Official statement
Other statements from this video 17 ▾
- □ Pourquoi votre site n'apparaît-il pas dans Google : indexation ou ranking ?
- □ Pourquoi Google pousse-t-il Search Console pour diagnostiquer l'indexation ?
- □ L'URL Inspection Tool de Search Console remplace-t-il vraiment le test d'indexation manuel ?
- □ Le rapport d'indexation de la Search Console suffit-il vraiment à diagnostiquer vos problèmes d'indexation ?
- □ Faut-il vraiment chercher à indexer 100% de ses pages ?
- □ Pourquoi Google indexe-t-il toujours la page d'accueil en premier sur un nouveau site ?
- □ Pourquoi la page d'accueil de votre nouveau site ne s'indexe-t-elle pas ?
- □ Pourquoi votre homepage n'apparaît-elle toujours pas dans l'index Google ?
- □ Votre site est-il vraiment absent de l'index Google ou juste victime de la canonicalisation ?
- □ Hreflang fausse-t-il vos rapports d'indexation dans Search Console ?
- □ Pourquoi vos pages 'site en construction' ne seront jamais indexées par Google ?
- □ Pourquoi certaines pages s'indexent en quelques secondes et d'autres jamais ?
- □ Google peut-il encore indexer l'intégralité du web ?
- □ Faut-il supprimer l'ancien contenu pour améliorer l'indexation du nouveau ?
- □ Faut-il vraiment utiliser la fonction 'Demander une indexation' de la Search Console ?
- □ L'opérateur site: est-il vraiment fiable pour mesurer l'indexation de votre site ?
- □ Comment exploiter vraiment l'opérateur site: au-delà de la simple vérification d'indexation ?
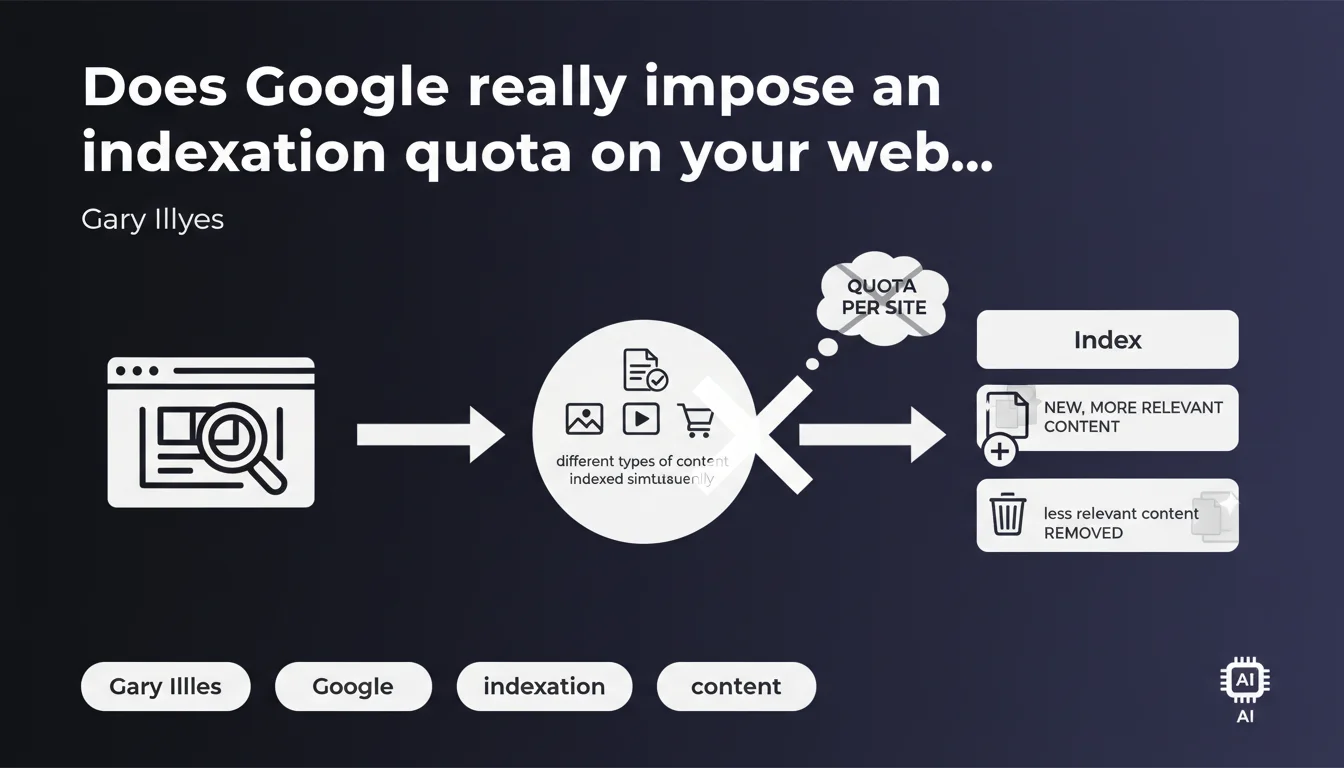
Google claims it does not limit the number of pages indexed per site through a fixed quota. A single domain can have different types of content indexed simultaneously, but certain pages can be set aside in favor of newer and more relevant content elsewhere on the web. Indexation therefore remains selective, even without an imposed numerical ceiling.
What you need to understand
This statement from Gary Illyes clarifies a frequent misunderstanding among SEO professionals: Google does not impose a numerical limit on the number of pages a site can have in its index. Contrary to what some imagine, there is no rule like "maximum 10,000 pages per domain".
