Official statement
Other statements from this video 11 ▾
- □ Le fichier robots.txt empêche-t-il réellement l'indexation de vos pages ?
- □ Googlebot suit-il vraiment les liens ou fonctionne-t-il autrement ?
- □ Le parser robots.txt open source de Google est-il vraiment utilisé en production ?
- □ Pourquoi Google abandonne-t-il les directives d'indexation dans robots.txt ?
- □ Publier un site web équivaut-il juridiquement à autoriser Google à le crawler ?
- □ Comment Googlebot ajuste-t-il sa fréquence de crawl pour ne pas faire planter vos serveurs ?
- □ Peut-on indexer une page sans la crawler ?
- □ Pourquoi Google refuse-t-il des directives robots.txt trop granulaires ?
- □ Le robots.txt est-il vraiment suffisant pour contrôler le crawl de votre site ?
- □ Qui a vraiment créé le parser robots.txt de Google ?
- □ Pourquoi Google refuse-t-il catégoriquement de moderniser le format robots.txt ?
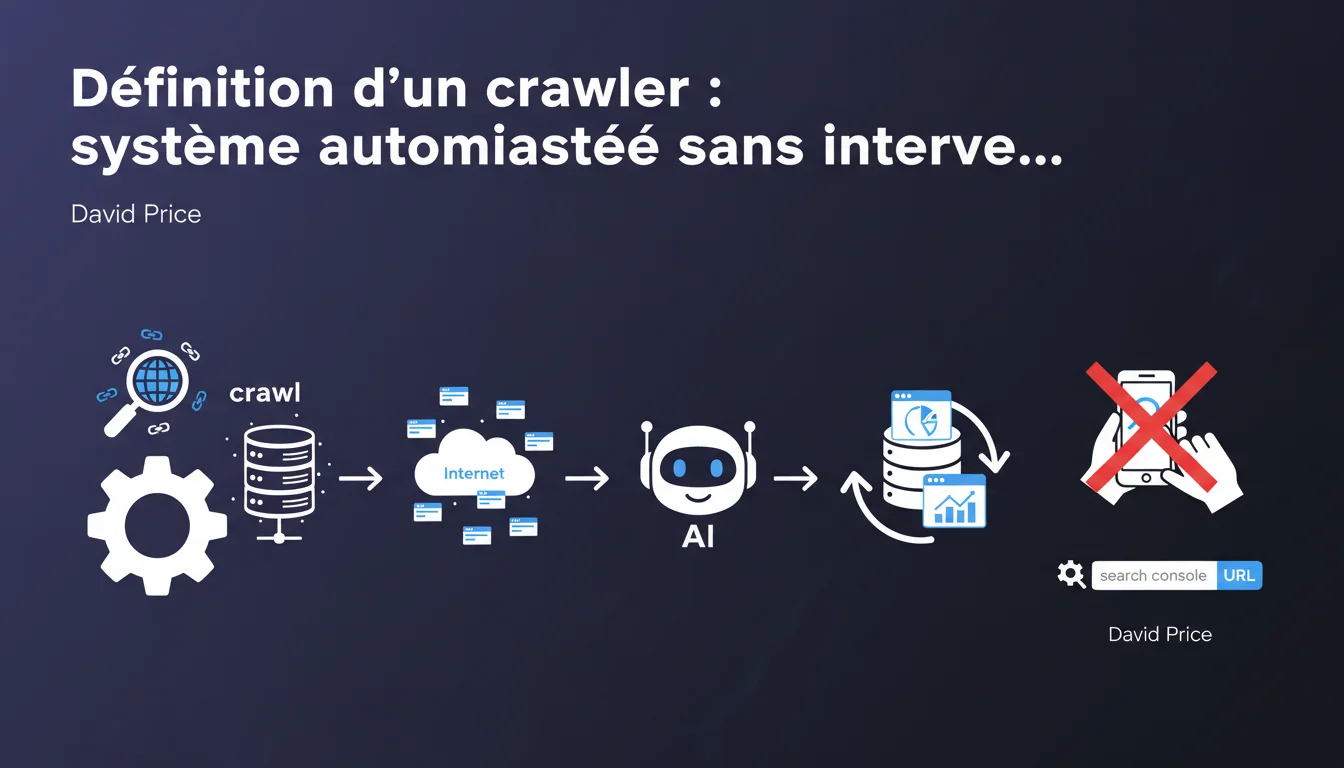
Google defines a crawler as a fully automated system that accesses pages without human intervention. Tools where a user manually triggers an action — like the URL inspector in Search Console — are not considered traditional crawlers. This technical distinction has concrete implications for how Google handles requests from these different systems.
