Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Le fichier robots.txt empêche-t-il réellement l'indexation de vos pages ?
- □ Votre outil de test SEO est-il vraiment un crawler aux yeux de Google ?
- □ Googlebot suit-il vraiment les liens ou fonctionne-t-il autrement ?
- □ Le parser robots.txt open source de Google est-il vraiment utilisé en production ?
- □ Pourquoi Google abandonne-t-il les directives d'indexation dans robots.txt ?
- □ Comment Googlebot ajuste-t-il sa fréquence de crawl pour ne pas faire planter vos serveurs ?
- □ Peut-on indexer une page sans la crawler ?
- □ Pourquoi Google refuse-t-il des directives robots.txt trop granulaires ?
- □ Le robots.txt est-il vraiment suffisant pour contrôler le crawl de votre site ?
- □ Qui a vraiment créé le parser robots.txt de Google ?
- □ Pourquoi Google refuse-t-il catégoriquement de moderniser le format robots.txt ?
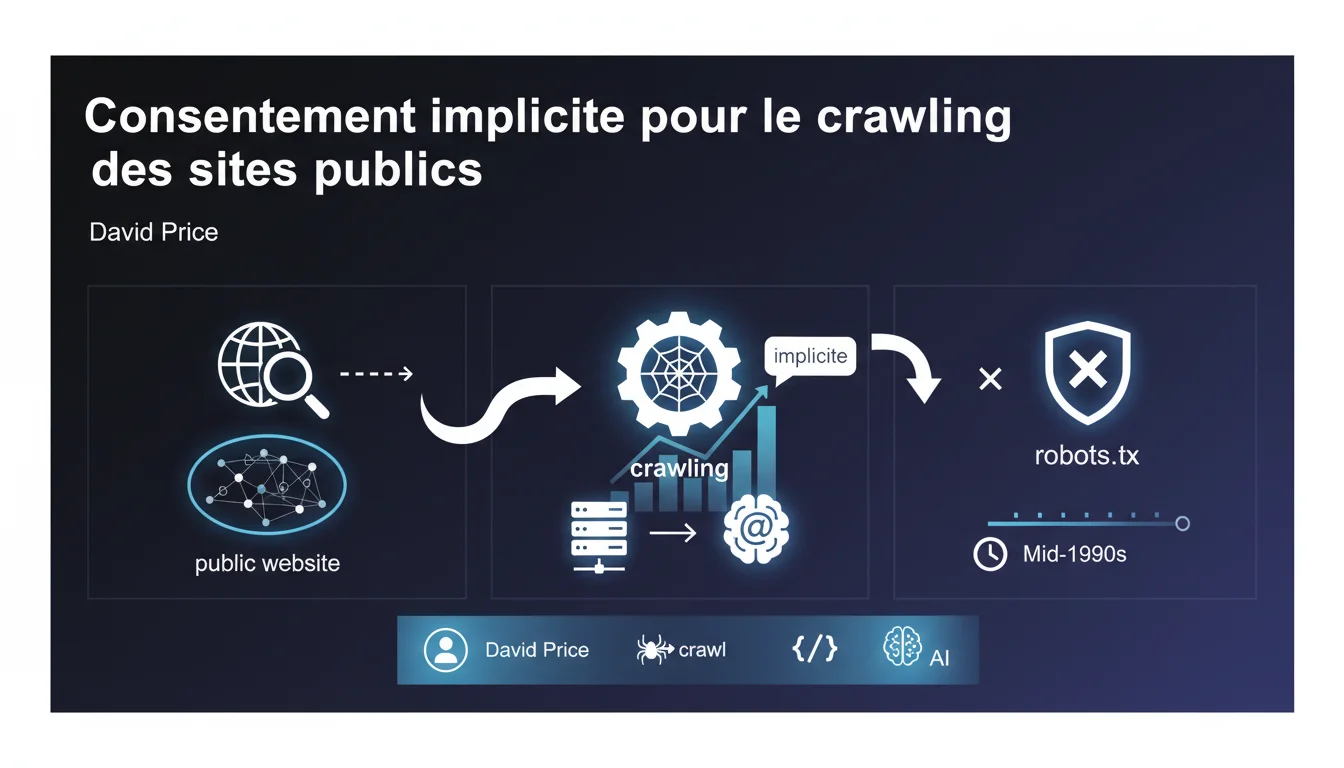
Google affirme qu'un site public implique légalement un consentement implicite au crawl, sauf directive contraire via robots.txt. Cette position juridique, défendue depuis les années 90, sert à justifier l'exploration massive de contenus sans autorisation explicite préalable. Pour les praticiens SEO, ça signifie que le robots.txt reste le seul garde-fou technique reconnu par Google.
Ce qu'il faut comprendre
Qu'est-ce que le consentement implicite dont parle Google ?
Google défend l'idée qu'en publiant du contenu accessible sur Internet, vous autorisez tacitement les robots d'exploration à le parcourir. Pas besoin d'accord formel — la mise en ligne suffirait juridiquement.
Cette doctrine du consentement implicite repose sur une logique simple : si vous ne voulez pas être crawlé, bloquez l'accès. C'est au propriétaire du site d'exprimer son refus, pas au moteur de demander permission.
