Official statement
Other statements from this video 9 ▾
- □ Pourquoi le rendu côté client (CSR) met-il votre indexation Google en danger ?
- □ Le JavaScript est-il vraiment indexé par Google ou faut-il encore s'en méfier ?
- □ Pourquoi le rendu côté client pose-t-il un problème structurel pour le crawl Google ?
- □ Le rendu côté serveur est-il vraiment plus fiable que le rendu client ?
- □ Faut-il abandonner le rendu côté client pour améliorer son référencement naturel ?
- □ Faut-il vraiment privilégier le code 410 au 404 pour signaler une page supprimée ?
- □ Est-ce que Google traite vraiment les codes 429, 503 et 500 de la même manière ?
- □ Les domaines Web3 (.eth) sont-ils crawlables par Google ?
- □ Pourquoi vos utilisateurs tapent-ils le nom de votre marque dans Google plutôt que votre URL ?
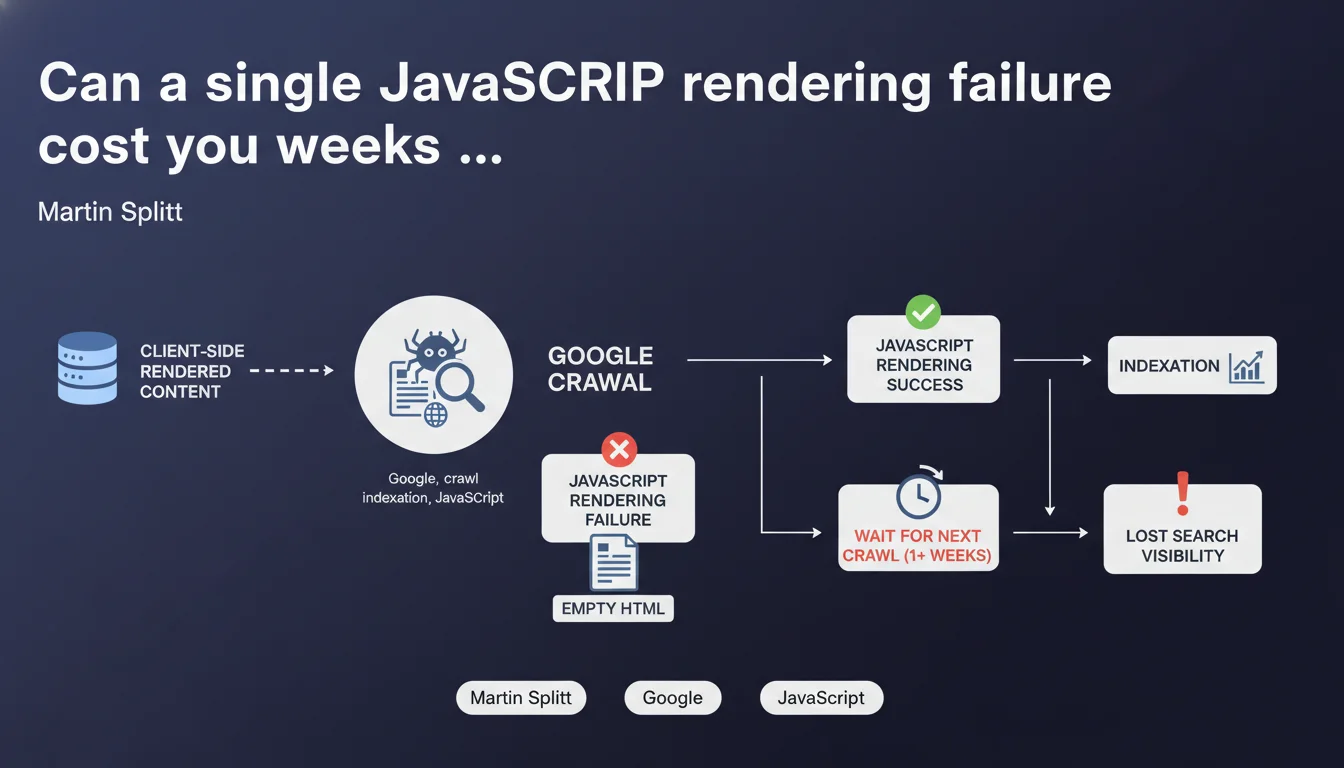
If JavaScript rendering fails during Google's crawl of client-side rendered content, the search engine finds only empty HTML and indexes nothing. Indexing is then pushed back to the next crawl, potentially a week or more away. For pure CSR sites, a single technical failure can completely block visibility during a critical period.
What you need to understand
Google first crawls the raw HTML, then goes through a JavaScript rendering phase to generate the final DOM. This two-stage separation creates a window of vulnerability for Client-Side Rendering sites.
If the JS crashes, times out, or encounters a network error during this phase, Google ends up with an empty HTML skeleton. Result: nothing to index, even if your content theoretically exists.
