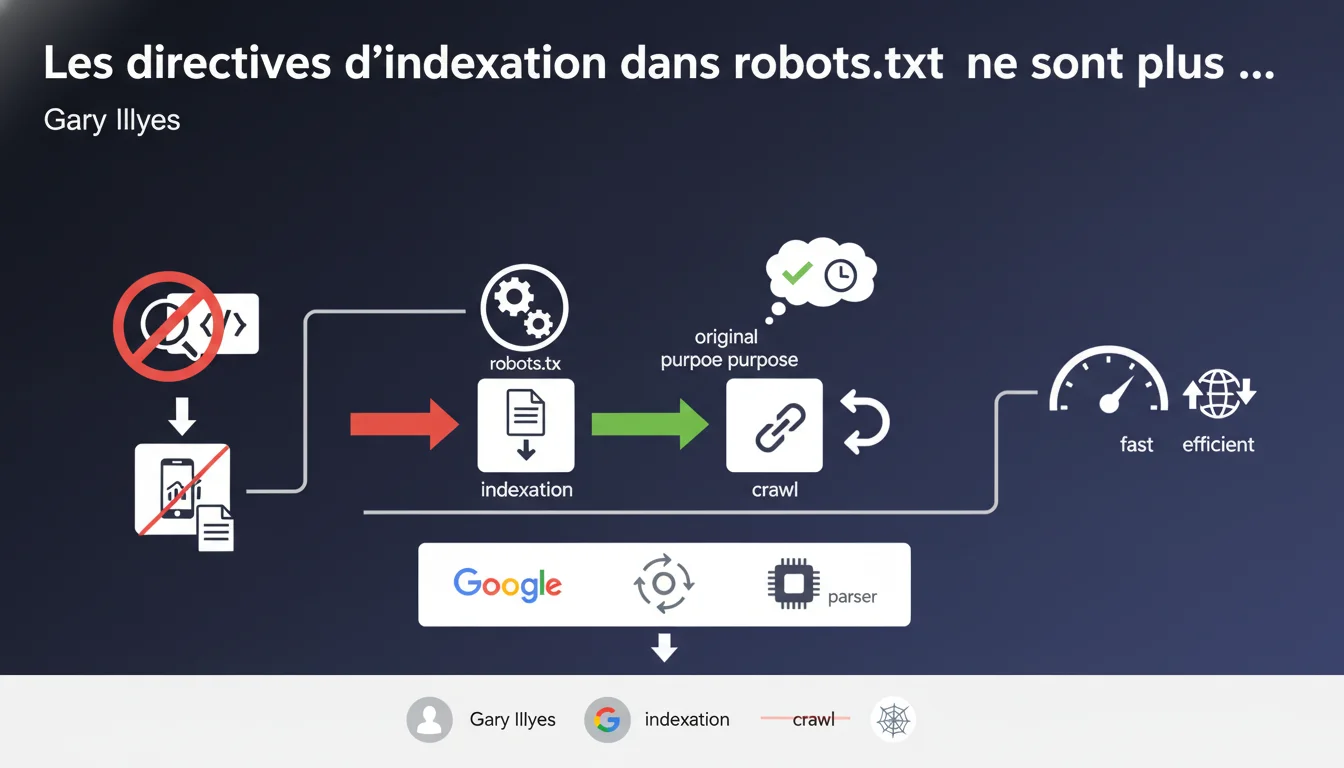
Google has removed support for non-standard indexing directives in robots.txt during the open sourcing of its parser. The robots.txt file must now only be used to control crawling, not indexing. Webmasters who were using these proprietary directives must transition to official methods.
What you need to understand
What does this removal of support really mean?
Historically, Google used non-standard directives in robots.txt, such as noindex and nofollow, to control indexing. These commands were never part of the official robots.txt protocol — which only defines User-agent, Disallow, Allow, and Sitemap.
During the open sourcing of the robots.txt parser, Google decided to clean up its implementation and remove these proprietary extensions. As a result, the robots.txt file returns to its original function, which is crawling control only.
What is the difference between crawling and indexing in this context?
