Official statement
Other statements from this video 11 ▾
- □ Le fichier robots.txt empêche-t-il réellement l'indexation de vos pages ?
- □ Votre outil de test SEO est-il vraiment un crawler aux yeux de Google ?
- □ Le parser robots.txt open source de Google est-il vraiment utilisé en production ?
- □ Pourquoi Google abandonne-t-il les directives d'indexation dans robots.txt ?
- □ Publier un site web équivaut-il juridiquement à autoriser Google à le crawler ?
- □ Comment Googlebot ajuste-t-il sa fréquence de crawl pour ne pas faire planter vos serveurs ?
- □ Peut-on indexer une page sans la crawler ?
- □ Pourquoi Google refuse-t-il des directives robots.txt trop granulaires ?
- □ Le robots.txt est-il vraiment suffisant pour contrôler le crawl de votre site ?
- □ Qui a vraiment créé le parser robots.txt de Google ?
- □ Pourquoi Google refuse-t-il catégoriquement de moderniser le format robots.txt ?
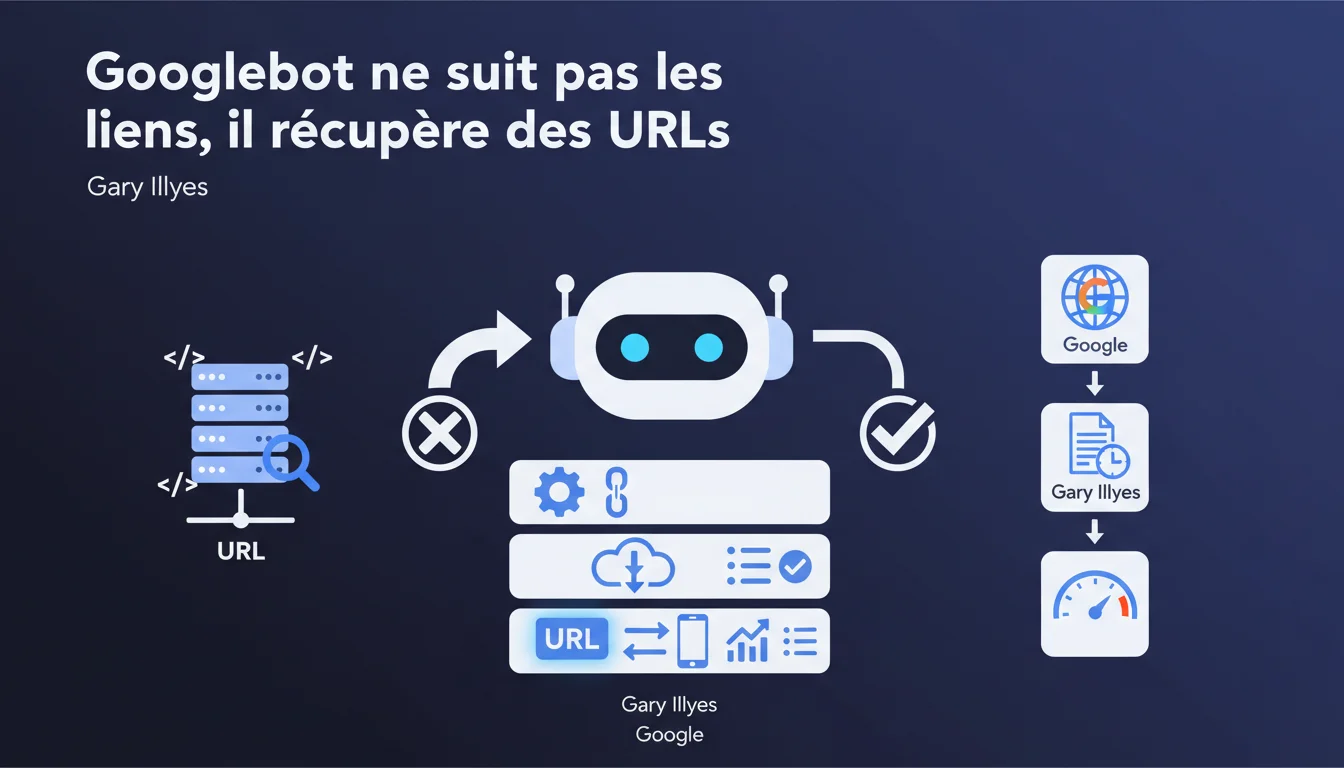
Googlebot doesn't 'follow' links autonomously as many often imagine. It fetches content from a pre-established list of URLs. This nuance alters how we should think about crawling and internal linking: it's not about guiding a bot, but ensuring your URLs end up in its queue.
What you need to understand
Why is this terminological precision important for Google?
Gary Illyes emphasizes one point: Googlebot is not an autonomous agent that 'decides' to click on a link like a human would. It's a fetching system that operates from a list of URLs to explore. The distinction may seem subtle, but it clarifies the actual mechanism: Googlebot has no independent initiative, it executes a queue of tasks.
This rephrasing aligns better with Google's technical architecture. The engine compiles URLs from various sources — sitemaps, discovered links, manual submissions, crawling history — and then adds them to a queue. The 'link following' is actually a process of discovering and adding URLs to this list.