What you need to understand
What is the true definition of a crawler according to Google? <\/h3>
Google makes a clear distinction<\/strong>: a true crawler operates in a totally automated<\/strong> manner, without the need for human intervention for each request. Googlebot, for example, crawls the web by following links, adhering to its own crawl schedule, without any Google employee pressing a button for each URL.<\/p> In contrast, a tool like the URL inspector in Search Console<\/strong> requires a user to manually enter an address and trigger a check. It is an inspection tool, not a crawler in the strict sense. This nuance may seem purely semantic — but it is not.<\/p> Because it influences how Google handles your requests and prioritizes its resources<\/strong>. An automated crawler like Googlebot follows a crawl budget logic, optimizing its visits according to the perceived freshness of content, site quality, and server response speed.<\/p> A manual tool like the URL inspector, on the other hand, generates a request on demand<\/strong>, immediate, which does not necessarily reflect the real state of regular crawling. It is a snapshot, not the normal behavior of Googlebot on your site.<\/p> All systems where the user manually triggers an action fall outside the realm of traditional crawlers. The URL inspector in Search Console is a prime example, but other SEO testing tools that operate on manual request are in the same category.<\/p> Specifically, if you have to click a button<\/strong> to get an URL analysis, you are not using a crawler in Google's sense. True crawlers — Googlebot, Bingbot, third-party site spiders like Ahrefs or SEMrush — run continuously, without human intervention for each page.<\/p>Why is this technical distinction important for SEO? <\/h3>
Which tools fall under this definition? <\/h3>
SEO Expert opinion
Does this clarification really change anything on the ground? <\/h3>
Honestly? It depends on how you use the tools. If you use the URL inspector as an absolute reference to diagnose an indexing issue, you might miss out on the true behavior<\/strong> of Googlebot. The inspector forces an immediate visit — it does not adhere to the crawl budget or the priorities that Googlebot applies under real conditions.<\/p> I have seen cases where the URL inspector indicated that a page was indexable without issues, whereas in the daily crawl, Googlebot simply did not visit it due to an insufficient crawl budget<\/strong> or a faulty link architecture. So the distinction is not just a matter of vocabulary — it represents two different behaviors.<\/p> Probably because too many people confuse the two and draw erroneous conclusions. When you use the URL inspector and everything seems correct, you might believe that Googlebot is normally accessing your content. Except that the inspector does not simulate the constraints of real crawling<\/strong>: no respect for crawl budget, no simulation of server load, no consideration of perceived refresh rate.<\/p> Google probably wants to prevent webmasters from making SEO decisions based on manual tests that do not reflect the reality of automated crawling. [To be checked]<\/strong>: It would be interesting to know if Google plans to add features in Search Console to better simulate the real behavior of Googlebot — for now, nothing indicates that it is the case.<\/p> No, that would be foolish. The URL inspector remains extremely useful<\/strong> for quickly testing if a page can be rendered correctly, if the JavaScript executes well, if the canonical tags are correct. But it should not be used as the sole source of truth.<\/p> To have a complete view, combine the URL inspector with data from the coverage reports<\/strong> in Search Console, server logs, and possibly a third-party crawler configured to respect the crawl budget. It is this triangulation that gives you an accurate picture of what is really happening.<\/p>Why is Google insisting on this definition now? <\/h3>
Should we stop using the URL inspector then? <\/h3>
Practical impact and recommendations
How can you check if Googlebot is really crawling your critical pages? <\/h3>
The first step is to analyze your server logs<\/strong>. There is no other reliable way to know exactly which pages Googlebot visits, how often, and with what behavior. The URL inspector will never give you this information — it does not crawl, it inspects on demand.<\/p> Then, compare this data with the coverage reports in Search Console. If you find that strategic pages are never visited by Googlebot while the URL inspector validates them, you have a crawl budget or architecture problem<\/strong>.<\/p> Never draw definitive conclusions from a single manual test. The URL inspector may tell you that a page is technically accessible, but it will not tell you if Googlebot is actually visiting it in its daily crawl.<\/p> Another classic pitfall: believing that a manually tested page receives the same treatment as a page discovered naturally by the crawler. The context of discovery<\/strong> matters tremendously — a page isolated in the hierarchy without internal linking will rarely be crawled, even if the inspector validates it.<\/p> Work on your internal linking<\/strong> to guide Googlebot to priority pages. Monitor your crawl budget through logs — if Googlebot is wasting time on unnecessary pages (facets, URL parameters), clean it up via robots.txt or noindex tags.<\/p> Ensure that your server response times<\/strong> are optimal. A slow server decreases the number of pages that Googlebot is willing to crawl per session. Finally, regularly update your content on strategic pages — Google crawls more frequently the content it perceives as dynamic.<\/p>What mistakes should you avoid when using manual tools? <\/h3>
What concrete steps can you take to optimize automated crawling? <\/h3>
❓ Frequently Asked Questions
L'inspecteur d'URL de Search Console est-il fiable pour tester l'indexabilité ?
Pourquoi Googlebot ne visite-t-il pas certaines pages validées par l'inspecteur d'URL ?
Quels outils SEO sont considérés comme des crawlers automatisés ?
Comment savoir quelles pages Googlebot crawle vraiment sur mon site ?
Peut-on forcer Googlebot à crawler plus souvent une page stratégique ?
🎥 From the same video 11
Other SEO insights extracted from this same Google Search Central video · published on 21/12/2021
🎥 Watch the full video on YouTube →Related statements
Get real-time analysis of the latest Google SEO declarations
Be the first to know every time a new official Google statement drops — with full expert analysis.
💬 Comments (0)
Be the first to comment.