Official statement
Other statements from this video 9 ▾
- □ Pourquoi le rendu côté client (CSR) met-il votre indexation Google en danger ?
- □ Pourquoi un échec de rendu JavaScript peut-il retarder votre indexation de plusieurs semaines ?
- □ Le JavaScript est-il vraiment indexé par Google ou faut-il encore s'en méfier ?
- □ Pourquoi le rendu côté client pose-t-il un problème structurel pour le crawl Google ?
- □ Faut-il abandonner le rendu côté client pour améliorer son référencement naturel ?
- □ Faut-il vraiment privilégier le code 410 au 404 pour signaler une page supprimée ?
- □ Est-ce que Google traite vraiment les codes 429, 503 et 500 de la même manière ?
- □ Les domaines Web3 (.eth) sont-ils crawlables par Google ?
- □ Pourquoi vos utilisateurs tapent-ils le nom de votre marque dans Google plutôt que votre URL ?
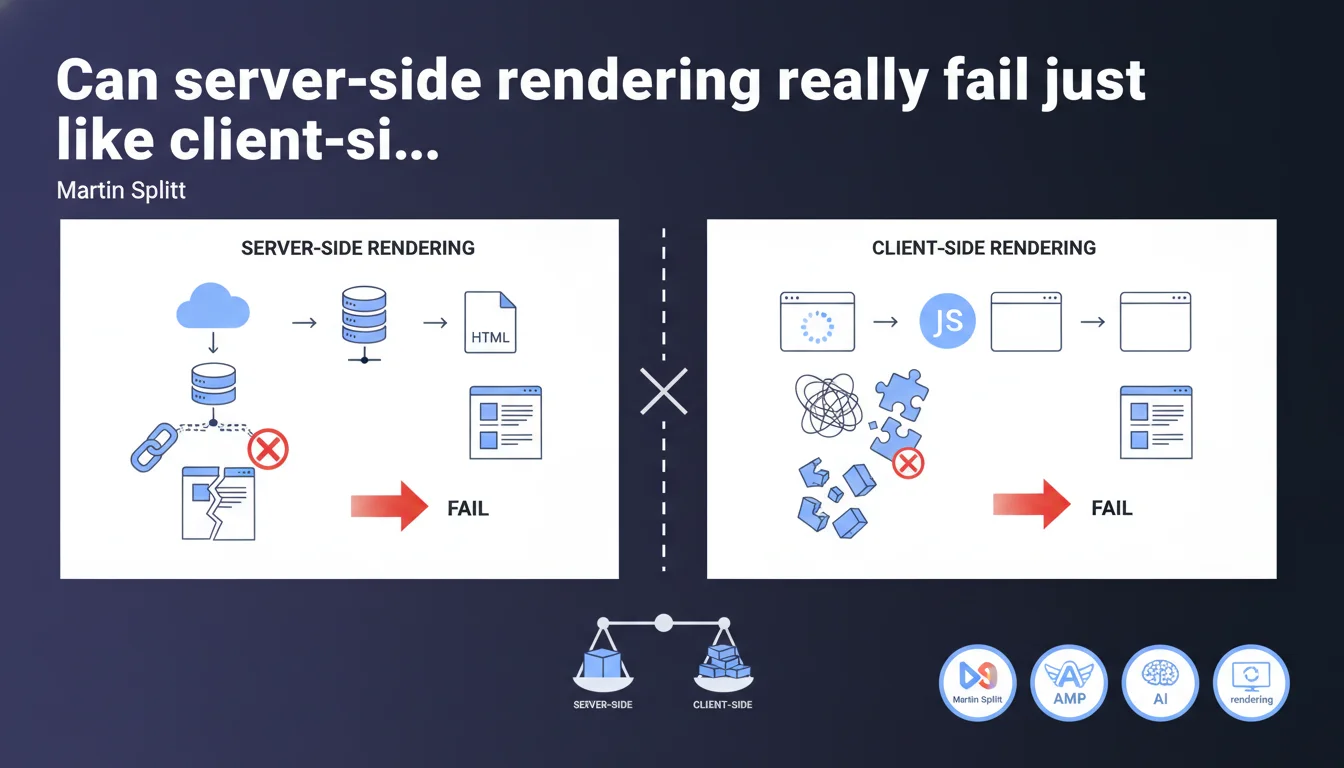
Google reminds us that SSR (server-side rendering) can also produce incomplete HTML if technical failures occur — database connection issues, timeouts, application errors. CSR (client-side rendering) remains more fragile, but SSR is not an absolute guarantee of indexability if the backend chain fails.
What you need to understand
Why does Google nuance the SSR vs CSR opposition?
Martin Splitt's statement comes in a context where many SEO practitioners consider server-side rendering as the ultimate solution to guarantee indexing. Google is reminding us here that SSR relies on a backend technical chain — database, API, application server — which can also break down.