What’s the concrete difference from the classic view of crawling?
The classic view presents Googlebot as an automated browser that 'clicks' on every encountered link. The reality is more prosaic: when Googlebot fetches a page, it extracts the URLs present (attributes href, sitemaps, redirects, etc.), adds them to its queue, and then moves on to the next URL on the list.
This logic changes two things. First, the crawl order is not linear as one might think — it depends on priorities calculated by Google (internal PageRank, freshness, depth, quality signals). Second, a link is not 'followed' instantly: it is added to a queue that may be processed much later, or never if the crawl budget is exhausted.
What are the implications for internal linking and crawl budget?
If Googlebot manages a queue of URLs rather than 'navigating' your site, then the structure of internal linking primarily impacts discoverability and crawl priority. A deeply buried page may take weeks to enter the queue — or may never enter if no link references it.
The crawl budget becomes a queue management question: how many URLs does Google accept to fetch daily from your domain? If your site generates thousands of low-value URLs, they clog the queue and delay the exploration of strategic content.
- Googlebot works off a queue of URLs, not in 'autonomous browsing' mode
- Links serve to discover and prioritize URLs, not to 'follow' them instantly
- The crawl budget limits the number of URLs fetched per day, not the number of 'clicks'
- A good internal linking structure accelerates the addition of strategic URLs to the queue
SEO Expert opinion
Is this statement consistent with observed practices?
Yes, completely. In practice, orphan pages — without incoming links — are never crawled, unless they appear in a sitemap or are manually submitted via Search Console. This confirms that Googlebot does not 'browse' randomly: it compiles URLs from explicit sources.
Similarly, crawl delays vary significantly depending on the page's depth and authority. A URL mentioned on the homepage can be added to the queue in a few minutes. A page buried 5 clicks deep may wait weeks. This is typical of a priority queue system, not a linear crawl.
What nuances should be added to this explanation?
Gary Illyes simplifies to correct a misconception, but the reality remains complex. Googlebot does use links to discover URLs — the nuance lies in the timing and logic of fetching. A link is not 'clicked' immediately; it is extracted, analyzed, and then added to a queue that follows opaque priority rules.
Another point: not all links hold the same weight in this logic. A nofollow link can still help discover a URL, but Google won’t pass PageRank through it. A JavaScript link can be extracted if rendering is done, otherwise it is ignored. Discoverability and PageRank are two distinct processes.
In what cases does this rule not apply fully?
On highly authoritative sites, Googlebot can crawl URLs with a high frequency and impressive depth. In this case, the 'queue' is processed so fast that it resembles real-time crawling. But the principle remains the same: it's a queue, not browsing.
For sites that continuously publish fresh content (media, e-commerce), Google also uses freshness signals to prioritize certain sections. Again, this does not change the underlying mechanism, but it shows that crawl priority can be dynamic — and that Google does not rely on a fixed order.
Practical impact and recommendations
What concrete actions should be taken to optimize discoverability?
Since Googlebot compiles URLs from various sources, multiply your entry points: updated XML sitemap, internal links from high-authority pages, mentions in RSS feeds if relevant. The goal is to get your strategic URLs into the queue as quickly as possible.
Monitor the click depth: a page that is 6 clicks from the homepage will be discovered late, if at all. Move priority content up the hierarchy — through links from the homepage, menus, or 'recommended content' blocks.
What mistakes should be avoided to prevent clogging the URL queue?
Do not generate unnecessary URLs. Superfluous URL parameters, low-value filter pages, endless archives pollute the queue and waste the crawl budget. Use robots.txt, the noindex tag, or canonicals to exclude parasitic URLs.
Avoid redirect chains and recurring 404 errors. Each redirect or error consumes a slot in the queue without providing useful content. Regularly clean up your internal linking to remove dead or outdated links.
How can you check that your site is well configured?
Check the Coverage report in Search Console: it shows which URLs Google has discovered, which are crawled, and which are excluded. If strategic pages remain in 'Discovered, not crawled', it's a signal that your queue is clogged or that those URLs are poorly prioritized.
Also analyze the Crawl Stats report to track the daily volume of pages fetched and errors. A sharp drop in crawling may indicate a technical problem — slow server, robots.txt blocks, explosion in low-value URLs.
- Maintain a clean and updated XML sitemap with only indexable URLs
- Reduce the click depth of strategic pages (ideally ≤ 3 clicks)
- Remove parasitic URLs (unnecessary filters, superfluous parameters, endless archives)
- Fix redirect chains and recurring 404 errors
- Monitor the Coverage and Crawl Stats reports in Search Console
- Strengthen the internal linking to priority content from high-authority pages
❓ Frequently Asked Questions
Googlebot explore-t-il les liens en nofollow ?
Une page sans lien entrant peut-elle être explorée par Google ?
Pourquoi certaines pages découvertes ne sont-elles jamais explorées ?
Le sitemap XML accélère-t-il vraiment l'exploration ?
Comment éviter que des URLs inutiles consomment mon crawl budget ?
🎥 From the same video 11
Other SEO insights extracted from this same Google Search Central video · published on 21/12/2021
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.