Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Votre outil de test SEO est-il vraiment un crawler aux yeux de Google ?
- □ Googlebot suit-il vraiment les liens ou fonctionne-t-il autrement ?
- □ Le parser robots.txt open source de Google est-il vraiment utilisé en production ?
- □ Pourquoi Google abandonne-t-il les directives d'indexation dans robots.txt ?
- □ Publier un site web équivaut-il juridiquement à autoriser Google à le crawler ?
- □ Comment Googlebot ajuste-t-il sa fréquence de crawl pour ne pas faire planter vos serveurs ?
- □ Peut-on indexer une page sans la crawler ?
- □ Pourquoi Google refuse-t-il des directives robots.txt trop granulaires ?
- □ Le robots.txt est-il vraiment suffisant pour contrôler le crawl de votre site ?
- □ Qui a vraiment créé le parser robots.txt de Google ?
- □ Pourquoi Google refuse-t-il catégoriquement de moderniser le format robots.txt ?
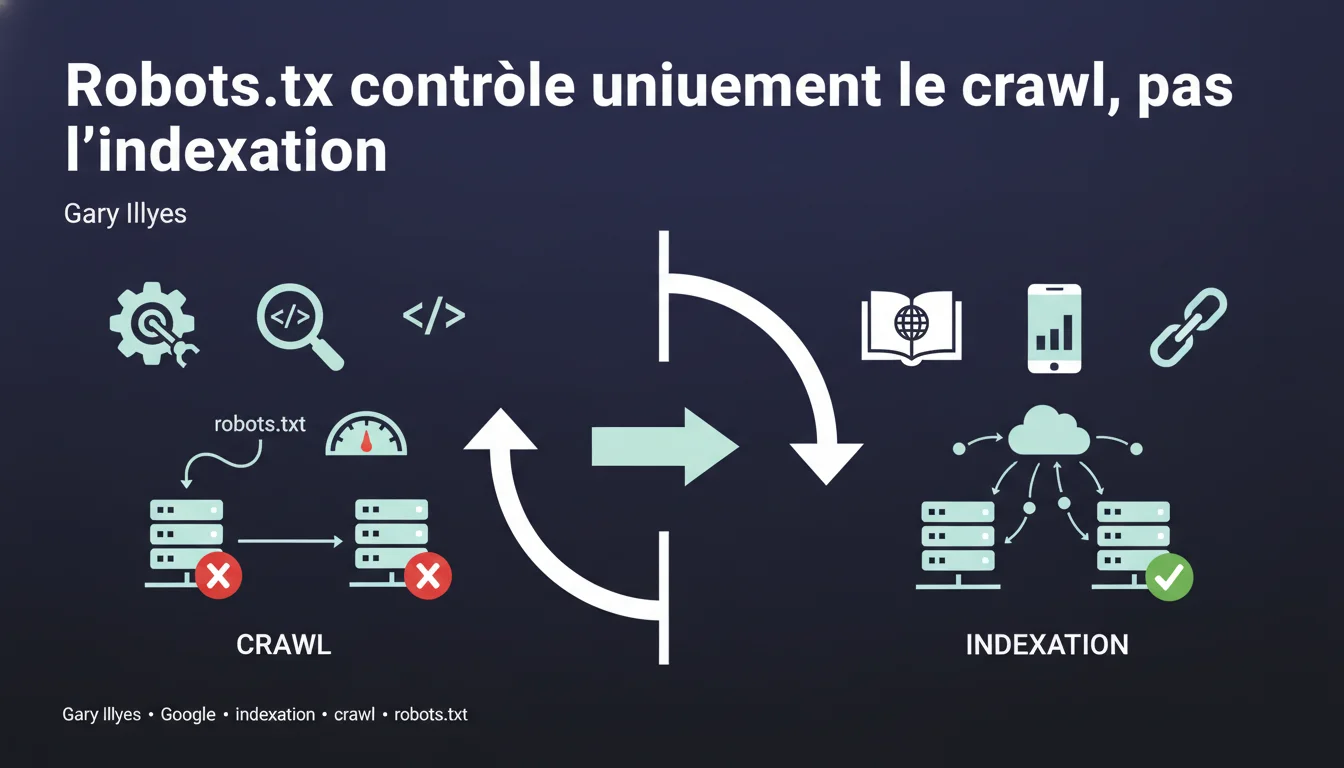
Google peut indexer des URLs bloquées par robots.txt sans en crawler le contenu, en se basant uniquement sur les liens externes pointant vers ces pages. Le fichier robots.txt contrôle l'exploration, pas l'indexation — une distinction fondamentale que beaucoup de professionnels SEO confondent encore.
Ce qu'il faut comprendre
Quelle est la différence entre crawl et indexation ?
Le crawl (exploration) consiste pour Googlebot à télécharger le contenu d'une page pour l'analyser. L'indexation, c'est la décision de stocker cette URL dans l'index de Google et de la rendre éligible à l'affichage dans les résultats de recherche.
Ces deux processus sont distincts. Google peut décider d'indexer une URL sans jamais en avoir crawlé le contenu — il se base alors sur les signaux externes comme les ancres de liens pointant vers cette page.
Comment Google indexe-t-il une page sans la crawler ?