What can cause a rendering failure on Google's side?
The causes are multiple and often difficult to reproduce in a dev environment. A network timeout while loading a critical JS dependency, an error in the code that blocks execution, or even a third-party resource (analytics, chat, advertising) that crashes the rest.
The problem: you don't see these errors in your browser. Googlebot has its own resource constraints and can fail where Chrome succeeds.
Why does waiting a week or more create problems?
The time between two crawls depends on the crawl budget allocated to your site. For an average site, Google might return to a URL every 3-7 days — or longer if the site is slow or considered less "important" by the algorithm.
Concretely? Your new product, breaking news article, or critical update remains invisible during this period. In competitive sectors, that's a missed window of opportunity.
- Pure CSR = maximum risk: if the initial HTML is empty, a rendering failure means zero indexable content
- SSR/SSG = safety net: even if JS fails, the pre-rendered HTML already contains the essential content
- Googlebot-side errors are invisible to developers without specific monitoring (Search Console, server logs)
- Crawl budget is not unlimited: the more Google fails to render, the less often it will return
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes, and it's actually an understatement. In the field, I've seen React/Vue sites lose weeks of indexation due to intermittent JS errors. Splitt's "a week or more" is the low end of the range — on sites with tight crawl budgets, it can easily climb to 15-20 days.
What's frustrating: Google doesn't systematically alert you in Search Console when rendering fails. You discover the problem when you notice your pages aren't ranking, weeks after publication.
What nuances should be added to this statement?
Splitt speaks of "complete" rendering failure. But there are also partial failures — for example, the main content loads, but a secondary component crashes and prevents the footer from displaying. Google then indexes an incomplete version, which can affect perceived relevance.
Another point: not every crawl goes through JS rendering. Google may decide to crawl without executing JS in certain contexts (quick crawl, limited resources). If your initial HTML is empty, you're invisible even without a "technical" failure. [To verify] what proportion of Google crawls actually activate the rendering engine — official data is unclear.
In which cases does this rule not apply?
If you're using Server-Side Rendering or static generation (SSG), the initial HTML already contains critical content. A JS failure on Google's side degrades user experience, but doesn't prevent indexation of essential content.
Same outcome with progressive hydration: the base HTML is served, JS adds interactivity. If JS crashes, Google still indexes the basic structure.
Practical impact and recommendations
How can you verify that your site is vulnerable to this problem?
First step: view-source your critical pages. If the raw HTML contains only an empty <div id="root"></div>, you're in pure CSR and therefore exposed to the risk described by Splitt.
Second check: use the URL inspection tool in Search Console and compare the rendered HTML to the raw HTML. If the gap is massive, you're entirely dependent on successful JS rendering by Google.
Third step: analyze your server logs to spot Googlebot requests that end in 5xx errors or timeouts. A failure rate > 2-3% is a warning sign.
What corrective actions should you implement immediately?
- Migrate to SSR or SSG for critical content (product pages, articles, landing pages)
- Implement a system to monitor rendering on Googlebot's side (logs, Search Console alerts, third-party tools like OnCrawl)
- Reduce third-party JS dependencies that can block execution (ads, social widgets, chat)
- Optimize JS loading times: compression, lazy loading, code splitting to stay under Google's timeout thresholds
- Regularly test your pages with a Googlebot user-agent and degraded network conditions (throttling, latency)
- Set up a static HTML fallback for essential content, even on an SPA
What strategy should you adopt for new projects?
Let's be honest: in 2024, starting an SEO-critical site in pure CSR is reckless. Modern frameworks (Next.js, Nuxt, SvelteKit) offer SSR/SSG out-of-the-box — there's no technical excuse anymore.
For legacy projects in pure React/Vue/Angular, migration to a hybrid architecture takes time and resources. But the ROI is immediate: reliable indexation, improved Core Web Vitals, resilience against crawl unpredictability.
In summary: A JS rendering failure delays indexation by at least a week, sometimes several weeks on sites with low crawl budget. Pure CSR sites are playing Russian roulette with their visibility. The sustainable solution involves SSR/SSG, but often requires significant technical refactoring.
These optimizations touch on front-end architecture, server performance, and crawl strategy issues. If your team lacks expertise in these areas or you don't have internal resources to audit and fix these vulnerabilities, support from an SEO-specialized agency can significantly accelerate compliance and secure your indexation.
❓ Frequently Asked Questions
Le SSR est-il la seule solution pour éviter les échecs de rendu ?
Comment savoir si Google a échoué à rendre mes pages ?
Un échec de rendu impacte-t-il aussi le ranking des pages déjà indexées ?
Les frameworks JavaScript modernes résolvent-ils ce problème automatiquement ?
Googlebot utilise-t-il toujours Chrome récent pour le rendu JavaScript ?
🎥 From the same video 9
Other SEO insights extracted from this same Google Search Central video · published on 30/05/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.