Declaration officielle
Autres déclarations de cette vidéo 9 ▾
- □ Pourquoi un échec de rendu JavaScript peut-il retarder votre indexation de plusieurs semaines ?
- □ Le JavaScript est-il vraiment indexé par Google ou faut-il encore s'en méfier ?
- □ Pourquoi le rendu côté client pose-t-il un problème structurel pour le crawl Google ?
- □ Le rendu côté serveur est-il vraiment plus fiable que le rendu client ?
- □ Faut-il abandonner le rendu côté client pour améliorer son référencement naturel ?
- □ Faut-il vraiment privilégier le code 410 au 404 pour signaler une page supprimée ?
- □ Est-ce que Google traite vraiment les codes 429, 503 et 500 de la même manière ?
- □ Les domaines Web3 (.eth) sont-ils crawlables par Google ?
- □ Pourquoi vos utilisateurs tapent-ils le nom de votre marque dans Google plutôt que votre URL ?
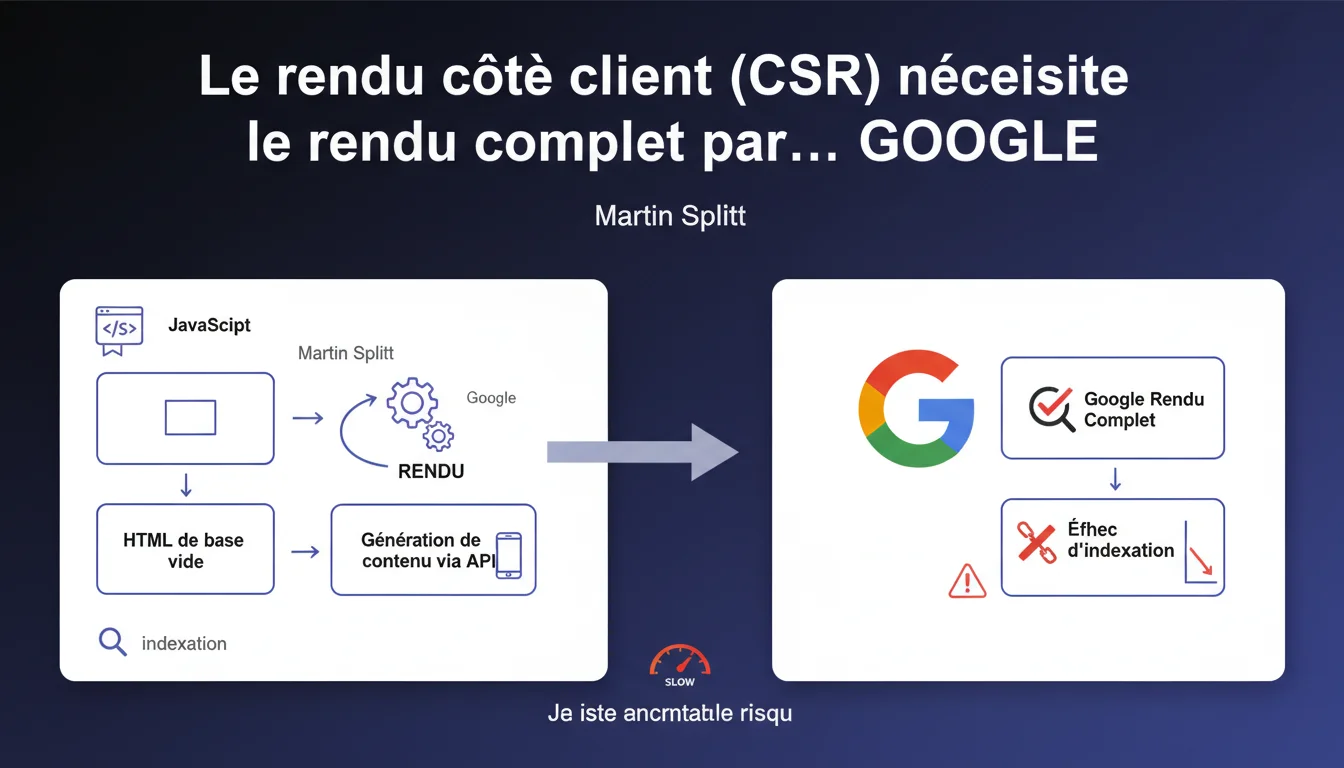
Google confirme que les pages en rendu côté client (CSR) nécessitent un rendu complet par Googlebot, sans filet de sécurité. Si le JavaScript échoue, aucun contenu HTML de secours n'existe, ce qui augmente drastiquement les risques d'échec d'indexation. Une architecture technique qui peut vous coûter cher en visibilité.
