Official statement
Other statements from this video 11 ▾
- □ Le fichier robots.txt empêche-t-il réellement l'indexation de vos pages ?
- □ Votre outil de test SEO est-il vraiment un crawler aux yeux de Google ?
- □ Googlebot suit-il vraiment les liens ou fonctionne-t-il autrement ?
- □ Le parser robots.txt open source de Google est-il vraiment utilisé en production ?
- □ Pourquoi Google abandonne-t-il les directives d'indexation dans robots.txt ?
- □ Comment Googlebot ajuste-t-il sa fréquence de crawl pour ne pas faire planter vos serveurs ?
- □ Peut-on indexer une page sans la crawler ?
- □ Pourquoi Google refuse-t-il des directives robots.txt trop granulaires ?
- □ Le robots.txt est-il vraiment suffisant pour contrôler le crawl de votre site ?
- □ Qui a vraiment créé le parser robots.txt de Google ?
- □ Pourquoi Google refuse-t-il catégoriquement de moderniser le format robots.txt ?
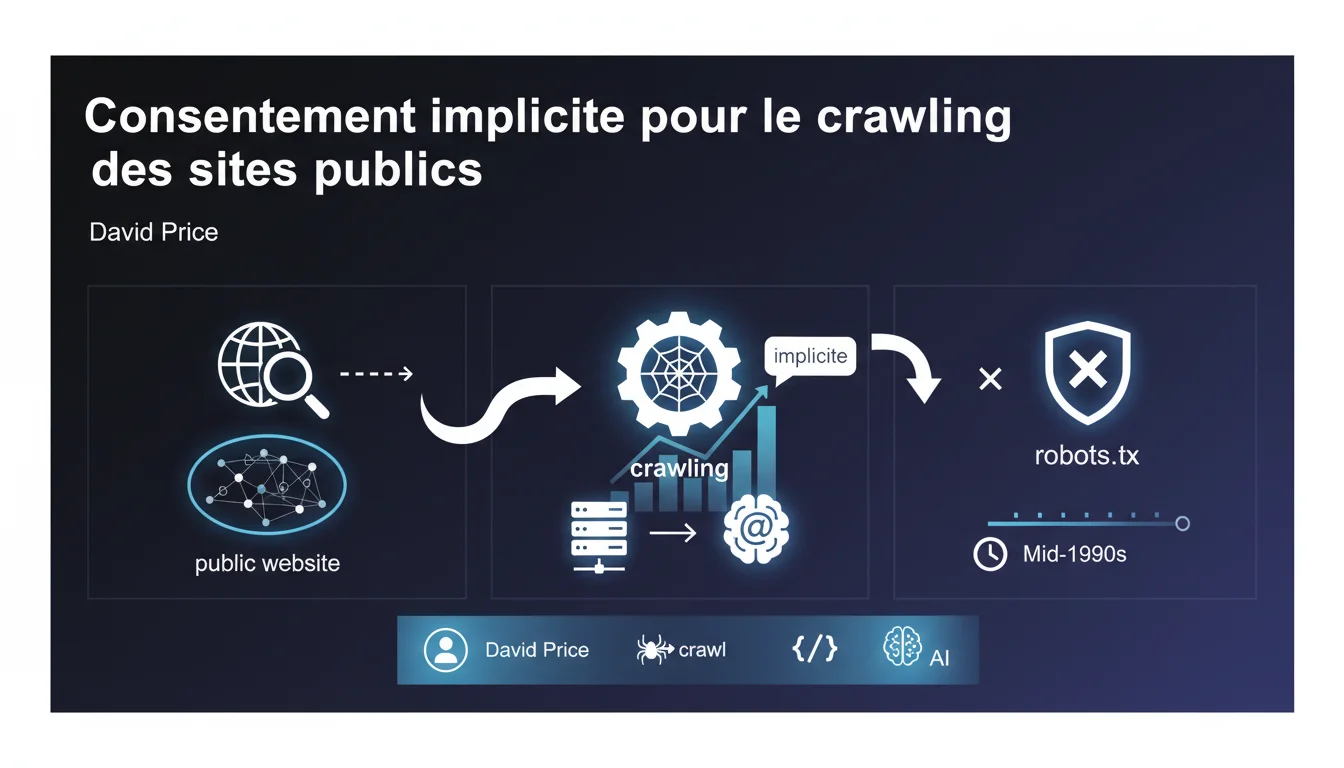
Google claims that a public site legally implies implicit consent for crawling, unless otherwise directed via robots.txt. This legal stance, upheld since the 90s, serves to justify the massive exploration of content without prior explicit authorization. For SEO practitioners, this means that robots.txt remains the only technical safeguard officially recognized by Google.