Crawling refers to the bot's access to a page. Indexing is the inclusion of that page in the search index. Blocking crawling via Disallow prevents Googlebot from seeing the content, but doesn’t necessarily stop indexing if external links point to the page.
Directives like noindex in robots.txt allowed webmasters to say, "crawl this page, but do not index it." Convenient, but never official — and now obsolete at Google.
What are the official methods to control indexing?
- <meta name="robots" content="noindex"> tag in HTML
- HTTP header X-Robots-Tag: noindex for non-HTML files (PDFs, images, etc.)
- Combination of Allow + noindex: allow crawling in robots.txt, then block indexing via meta or X-Robots-Tag.
- Authentication or robots.txt Disallow to completely prevent access (note, there is a risk of partial indexing if external links exist).
SEO Expert opinion
Was this decision foreseeable?
Absolutely. Google has been announcing for years that indexing directives in robots.txt were not official and that standard methods should be used. The open sourcing of the parser simply forced the issue: it is impossible to maintain proprietary extensions in a public project.
What is surprising is the vague timing. Gary Illyes did not specify exactly when support was cut — and no clear communication was made beforehand to warn the affected webmasters. [To be verified]: was the change gradual or abrupt?
What is the real risk for sites that used these directives?
If a site relied on noindex in robots.txt to block indexing of certain pages, those pages may now appear in search results. Specifically: staging pages, admin areas, internal URL parameters, intentionally hidden duplicate content.
The real problem is that many webmasters did not even know they were using a non-standard method. Some CMS or SEO plugins generated these directives automatically for years.
Are other search engines affected?
Bing has also supported certain indexing directives in robots.txt in the past, but with variations. This change at Google does not necessarily mean that Bing, Yandex, or Baidu will immediately follow suit.
Let’s be honest: no one really optimizes for Baidu outside of China. But if your audience uses multiple search engines, check how each interprets your robots.txt. [To be verified]: the official documentation of each search engine remains the only reliable source.
Practical impact and recommendations
What should you do if your site used these directives?
First step: audit your current robots.txt. Look for lines containing noindex, nofollow, or any other non-standard directive. If you find any, they are now ignored by Google.
Next, identify the affected pages and decide on a strategy: either they need to remain non-indexed (add a noindex meta), or they can be indexed (simply clean up robots.txt).
How to correctly transition to official methods?
For each URL blocked from indexing via robots.txt, you have two main options. You can either allow crawling in robots.txt and add a <meta name="robots" content="noindex"> tag in the HTML, or use an X-Robots-Tag in the HTTP header for non-HTML files.
If the content should never be crawled or indexed, keep the Disallow in robots.txt. But be careful: Google can still index the URL even without content if external links point to it. In such cases, combine Disallow + server authentication for complete protection.
How to test that your changes are working?
- Test your robots.txt with the robots.txt testing tool in Google Search Console.
- Use the URL inspection tool to verify that pages with noindex meta tags are crawled but marked as non-indexable.
- Monitor the Google index with site:yourdomain.com queries to spot any unwanted pages.
- Set up Search Console alerts to be notified of indexing or coverage errors.
- Document every change in a SEO changelog to track the impact on your rankings.
This migration may seem technical, but it is crucial to avoid exposing sensitive content or polluting your index. If your site architecture heavily relies on robots.txt to manage indexing, a complete overhaul of your strategy may be necessary.
These optimizations often involve server configuration, CMS templates, and overall architecture. If you are not comfortable with these adjustments — or if your site generates thousands of dynamic URLs — reaching out to a specialized SEO agency can save you valuable time and help avoid costly mistakes.
❓ Frequently Asked Questions
Les directives Disallow et Allow dans robots.txt sont-elles toujours valides ?
Si j'utilisais noindex dans robots.txt, mes pages vont-elles être indexées immédiatement ?
Quelle est la différence entre bloquer le crawl et bloquer l'indexation ?
Est-ce que Bing et les autres moteurs ont fait le même changement ?
Peut-on encore combiner robots.txt et meta robots sur la même page ?
🎥 From the same video 11
Other SEO insights extracted from this same Google Search Central video · published on 21/12/2021
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.