Ce qu'il faut comprendre
En quoi le CSR diffère-t-il vraiment des autres modes de rendu ?
Le rendu côté client (CSR) envoie au navigateur — et à Googlebot — un HTML quasi vide. Tout le contenu visible provient de JavaScript qui interroge des API pour récupérer les données, puis construit le DOM dynamiquement.
Contrairement au SSR (Server-Side Rendering) où le HTML arrive déjà complet, ou à l'hydratation où un squelette HTML minimal existe, le CSR laisse Google face à une page blanche. Le bot doit exécuter le JS, attendre les réponses API, puis assembler le contenu final.
Pourquoi Google insiste-t-il sur l'absence de « repli » possible ?
C'est le point crucial : avec du SSR ou du pre-rendering, si le JavaScript plante, Google peut quand même indexer le HTML statique présent dans la réponse serveur. Un filet de sécurité.
En CSR pur, ce filet n'existe pas. Si le rendu JavaScript échoue — timeout, erreur réseau, bug JS, ressource bloquée par robots.txt — Google ne voit rien. Zero contenu indexable. La page risque d'être considérée comme vide ou faiblement qualitative.
Quels sont les risques concrets d'échec d'indexation ?
Google a confirmé à plusieurs reprises que son système de rendu n'est pas infaillible. Plusieurs facteurs peuvent faire foirer le rendu :
- Timeout : si vos API mettent trop de temps à répondre, Googlebot peut abandonner avant d'obtenir le contenu final
- Erreurs JavaScript : un bug JS non détecté en dev peut bloquer l'ensemble du rendu côté bot
- Ressources bloquées : si un fichier JS critique est bloqué par robots.txt ou inaccessible, le rendu échoue complètement
- Budget crawl/rendu limité : Google ne peut pas rendre infiniment toutes vos pages CSR, surtout sur des sites massifs
- Latence réseau : les bots crawlent depuis des datacenters distribués, parfois avec des connexions moins optimales que vos tests locaux
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec ce qu'on observe sur le terrain ?
Absolument. Les sites full CSR — notamment ceux bâtis sur React/Vue/Angular sans SSR — rencontrent régulièrement des problèmes d'indexation inexpliqués. Des pages qui « disparaissent » de l'index, des contenus partiellement crawlés, des délais d'indexation anormalement longs.
On constate aussi que Google Search Console remonte souvent des erreurs « Exploré, actuellement non indexé » sur ces architectures. Le bot a bien visité la page, mais n'a pas réussi à extraire de contenu suffisant pour justifier l'indexation.
Quelles nuances faut-il apporter à cette affirmation ?
Martin Splitt ne dit pas que le CSR est impossible à indexer — seulement que c'est plus risqué. Google y arrive, mais avec une marge d'erreur bien supérieure aux autres architectures.
Il faut aussi distinguer CSR strict et CSR hybride. Certains frameworks génèrent un squelette HTML minimal avec métadonnées et structure de base, puis hydratent le reste en JS. Ce n'est pas du SSR, mais ce n'est pas du CSR pur non plus — et ça limite déjà les risques.