That said, the absence of a quota does not mean everything will be indexed. Google makes choices based on relevance, quality, and its own crawl budget. What matters is the value each page brings — not raw volume.
Why does Google refuse to index certain pages despite the absence of a quota?
Google manages billions of pages. Even without a quota per site, it must prioritize its resources. If your content is deemed less relevant or redundant compared to what already exists on the web, it can be excluded — temporarily or permanently.
This filtering relies on signals such as freshness, domain authority, content quality, and user engagement. A technically crawlable page is not automatically indexable if it does not pass these filters.
Can a single site have multiple types of content indexed in parallel?
Yes, and this is often misunderstood. Google can simultaneously index blog articles, product sheets, category pages, and institutional pages on the same domain.
Each type of content is evaluated according to its own criteria. An e-commerce site with 50,000 products can see part of its catalog indexed while other sections remain ignored — it all depends on the relevance perceived by the algorithm.
What does "making room" in the Google index mean?
The expression is misleading. Google does not actively "delete" your pages to free up space like you would on a hard drive. It is rather a matter of continuous prioritization: if your content ages poorly or loses relevance, it can drop out of the index in favor of newer content elsewhere.
It is a dynamic process. A page de-indexed today can return tomorrow if it gains authority or if the competitive landscape evolves.
- No fixed quota: a site can theoretically have millions of indexed pages if they are all relevant
- Selective indexation: Google chooses what it indexes based on quality and added value
- Separate crawl budget: crawling and indexation are two separate mechanics — a crawled page is not necessarily indexed
- Continuous prioritization: the index is a dynamic space where lower-performing pages can be excluded
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes and no. On paper, the absence of a quota is true — we see sites with several hundred thousand indexed pages without issue. Major media outlets, classified ad sites, massive e-commerce platforms: all prove Google can absorb enormous volumes.
But in practice, many sites encounter indexation blockages even with just a few thousand pages. The infamous "Discovered – currently not indexed" in Search Console hits domains of all sizes. [To verify]: is Google really underestimating the relevance of these pages, or are there hidden criteria that look suspiciously like an implicit quota based on domain authority?
What nuances should be added to this statement?
First point: Google talks about a quota "per site," but says nothing about quotas by content type. We regularly observe that certain types of pages (filters, tags, product variants) are systematically ignored even on powerful domains.
Second nuance: the absence of a quota does not mean absence of a quality threshold. If your site massively produces thin or duplicate content, Google can "freeze" part of the indexation — not via a counter, but via a qualitative filter. In practice, for the publisher, it is the same as a quota.
In which cases does this rule seem not to apply?
Small sites with low authority often suffer drastic restrictions. A niche blog with 500 articles may see only 100 pages indexed, while a reference media outlet with 100,000 pages will be indexed at 95%. Authority context plays a determining role — and Google never admits it frankly.
Another edge case: sites with very high publication velocity (aggregators, forums, classified ad sites). Google indexes quickly, but also de-indexes quickly if content does not generate engagement. The net result can give the impression of a ceiling, when it is actually rapid turnover.
Practical impact and recommendations
What should you do concretely to optimize your indexation?
First, qualify your content. If Google has no quota, no need to force the indexation of weak pages. Focus on high-value pages: de-index or noindex redundant content, facet filters, empty tag pages.
Next, optimize your crawl budget. Even without an indexation quota, Google will not crawl everything if your site architecture is chaotic. Make the bots' job easier: clean XML sitemap, coherent internal linking, fast server response time.
What mistakes should you avoid facing this reality?
Do not confuse volume with performance. Publishing massively guarantees nothing if quality is not on par. Many sites inflate their index with product variants or auto-generated articles — then wonder why Google ignores everything.
Another pitfall: believing a crawled page will be indexed. Crawling is not indexation. You can see Googlebot passing daily on pages that will never be in the index. Monitor Search Console, particularly the "Coverage" section, to spot "Discovered – not indexed" pages.
How can you verify that your site is taking full advantage of this absence of quota?
Analyze the ratio of indexed pages to indexable pages. If you have 10,000 quality pages and only 2,000 are indexed, you have a problem — even without an official quota. Dig into server logs to see if Google is crawling but not indexing, or if it is ignoring certain sections entirely.
Use the coverage reports in Search Console to identify exclusion reasons. "Discovered – currently not indexed" often signals a perceived quality issue or lack of authority. "Crawled – currently not indexed" indicates Google saw the page but decides not to keep it.
- Audit your indexable pages: eliminate noise (facets, empty tags, unnecessary variants)
- Prioritize internal linking toward your strategic pages to signal their importance
- Optimize technical performance: response time, clean architecture, no redirect chains
- Monitor Search Console "Coverage" and "Pages" reports to detect abnormal exclusions
- Test indexation via the "URL Inspection" tool on your key pages
- Regularly reassess your content quality: freshness, depth, uniqueness
❓ Frequently Asked Questions
Si Google n'a pas de quota par site, pourquoi certaines de mes pages restent-elles non indexées ?
Un gros site e-commerce peut-il avoir toutes ses fiches produits indexées ?
Le crawl budget et l'indexation sont-ils la même chose ?
Comment réagir face au statut « Découvert – actuellement non indexé » ?
Google peut-il désindexer des pages anciennes pour faire de la place ?
🎥 From the same video 17
Other SEO insights extracted from this same Google Search Central video · published on 22/06/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.