Declaration officielle
Autres déclarations de cette vidéo 9 ▾
- □ Pourquoi le rendu côté client (CSR) met-il votre indexation Google en danger ?
- □ Le JavaScript est-il vraiment indexé par Google ou faut-il encore s'en méfier ?
- □ Pourquoi le rendu côté client pose-t-il un problème structurel pour le crawl Google ?
- □ Le rendu côté serveur est-il vraiment plus fiable que le rendu client ?
- □ Faut-il abandonner le rendu côté client pour améliorer son référencement naturel ?
- □ Faut-il vraiment privilégier le code 410 au 404 pour signaler une page supprimée ?
- □ Est-ce que Google traite vraiment les codes 429, 503 et 500 de la même manière ?
- □ Les domaines Web3 (.eth) sont-ils crawlables par Google ?
- □ Pourquoi vos utilisateurs tapent-ils le nom de votre marque dans Google plutôt que votre URL ?
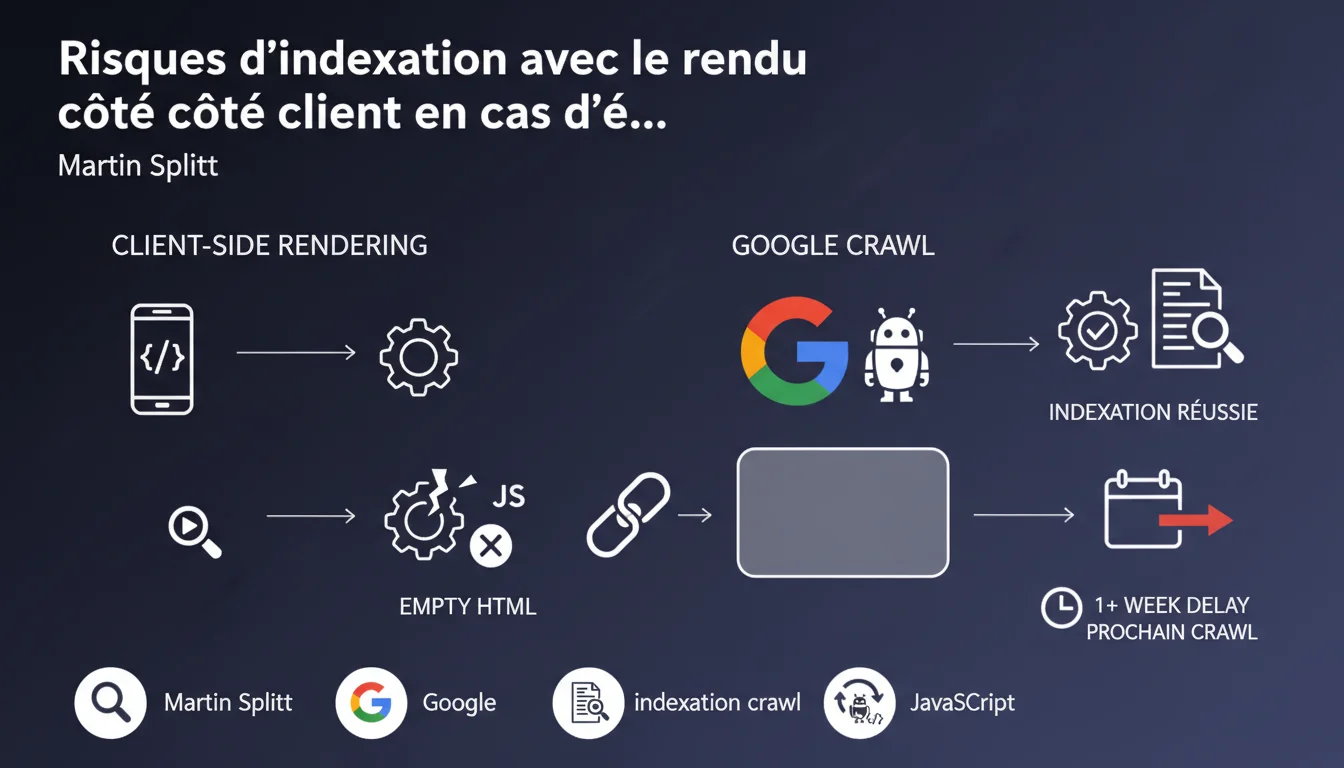
Si le rendu JavaScript échoue pendant le crawl de Google, le moteur ne trouve qu'un HTML vide et n'indexe rien. L'indexation est alors repoussée au prochain crawl, soit potentiellement une semaine ou plus. Pour les sites en CSR pur, un seul raté technique peut donc bloquer complètement la visibilité sur une période critique.
Ce qu'il faut comprendre
Google crawle d'abord le HTML brut, puis passe par une phase de rendu JavaScript pour générer le DOM final. Cette séparation en deux temps crée une fenêtre de vulnérabilité pour les sites en Client-Side Rendering.
Si le JS plante, timeout ou rencontre une erreur réseau pendant cette phase, Google se retrouve avec un squelette HTML vide. Résultat : rien à indexer, même si votre contenu existe théoriquement.
Qu'est-ce qui peut provoquer un échec de rendu côté Google ?
Les causes sont multiples et souvent difficiles à reproduire en environnement de dev. Un timeout réseau pendant le chargement d'une dépendance JS critique, une erreur dans le code qui bloque l'exécution, ou même une ressource tierce (analytics, chat, publicité) qui fait planter le reste.
Le problème : vous ne voyez pas ces erreurs dans votre navigateur. Googlebot a ses propres contraintes de ressources et peut échouer là où Chrome réussit.
Pourquoi attendre une semaine ou plus pose problème ?