Lorsqu'une URL est bloquée par robots.txt, Googlebot respecte cette directive et n'accède pas au contenu. Mais si des backlinks pointent vers cette URL, Google connaît son existence.
Il peut alors l'indexer en se basant uniquement sur les informations disponibles : l'URL elle-même, les ancres de liens des pages référentes, et le contexte dans lequel ces liens apparaissent. Résultat : une URL indexée avec une description générique du type "Aucune information disponible".
Pourquoi cette confusion persiste-t-elle chez les SEO ?
Historiquement, bloquer une page en robots.txt suffisait souvent à empêcher son indexation — mais c'était un effet de bord, pas une garantie. La documentation Google a longtemps été floue sur ce point.
Aujourd'hui, la position officielle est claire : robots.txt = contrôle du crawl. Pour empêcher l'indexation, il faut utiliser une balise noindex ou une réponse HTTP 401/410.
- Robots.txt bloque le crawl, pas l'indexation
- Google indexe des URLs bloquées si des backlinks existent
- Pour bloquer l'indexation, utilisez noindex ou une réponse HTTP appropriée
- L'URL et les ancres de liens suffisent à Google pour indexer une page
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, totalement. On observe régulièrement des URLs bloquées en robots.txt qui apparaissent dans l'index Google avec la mention "Une description de ce résultat n'est pas disponible en raison du fichier robots.txt de ce site".
C'est particulièrement fréquent sur des sections sensibles (admin, staging, backoffice) que certains webmasters croient protégées par robots.txt. Ils découvrent souvent avec stupeur que ces URLs sont indexables.
Quelles nuances faut-il apporter à cette règle ?
La déclaration de Gary Illyes est factuelle mais incomplète sur un point : elle ne précise pas le seuil de popularité nécessaire. Toutes les URLs bloquées en robots.txt ne sont pas automatiquement indexées — il faut un volume minimal de backlinks.
[À vérifier] Google ne communique jamais de seuil chiffré. D'après les observations, une URL avec 3-5 backlinks depuis des sites indexés a déjà une probabilité significative d'indexation. Mais c'est une estimation empirique, pas une règle officielle.
Autre nuance : le délai. L'indexation d'une URL bloquée en robots.txt peut prendre plusieurs semaines, voire mois, selon la fréquence de découverte des backlinks par Googlebot.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si une URL n'a aucun backlink et n'apparaît nulle part ailleurs sur le web, elle ne sera probablement jamais indexée même si elle est bloquée en robots.txt. Google ne la connaît tout simplement pas.
Impact pratique et recommandations
Que faut-il faire concrètement pour empêcher l'indexation ?
Si vous voulez bloquer l'indexation d'une page, trois méthodes fonctionnent réellement : la balise meta noindex, une réponse HTTP 401 (authentification requise) ou 410 (gone).
La balise noindex nécessite que Google puisse crawler la page — donc elle doit être accessible en robots.txt. C'est le paradoxe : pour dire à Google de ne pas indexer, il faut d'abord le laisser lire votre directive.
Pour des contenus sensibles (admin, staging), privilégiez une authentification HTTP ou un blocage par IP au niveau serveur. Pas de robots.txt, pas de noindex — juste un accès impossible.
Quelles erreurs éviter absolument ?
Erreur n°1 : bloquer en robots.txt des pages que vous voulez désindexer. Résultat : Google ne peut plus crawler la balise noindex, donc la page reste dans l'index indéfiniment.
Erreur n°2 : croire que robots.txt protège des contenus confidentiels. N'importe qui peut lire votre fichier robots.txt — c'est une feuille de route pour les concurrents et les scrapers.
Erreur n°3 : bloquer des ressources CSS/JS critiques. Google a explicitement dit qu'il peut ignorer ces directives robots.txt pour évaluer le rendu de la page.
Comment auditer votre configuration actuelle ?
Faites une recherche site:votredomaine.com dans Google et repérez les URLs avec la mention "robots.txt". Ce sont des pages bloquées au crawl mais indexées — probablement pas l'effet recherché.
Dans la Search Console, vérifiez les pages exclues. Les URLs marquées "Bloquées par robots.txt" ne devraient pas apparaître dans l'index — mais ça arrive. Cross-check avec votre fichier robots.txt.
- Utilisez noindex pour bloquer l'indexation, pas robots.txt
- Autorisez le crawl des pages avec noindex (paradoxal mais nécessaire)
- Protégez les contenus sensibles par authentification HTTP, pas robots.txt
- N'ajoutez jamais d'URLs bloquées en robots.txt dans votre sitemap XML
- Auditez régulièrement les URLs indexées malgré robots.txt (site: + "robots.txt")
- Ne bloquez pas les ressources CSS/JS critiques pour le rendu
❓ Questions frequentes
Peut-on utiliser robots.txt ET noindex sur la même page ?
Combien de temps faut-il pour désindexer une page bloquée en robots.txt ?
Google indexe-t-il les URLs bloquées en robots.txt même sans backlinks ?
Les autres moteurs de recherche respectent-ils robots.txt de la même manière ?
Bloquer le crawl de Googlebot réduit-il le crawl budget gaspillé ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 21/12/2021
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.