[A vérifier] Google ne donne jamais de chiffres précis sur le taux d'échec du rendu JavaScript. Impossible de savoir si on parle de 1 %, 5 % ou 15 % des pages CSR concernées. Cette opacité rend difficile l'évaluation objective du risque pour votre projet spécifique.
Dans quels cas le CSR reste-t-il une option viable ?
Sur des interfaces applicatives où le SEO n'est pas critique : dashboards SaaS, back-offices, outils métier. Là, le CSR apporte de la réactivité et simplifie le développement sans conséquence business.
Pour du contenu éditorial, des fiches produits, des landing pages — bref, tout ce qui doit ranker — le CSR pur est un pari risqué. Sauf si vous mettez en place un monitoring ultra-serré et des mécanismes de pre-rendering pour Googlebot.
Impact pratique et recommandations
Que faut-il faire concrètement si votre site est en CSR ?
D'abord, auditer votre indexation réelle. Utilisez Search Console pour identifier les pages « Exploré, actuellement non indexé » et comparez avec vos logs serveur. Si vous avez un écart significatif entre pages crawlées et pages indexées, c'est un signal d'alarme.
Ensuite, testez le rendu Googlebot via l'outil d'inspection d'URL dans GSC. Regardez la version « rendue » : si elle est vide ou incomplète, vous avez confirmation d'un problème de rendu JS.
Surveillez vos Core Web Vitals côté bot. Le LCP (Largest Contentful Paint) en CSR est souvent catastrophique parce que le contenu n'apparaît qu'après plusieurs secondes de JS + API. Google peut considérer la page trop lente et la déprioriser.
Quelles erreurs éviter absolument ?
Ne bloquez jamais vos fichiers JavaScript via robots.txt. C'est une erreur classique qui empêche Google de rendre vos pages. Vérifiez aussi que vos API ne bloquent pas le user-agent Googlebot.
Évitez les chaînes de dépendances JS trop longues. Si votre app.js charge un framework qui charge des modules qui appellent des APIs qui retournent du JSON qui génère du HTML… vous multipliez les points de défaillance.
N'ignorez pas les timeout côté serveur. Si vos APIs mettent 5 secondes à répondre en moyenne, Googlebot ne patientera pas. Optimisez la latence backend avant de vous inquiéter du frontend.
Comment migrer vers une architecture plus SEO-friendly ?
Si vous êtes sur un framework moderne (Next.js, Nuxt, SvelteKit), passez en SSR ou SSG (Static Site Generation) pour les pages SEO-critiques. Vous gardez l'UX réactive côté client, mais Google reçoit du HTML complet dès la requête initiale.
Pour les sites legacy en React/Vue pur, envisagez une solution de pre-rendering ciblée : générez statiquement les pages prioritaires (catégories, fiches produits phares) et laissez le CSR pour le reste. C'est un compromis pragmatique.
Si votre budget le permet, une refonte progressive vers du SSR est l'investissement le plus rentable à moyen terme. Vous supprimez le risque à la racine plutôt que de le contourner avec des patchs techniques.
- Auditer l'indexation actuelle via Search Console et logs serveur
- Tester le rendu Googlebot avec l'outil d'inspection d'URL
- Mesurer le LCP côté bot et optimiser les temps de réponse API
- Vérifier que les JS et APIs sont accessibles à Googlebot
- Migrer progressivement vers SSR/SSG pour les pages stratégiques
- Mettre en place un monitoring d'indexation automatisé (via API GSC)
- Documenter les dépendances JS pour limiter les chaînes de défaillance
❓ Questions frequentes
Le CSR est-il complètement à bannir pour le SEO ?
Le pre-rendering résout-il le problème du CSR pour Google ?
Comment savoir si mes pages CSR sont correctement indexées ?
Les Core Web Vitals sont-ils pénalisés en CSR ?
Next.js et Nuxt résolvent-ils automatiquement le problème ?
🎥 De la même vidéo 9
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 30/05/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.