Le délai entre deux crawls dépend du crawl budget alloué à votre site. Pour un site moyen, Google peut revenir sur une URL tous les 3-7 jours — voire plus si le site est lent ou peu « important » aux yeux de l'algo.
Concrètement ? Votre nouveau produit, votre article d'actualité ou votre mise à jour critique reste invisible pendant cette période. Sur des secteurs concurrentiels, c'est une fenêtre de tir ratée.
- CSR pur = risque maximum : si le HTML initial est vide, un échec de rendu signifie zéro contenu indexable
- SSR/SSG = filet de sécurité : même en cas d'échec JS, le HTML pré-rendu contient déjà le contenu essentiel
- Les erreurs côté Googlebot sont invisibles côté développeur sans monitoring spécifique (Search Console, logs serveur)
- Le crawl budget n'est pas illimité : plus Google échoue à renderer, moins il reviendra souvent
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, et c'est même un euphémisme. Sur le terrain, j'ai vu des sites en React/Vue pur perdre des semaines d'indexation à cause d'erreurs JS intermittentes. Le « une semaine ou plus » de Splitt, c'est la fourchette basse — sur des sites avec un crawl budget serré, ça peut facilement grimper à 15-20 jours.
Ce qui coince : Google ne vous alerte pas systématiquement en Search Console quand le rendu échoue. Vous découvrez le problème quand vous constatez que vos pages ne rankent pas, plusieurs semaines après publication.
Quelles nuances faut-il apporter à cette affirmation ?
Splitt parle d'échec « total » du rendu. Mais il existe aussi des échecs partiels — par exemple, le contenu principal charge, mais un composant secondaire plante et empêche le footer de s'afficher. Google indexe alors une version incomplète, ce qui peut affecter la pertinence perçue.
Autre point : tous les crawls ne passent pas par le rendu JS. Google peut décider de crawler sans exécuter le JS dans certains contextes (crawl rapide, ressources limitées). Si votre HTML initial est vide, vous êtes invisible même sans « échec » technique. [A vérifier] sur quelle proportion de crawls Google active réellement le moteur de rendu — les données officielles sont floues.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si vous utilisez du Server-Side Rendering ou de la génération statique (SSG), le HTML initial contient déjà le contenu critique. Un échec JS côté Google dégrade l'expérience utilisateur, mais n'empêche pas l'indexation du contenu essentiel.
Même constat avec l'hydratation progressive : le HTML de base est servi, le JS ajoute l'interactivité. Si le JS plante, Google indexe quand même la structure de base.
Impact pratique et recommandations
Comment vérifier que votre site est vulnérable à ce problème ?
Premier réflexe : view-source sur vos pages critiques. Si le HTML brut ne contient qu'un <div id="root"></div> vide, vous êtes en CSR pur et donc exposé au risque décrit par Splitt.
Deuxième check : utilisez l'outil de test des URL dans Search Console et regardez le HTML rendu vs. le HTML brut. Si l'écart est massif, vous dépendez entièrement du bon fonctionnement du rendu JS côté Google.
Troisième étape : analysez vos logs serveur pour repérer les requêtes Googlebot qui se terminent par des erreurs 5xx ou des timeouts. Un taux d'échec > 2-3 % est un signal d'alarme.
Quelles actions correctives mettre en place immédiatement ?
- Migrer vers du SSR ou SSG pour les contenus critiques (pages produits, articles, landing pages)
- Implémenter un système de monitoring du rendu côté Googlebot (logs, alertes Search Console, outils tiers type OnCrawl)
- Réduire les dépendances JS tierces qui peuvent bloquer l'exécution (publicitaires, widgets sociaux, chat)
- Optimiser les temps de chargement JS : compression, lazy loading, code splitting pour rester sous les seuils de timeout de Google
- Tester régulièrement vos pages avec un user-agent Googlebot et des conditions réseau dégradées (throttling, latence)
- Mettre en place un fallback HTML statique pour les contenus essentiels, même sur une SPA
Quelle stratégie adopter pour les nouveaux projets ?
Soyons honnêtes : en 2024, démarrer un site SEO-critique en CSR pur relève de l'inconscience. Les frameworks modernes (Next.js, Nuxt, SvelteKit) offrent du SSR/SSG out-of-the-box — il n'y a plus d'excuse technique.
Pour les projets legacy en React/Vue/Angular pur, la migration vers une architecture hybride demande du temps et des ressources. Mais le ROI est immédiat : indexation fiable, Core Web Vitals améliorés, résilience face aux aléas de crawl.
En résumé : Un échec de rendu JS retarde l'indexation d'une semaine minimum, voire plusieurs sur des sites à faible crawl budget. Les sites en CSR pur jouent à la roulette russe avec leur visibilité. La solution pérenne passe par du SSR/SSG, mais elle nécessite souvent une refonte technique non négligeable.
Ces optimisations touchent à des enjeux d'architecture front-end, de performance serveur et de stratégie de crawl. Si votre équipe manque d'expertise sur ces sujets ou si vous n'avez pas les ressources internes pour auditer et corriger ces vulnérabilités, un accompagnement par une agence SEO spécialisée peut accélérer significativement la mise en conformité et sécuriser votre indexation.
❓ Questions frequentes
Le SSR est-il la seule solution pour éviter les échecs de rendu ?
Comment savoir si Google a échoué à rendre mes pages ?
Un échec de rendu impacte-t-il aussi le ranking des pages déjà indexées ?
Les frameworks JavaScript modernes résolvent-ils ce problème automatiquement ?
Googlebot utilise-t-il toujours Chrome récent pour le rendu JavaScript ?
🎥 De la même vidéo 9
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 30/05/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.