Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Le fichier robots.txt empêche-t-il réellement l'indexation de vos pages ?
- □ Votre outil de test SEO est-il vraiment un crawler aux yeux de Google ?
- □ Googlebot suit-il vraiment les liens ou fonctionne-t-il autrement ?
- □ Le parser robots.txt open source de Google est-il vraiment utilisé en production ?
- □ Publier un site web équivaut-il juridiquement à autoriser Google à le crawler ?
- □ Comment Googlebot ajuste-t-il sa fréquence de crawl pour ne pas faire planter vos serveurs ?
- □ Peut-on indexer une page sans la crawler ?
- □ Pourquoi Google refuse-t-il des directives robots.txt trop granulaires ?
- □ Le robots.txt est-il vraiment suffisant pour contrôler le crawl de votre site ?
- □ Qui a vraiment créé le parser robots.txt de Google ?
- □ Pourquoi Google refuse-t-il catégoriquement de moderniser le format robots.txt ?
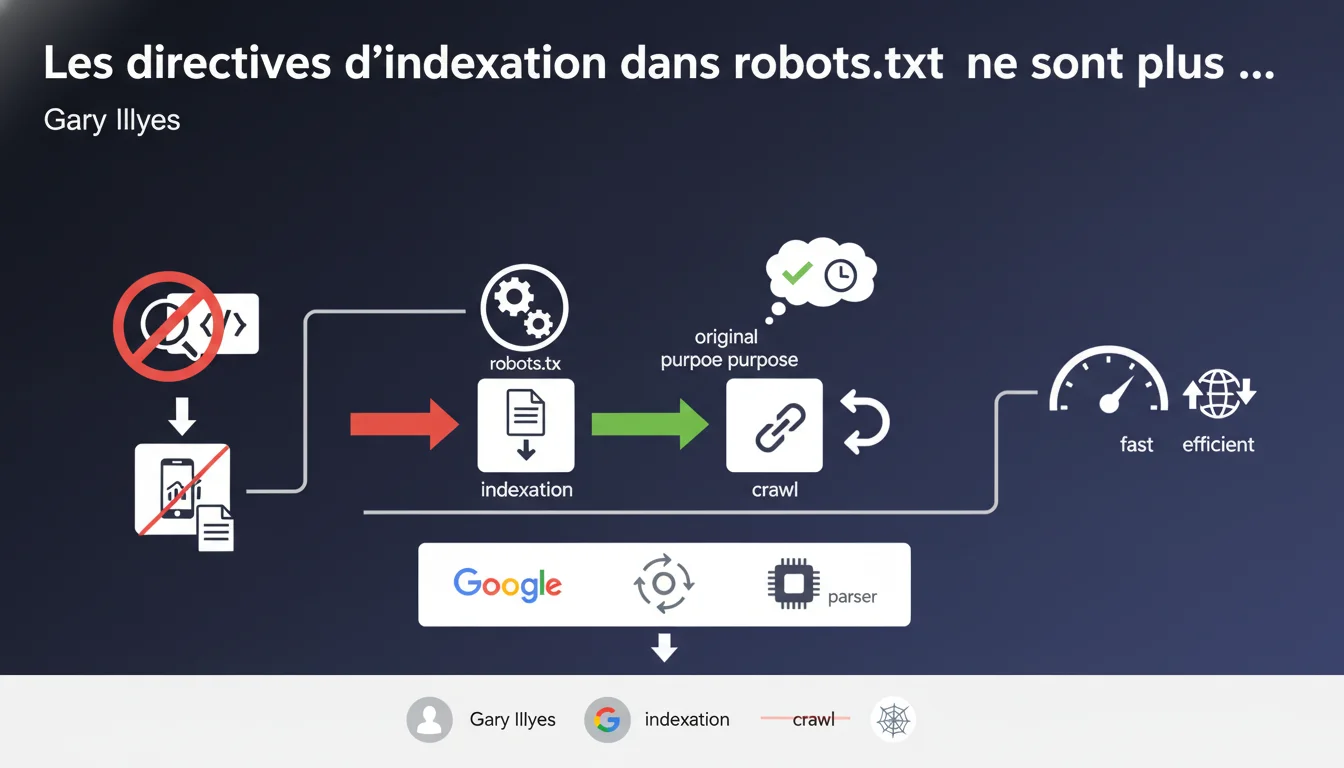
Google a supprimé le support des directives d'indexation non-standard dans robots.txt lors de l'open sourcing de son parser. Le fichier robots.txt doit désormais servir uniquement à contrôler le crawl, pas l'indexation. Les webmasters qui utilisaient ces directives propriétaires doivent migrer vers des méthodes officielles.
Ce qu'il faut comprendre
Que signifie concrètement cette suppression de support ?
Google utilisait historiquement des directives non-standard dans robots.txt, notamment noindex et nofollow, pour contrôler l'indexation. Ces commandes n'ont jamais fait partie du protocole officiel robots.txt — qui ne définit que User-agent, Disallow, Allow et Sitemap.
Lors de l'open sourcing du parser robots.txt, Google a décidé de nettoyer son implémentation et de supprimer ces extensions propriétaires. Résultat : le fichier robots.txt revient à sa fonction d'origine, le contrôle du crawling uniquement.
Quelle était la différence entre crawling et indexation dans ce contexte ?
