Declaration officielle
Sur Bluesky, Lidia Infante a demandé à John Mueller si ce fichier était une manière pour Google d'approuver le fichier LLMs.txt ou s’il s’agissait d’un troll en bonne et due forme. Réponse très éclairante de l’intéressé : « hmmn :-/ ».
Ce qu'il faut comprendre
Le fichier LLMs.txt est un nouveau standard proposé par la communauté tech pour permettre aux webmasters de donner des instructions spécifiques aux modèles de langage (LLMs) qui crawlent leurs sites. Sur le modèle du robots.txt qui s'adresse aux moteurs de recherche, ce fichier vise à encadrer l'utilisation du contenu par les IA génératives.
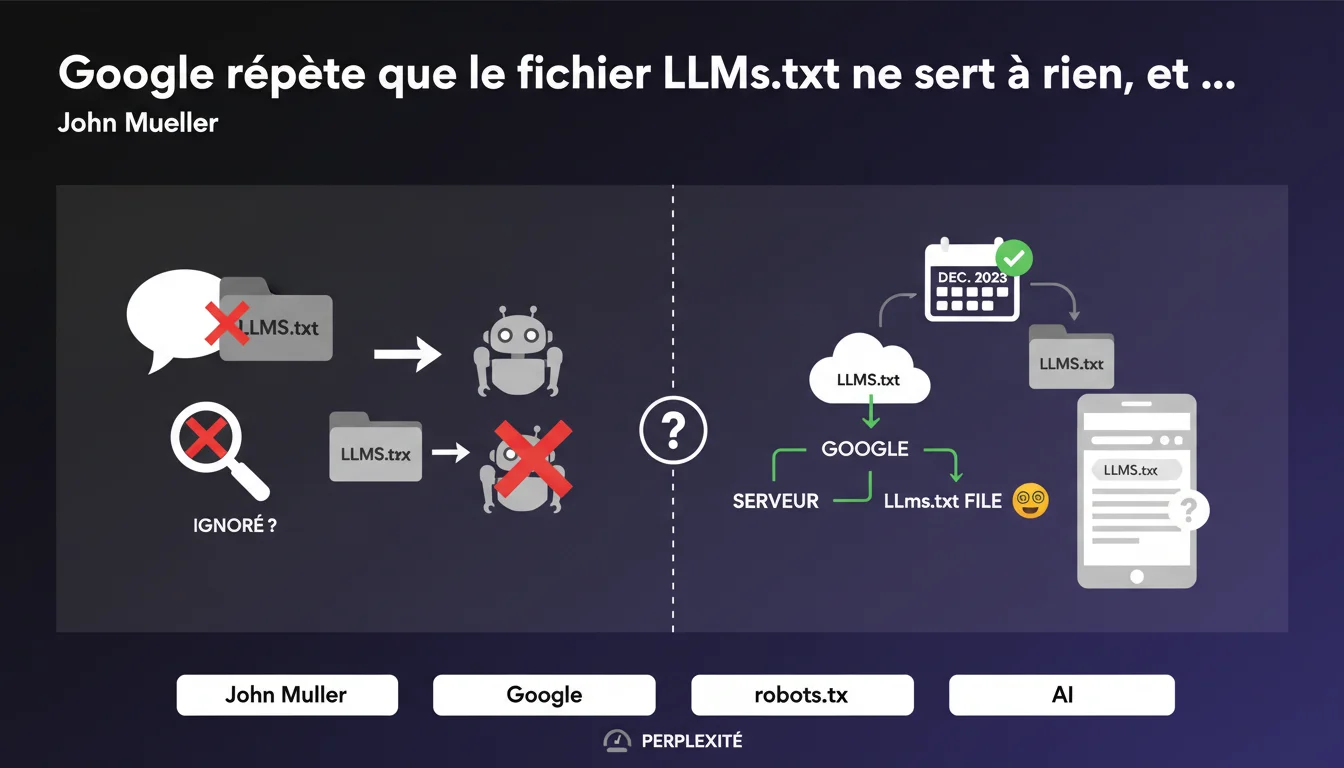
La situation actuelle est particulièrement contradictoire : d'un côté, les représentants officiels de Google affirment publiquement que ce fichier est inutile et ignoré par leurs systèmes. De l'autre, Google a lui-même déployé un fichier LLMs.txt sur ses propres domaines début décembre, créant une dissonance entre le discours officiel et les actions concrètes de l'entreprise.
Cette contradiction révèle probablement un débat interne chez Google sur la manière de gérer l'accès des LLMs au contenu web. Les équipes techniques semblent agir différemment des communications officielles, suggérant que la position de Google sur ce sujet n'est pas encore totalement stabilisée.
- Google affirme officiellement que le fichier LLMs.txt est ignoré par ses systèmes
- Google a pourtant déployé ce même fichier sur ses propres sites web
- La réponse évasive de John Mueller ("hmmn :-/") révèle un malaise sur le sujet
- Cette incohérence suggère une position non stabilisée en interne
Avis d'un expert SEO
En tant qu'expert SEO, cette situation illustre parfaitement le décalage fréquent entre les communications officielles et la réalité technique chez les grands acteurs du web. Lorsqu'une entreprise comme Google déploie une technologie sur ses propres sites tout en affirmant publiquement qu'elle est inutile, cela révèle généralement l'une de ces trois situations : soit un test en cours, soit une préparation anticipée d'un futur standard, soit une divergence entre différentes équipes.
Dans ce cas précis, il est probable que Google se prépare à un écosystème où les fichiers LLMs.txt deviendront pertinents, même si ce n'est pas encore le cas aujourd'hui. L'entreprise adopte peut-être une posture prudente publiquement pour ne pas créer de fausses attentes, tout en se positionnant techniquement pour l'avenir. La réponse embarrassée de John Mueller suggère qu'il n'a pas lui-même de réponse claire à donner sur cette contradiction.
Impact pratique et recommandations
- À faire maintenant : Documenter l'existence du fichier LLMs.txt et comprendre sa syntaxe pour être prêt à l'implémenter rapidement si nécessaire
- À surveiller : L'adoption du fichier LLMs.txt par d'autres acteurs majeurs (Microsoft, Meta, OpenAI) et l'évolution des communications officielles de Google sur le sujet
- À éviter : Investir du temps significatif dans la création d'un fichier LLMs.txt complexe tant que son utilité n'est pas confirmée par des preuves tangibles
- Stratégie recommandée : Pour les sites à forte valeur ajoutée sur le contenu (médias, éditeurs, bases de connaissances), créer un fichier LLMs.txt basique peut être une démarche de précaution raisonnable sans coût majeur
- Alternative immédiate : Concentrez-vous sur les directives déjà reconnues (robots.txt, meta robots, X-Robots-Tag) qui ont un impact prouvé sur le crawl et l'indexation
- Veille technique : Mettre en place une alerte pour suivre les annonces officielles sur la reconnaissance des fichiers LLMs.txt par les principaux acteurs de l'IA
💬 Commentaires (0)
Soyez le premier à commenter.