Quel rôle joue robots.txt dans cette logique ?
Le fichier robots.txt devient alors l'outil officiel pour retirer ce consentement implicite. Google le considère comme une directive légale suffisante pour interdire l'exploration de certaines sections ou de l'ensemble d'un site.
Concrètement, sans robots.txt bloquant, Google estime avoir carte blanche. C'est une interprétation qui facilite évidemment son indexation massive, mais qui pose des questions sur les contenus semi-publics ou les sites mal configurés.
Cette position juridique est-elle universellement acceptée ?
Non. Le cadre juridique varie énormément selon les pays. Ce que Google présente comme acquis depuis les années 90 fait encore débat, notamment en Europe où le RGPD complexifie la notion de consentement.
Certains tribunaux ont validé cette approche, d'autres l'ont contestée. Google s'appuie sur une jurisprudence américaine favorable, mais ça ne signifie pas que tous les territoires adhèrent à cette vision.
- Consentement implicite : publier = autoriser le crawl selon Google
- Robots.txt : seul moyen reconnu pour retirer ce consentement
- Cadre juridique variable : cette doctrine n'est pas universelle
- Années 90 : Google ancre cette pratique dans une ancienneté pour légitimer son approche
Avis d'un expert SEO
Cette déclaration reflète-t-elle vraiment un consensus juridique ?
Soyons honnêtes : Google défend ici sa propre position, pas une vérité juridique absolue. La notion de consentement implicite facilite son business model, mais elle est loin de faire l'unanimité devant les tribunaux européens.
Le RGPD, par exemple, exige un consentement explicite pour certaines collectes de données. Affirmer qu'un site public = consentement universel au crawl est une simplification qui arrange Google mais qui pourrait être contestée cas par cas. [À vérifier] selon votre juridiction et le type de contenu publié.
Robots.txt suffit-il vraiment à protéger un contenu ?
En théorie, oui. En pratique, c'est plus nuancé. Google respecte généralement robots.txt pour l'exploration, mais ça n'empêche pas l'indexation d'URL bloquées si elles sont mentionnées ailleurs avec un lien.
Et puis, robots.txt est une directive honorifique — rien n'oblige techniquement un bot tiers à la respecter. Google s'y conforme, mais d'autres crawlers, moins scrupuleux, s'en fichent complètement. Compter uniquement sur ce fichier, c'est ignorer une partie du risque.
Quelles zones grises subsistent dans cette approche ?
Les espaces semi-publics posent problème : forums avec inscription, contenus derrière un soft paywall, sections clients accessibles sans authentification stricte. Où s'arrête le consentement implicite ?
Google ne précise pas. La déclaration reste floue sur ces cas limites. Un contenu accessible via URL directe mais non destiné au grand public — est-ce vraiment un consentement à l'indexation mondiale ? [À vérifier] au cas par cas avec un juriste si vous gérez des contenus sensibles.
Impact pratique et recommandations
Que faut-il vérifier immédiatement sur votre site ?
Commencez par auditer votre fichier robots.txt. Assurez-vous qu'il bloque effectivement les sections sensibles et qu'il n'empêche pas par erreur l'exploration de pages stratégiques.
Vérifiez ensuite vos directives meta robots : noindex, nofollow, canonical. C'est la couche suivante de contrôle une fois le crawl autorisé. Beaucoup de sites laissent passer des pages inutiles simplement parce qu'elles sont techniquement accessibles.
Quelles erreurs éviter pour rester maître de votre indexation ?
Ne comptez pas uniquement sur robots.txt pour sécuriser du contenu vraiment confidentiel. Si une info ne doit pas être publique, mettez une authentification réelle, pas juste une absence de lien interne.
Évitez aussi les configurations contradictoires : robots.txt qui bloque + sitemap XML qui soumet les mêmes URL. Google indexe parfois ces pages bloquées si elles sont référencées ailleurs, créant de la confusion.
Comment s'assurer que votre stratégie SEO reste alignée avec cette logique ?
Profitez du fait que le crawl soit autorisé par défaut pour optimiser l'accessibilité des contenus stratégiques : architecture claire, maillage interne, sitemap structuré. Vous avez le crawl — autant l'exploiter à fond.
Pour les pages à faible valeur ou duplicatas, utilisez noindex ou canonical plutôt que robots.txt. Ça évite de bloquer le crawl inutilement tout en gardant la main sur ce qui apparaît dans les résultats.
- Auditer robots.txt et corriger blocages accidentels ou manques
- Vérifier les directives meta robots sur pages sensibles
- Mettre en place authentification réelle pour contenus non publics
- Éviter conflits entre robots.txt et sitemap XML
- Utiliser noindex/canonical pour contenus à faible valeur plutôt que blocage crawl
- Contrôler l'indexation effective via Google Search Console
❓ Questions frequentes
Si je ne veux pas être crawlé par Google, que dois-je faire concrètement ?
Google peut-il indexer une page bloquée par robots.txt ?
Le consentement implicite s'applique-t-il à tous les moteurs de recherche ?
Un contenu derrière inscription légère est-il considéré comme public par Google ?
Puis-je poursuivre Google si je n'ai pas bloqué le crawl mais que je ne voulais pas être indexé ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 21/12/2021
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.