Le crawl, c'est l'accès du bot à une page. L'indexation, c'est l'inclusion de cette page dans l'index de recherche. Bloquer le crawl via Disallow empêche Googlebot de voir le contenu, mais n'empêche pas forcément l'indexation si des liens externes pointent vers la page.
Les directives comme noindex dans robots.txt permettaient de dire « crawle cette page, mais ne l'indexe pas ». Pratique, mais jamais officiel — et désormais obsolète chez Google.
Quelles sont les méthodes officielles pour contrôler l'indexation ?
- Balise <meta name="robots" content="noindex"> dans le HTML
- En-tête HTTP X-Robots-Tag: noindex pour les fichiers non-HTML (PDF, images, etc.)
- Combinaison Allow + noindex : autoriser le crawl dans robots.txt, puis bloquer l'indexation via meta ou X-Robots-Tag
- Authentification ou robots.txt Disallow pour empêcher totalement l'accès (attention, risque d'indexation partielle si liens externes)
Avis d'un expert SEO
Cette décision était-elle prévisible ?
Totalement. Google annonçait depuis des années que les directives d'indexation dans robots.txt n'étaient pas officielles et qu'il fallait utiliser les méthodes standard. L'open sourcing du parser a simplement forcé la main : impossible de maintenir des extensions propriétaires dans un projet public.
Ce qui surprend, c'est le timing flou. Gary Illyes ne précise pas quand exactement le support a été coupé — et aucune communication claire n'a été faite en amont pour prévenir les webmasters concernés. [À vérifier] : le changement était-il progressif ou brutal ?
Quel risque réel pour les sites qui utilisaient ces directives ?
Si un site comptait sur noindex dans robots.txt pour bloquer l'indexation de certaines pages, ces pages peuvent désormais apparaître dans les résultats. Concrètement : pages de staging, zones admin, paramètres d'URL internes, contenus dupliqués intentionnellement masqués.
Le vrai problème, c'est que beaucoup de webmasters ne savaient même pas qu'ils utilisaient une méthode non-standard. Certains CMS ou plugins SEO ont généré ces directives automatiquement pendant des années.
Les autres moteurs sont-ils concernés ?
Bing a également supporté certaines directives d'indexation dans robots.txt par le passé, mais avec des variations. Ce changement chez Google ne signifie pas nécessairement que Bing, Yandex ou Baidu suivront immédiatement.
Soyons honnêtes : personne n'optimise vraiment pour Baidu en dehors de la Chine. Mais si votre audience est multi-moteurs, vérifiez comment chacun interprète votre robots.txt. [À vérifier] : la documentation officielle de chaque moteur reste la seule source fiable.
Impact pratique et recommandations
Que faire si votre site utilisait ces directives ?
Première étape : auditer votre robots.txt actuel. Cherchez les lignes contenant noindex, nofollow ou toute autre directive non-standard. Si vous en trouvez, elles sont désormais ignorées par Google.
Ensuite, identifiez les pages concernées et décidez d'une stratégie : soit elles doivent rester non-indexées (ajoutez un meta noindex), soit elles peuvent être indexées (nettoyez simplement robots.txt).
Comment migrer correctement vers les méthodes officielles ?
Pour chaque URL bloquée en indexation via robots.txt, vous avez deux options principales. Soit vous autorisez le crawl dans robots.txt et ajoutez une balise <meta name="robots" content="noindex"> dans le HTML, soit vous utilisez un X-Robots-Tag dans l'en-tête HTTP pour les fichiers non-HTML.
Si le contenu ne doit vraiment jamais être crawlé ni indexé, gardez le Disallow dans robots.txt. Mais attention : Google peut quand même indexer l'URL sans contenu si des liens externes pointent vers elle. Dans ce cas, combinez Disallow + authentification serveur pour une protection totale.
Comment vérifier que vos modifications fonctionnent ?
- Testez votre robots.txt avec l'outil de test robots.txt dans Google Search Console
- Utilisez l'outil d'inspection d'URL pour vérifier que les pages avec meta noindex sont bien crawlées mais marquées comme non-indexables
- Surveillez l'index Google avec des requêtes site:votredomaine.com pour détecter l'apparition de pages non désirées
- Configurez des alertes Search Console pour être notifié d'erreurs d'indexation ou de couverture
- Documentez chaque changement dans un changelog SEO pour suivre l'impact sur vos classements
Cette migration peut sembler technique, mais elle est cruciale pour éviter l'exposition de contenus sensibles ou la pollution de votre index. Si votre architecture de site repose lourdement sur robots.txt pour gérer l'indexation, une refonte complète de votre stratégie peut être nécessaire.
Ces optimisations touchent souvent à la configuration serveur, aux templates de CMS et à l'architecture globale. Si vous n'êtes pas à l'aise avec ces manipulations — ou si votre site génère des milliers d'URLs dynamiques — faire appel à une agence SEO spécialisée peut vous faire gagner un temps précieux et éviter des erreurs coûteuses.
❓ Questions frequentes
Les directives Disallow et Allow dans robots.txt sont-elles toujours valides ?
Si j'utilisais noindex dans robots.txt, mes pages vont-elles être indexées immédiatement ?
Quelle est la différence entre bloquer le crawl et bloquer l'indexation ?
Est-ce que Bing et les autres moteurs ont fait le même changement ?
Peut-on encore combiner robots.txt et meta robots sur la même page ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 21/12/2021
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.