What you need to understand
What is the implicit consent that Google talks about?<\/h3>
Google argues that by publishing content accessible on the Internet<\/strong>, you tacitly authorize crawling bots to browse it. No formal agreement is needed — merely going online would suffice legally.<\/p> This doctrine of implicit consent<\/strong> is based on a simple logic: if you don't want to be crawled, block access. It's up to the website owner to express refusal, not the search engine to ask for permission.<\/p> The robots.txt<\/strong> file thus becomes the official tool to withdraw this implicit consent. Google considers it a sufficient legal directive to prohibit crawling of certain sections or an entire site.<\/p> Practically speaking, without a blocking robots.txt, Google believes it has a free hand. This interpretation clearly facilitates its massive indexing, but raises questions about semi-public content or poorly configured sites.<\/p> No. The legal framework varies greatly between countries. What Google presents as an established fact since the 90s is still debated, especially in Europe where the GDPR<\/strong> complicates the notion of consent.<\/p> Some courts have validated this approach, while others have contested it. Google relies on favorable American case law, but that doesn't mean all territories subscribe to this view.<\/p>What role does robots.txt play in this logic?<\/h3>
Is this legal position universally accepted?<\/h3>
SEO Expert opinion
Does this statement really reflect a legal consensus?<\/h3>
To be honest, Google is defending its own position here, not an absolute legal truth. The notion of implicit consent<\/strong> facilitates its business model, but it is far from unanimous in European courts.<\/p> The GDPR, for example, requires explicit consent for certain data collections. Claiming that a public site = universal consent to crawl is a s simplification<\/strong> that benefits Google but could be contested on a case-by-case basis. [To be checked]<\/strong> depending on your jurisdiction and the type of content published.<\/p> In theory, yes. In practice, it’s more nuanced. Google generally respects robots.txt for crawling, but this does not prevent the indexing<\/strong> of blocked URLs if they are mentioned elsewhere with a link.<\/p> Moreover, robots.txt is an honorable directive — nothing technically compels a third-party bot to follow it. Google complies, but other crawlers, less scrupulous, don’t care at all. Relying solely on this file is to ignore part of the risk.<\/p> Semi-public spaces<\/strong> pose a challenge: forums requiring registration, content behind a soft paywall, client sections accessible without strict authentication. Where does implicit consent end?<\/p> Google doesn’t specify. The statement remains vague on these borderline cases. Content accessible via direct URL but not intended for the general public — is that really consent for global indexing? [To be checked]<\/strong> case by case with a lawyer if you manage sensitive content.<\/p>Is robots.txt really enough to protect content?<\/h3>
What gray areas remain in this approach?<\/h3>
Practical impact and recommendations
What should you immediately check on your site?<\/h3>
Start by auditing your robots.txt file<\/strong>. Ensure it effectively blocks sensitive sections and does not mistakenly prevent crawling of strategic pages.<\/p> Next, check your meta robots directives<\/strong>: noindex, nofollow, canonical. This is the next layer of control once crawling is allowed. Many sites let unnecessary pages slip through simply because they are technically accessible.<\/p> Do not rely solely on robots.txt to secure truly confidential content. If information should not be public, implement real authentication<\/strong>, not just a lack of internal links.<\/p> Avoid contradictory configurations: robots.txt blocking + XML sitemap submitting the same URLs. Google sometimes indexes these blocked pages if they are referenced elsewhere, creating confusion.<\/p> Take advantage of the default allowance of crawling to optimize the accessibility<\/strong> of strategic content: clear architecture, internal linking, structured sitemap. You have the crawl — so use it to the fullest.<\/p> For low-value or duplicate pages, use noindex or canonical<\/strong> instead of robots.txt. This avoids unnecessarily blocking crawling while keeping control over what appears in search results.<\/p>What mistakes should you avoid to stay in control of your indexing?<\/h3>
How can you ensure your SEO strategy stays aligned with this logic?<\/h3>
❓ Frequently Asked Questions
Si je ne veux pas être crawlé par Google, que dois-je faire concrètement ?
Google peut-il indexer une page bloquée par robots.txt ?
Le consentement implicite s'applique-t-il à tous les moteurs de recherche ?
Un contenu derrière inscription légère est-il considéré comme public par Google ?
Puis-je poursuivre Google si je n'ai pas bloqué le crawl mais que je ne voulais pas être indexé ?
🎥 From the same video 11
Other SEO insights extracted from this same Google Search Central video · published on 21/12/2021
🎥 Watch the full video on YouTube →Related statements
Get real-time analysis of the latest Google SEO declarations
Be the first to know every time a new official Google statement drops — with full expert analysis.
💬 Comments (0)
Be the first to comment.