If your Node.js server cannot connect to PostgreSQL when Googlebot makes a request, the HTML returned will be incomplete or empty. Same logic as a CSR site that crashes when loading JavaScript, except the failure occurs before the HTML reaches the browser.
Is CSR really more fragile in practice?
Yes, and Splitt confirms this explicitly. Client-side rendering depends on multiple layers: JS download, parsing, execution, hydration, API calls. Each step can fail — network timeout, JS error, rendering budget exceeded, JavaScript disabled on Googlebot (rare but possible in degraded mode).
SSR eliminates these client-side risks, but introduces others on the server side. The difference? Backend failures are generally visible in server logs and detectable through monitoring, whereas a JS error on Googlebot can go unnoticed for weeks.
What should you remember about indexing reliability?
- SSR reduces client-side failure points, but is not guaranteed if the backend stack is unstable.
- A well-architected CSR site with HTML fallback can be more reliable than fragile SSR with an overloaded database.
- Google continues to crawl and index CSR — the issue is not binary, it's a question of statistical reliability.
- SSR errors (500, timeout) are visible in Search Console, CSR errors (crashing JS) are not always.
- A site's resilience depends as much on backend architecture as on the rendering mode chosen.
SEO Expert opinion
Is this statement consistent with real-world observations?
Absolutely. We regularly observe SSR sites serving partial or empty HTML to Googlebot due to database timeouts, Redis caches going down, microservices becoming unavailable. The crawler doesn't distinguish between SSR that fails and CSR that crashes — it just sees incomplete HTML.
What changes? The frequency of failures. A poorly optimized CSR can fail on 10-20% of Googlebot crawls (JS errors, budget exceeded), while a well-monitored SSR fails less than 1% of the time. But when it does fail, the impact can be massive if it's a global configuration problem.
What nuances should be added to this message?
Splitt is talking about technical failures, not implementation complexity. A properly deployed Next.js or Nuxt SSR on Vercel or Netlify is statistically more reliable than a pure React SPA. But poorly architected custom SSR, with an unreplicated database and no circuit breaker, can become an indexing nightmare.
Another point: Google doesn't specify whether these SSR failures impact ranking or just occasional indexing. [To verify] — we lack data on Google's tolerance for intermittent SSR errors. Does 5% backend failure degrade rankings? No official data on this.
In what cases does SSR pose more problems than CSR?
When the site depends on real-time external data for each page — third-party APIs, remote databases, heavy server-side computations. If your SSR waits 3 seconds to query an API before returning HTML, Googlebot risks timing out before receiving the content.
CSR with skeleton screens and progressive hydration can in this case be more resilient: the basic HTML loads immediately, JS completes afterward. Google sees at least the page structure, even if dynamic content takes time.
Practical impact and recommendations
What should you do concretely to secure an SSR site?
Monitor 5xx server errors in Search Console and your backend logs. A spike in 500 errors during Googlebot crawling signals an SSR problem you may not see on the user side (cache, CDN).
Implement graceful fallbacks: if database connection fails, still serve minimal HTML with title tags, meta description, and semantic structure. Partial content is better than a blank page.
Test resilience with chaos engineering tests: simulate database outages, API timeouts, server overloads while Googlebot crawls. Verify that your SSR degrades gracefully instead of crashing.
What errors should you avoid during SSR migration?
- Don't fail to set up backend monitoring before migration — you'll discover problems too late.
- Don't assume SSR solves all indexing problems — if your content depends on slow API calls, the problem persists.
- Don't forget to configure server-side timeouts — an SSR waiting 30 seconds for a DB response will lose Googlebot.
- Don't migrate to SSR without verifying your backend load capacity — Googlebot's massive crawl can saturate your database.
- Don't forget to set up a circuit breaker: if your database goes down, all SSR renderings fail in cascade.
How to verify that your SSR is reliable for Googlebot?
Inspect pages via the URL Inspection Tool in Search Console and compare the rendered HTML with what you get by simulating a server request (curl with Googlebot user-agent). If content differs or you see errors, your SSR isn't stable.
Analyze server logs: filter Googlebot requests and look for 500, 502, 503, 504 codes. An error rate above 2-3% deserves investigation. Also check response times — a TTFB above 1 second risks causing crawl timeouts.
❓ Frequently Asked Questions
Est-ce que Google préfère le SSR au CSR pour l'indexation ?
Quels types d'échecs SSR empêchent l'indexation ?
Un site en CSR peut-il quand même bien se classer dans Google ?
Comment détecter qu'un problème SSR impacte mon indexation ?
Le pré-rendering statique est-il plus fiable que le SSR dynamique ?
🎥 From the same video 9
Other SEO insights extracted from this same Google Search Central video · published on 30/05/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.