Declaration officielle
Autres déclarations de cette vidéo 9 ▾
- □ Pourquoi le rendu côté client (CSR) met-il votre indexation Google en danger ?
- □ Pourquoi un échec de rendu JavaScript peut-il retarder votre indexation de plusieurs semaines ?
- □ Le JavaScript est-il vraiment indexé par Google ou faut-il encore s'en méfier ?
- □ Le rendu côté serveur est-il vraiment plus fiable que le rendu client ?
- □ Faut-il abandonner le rendu côté client pour améliorer son référencement naturel ?
- □ Faut-il vraiment privilégier le code 410 au 404 pour signaler une page supprimée ?
- □ Est-ce que Google traite vraiment les codes 429, 503 et 500 de la même manière ?
- □ Les domaines Web3 (.eth) sont-ils crawlables par Google ?
- □ Pourquoi vos utilisateurs tapent-ils le nom de votre marque dans Google plutôt que votre URL ?
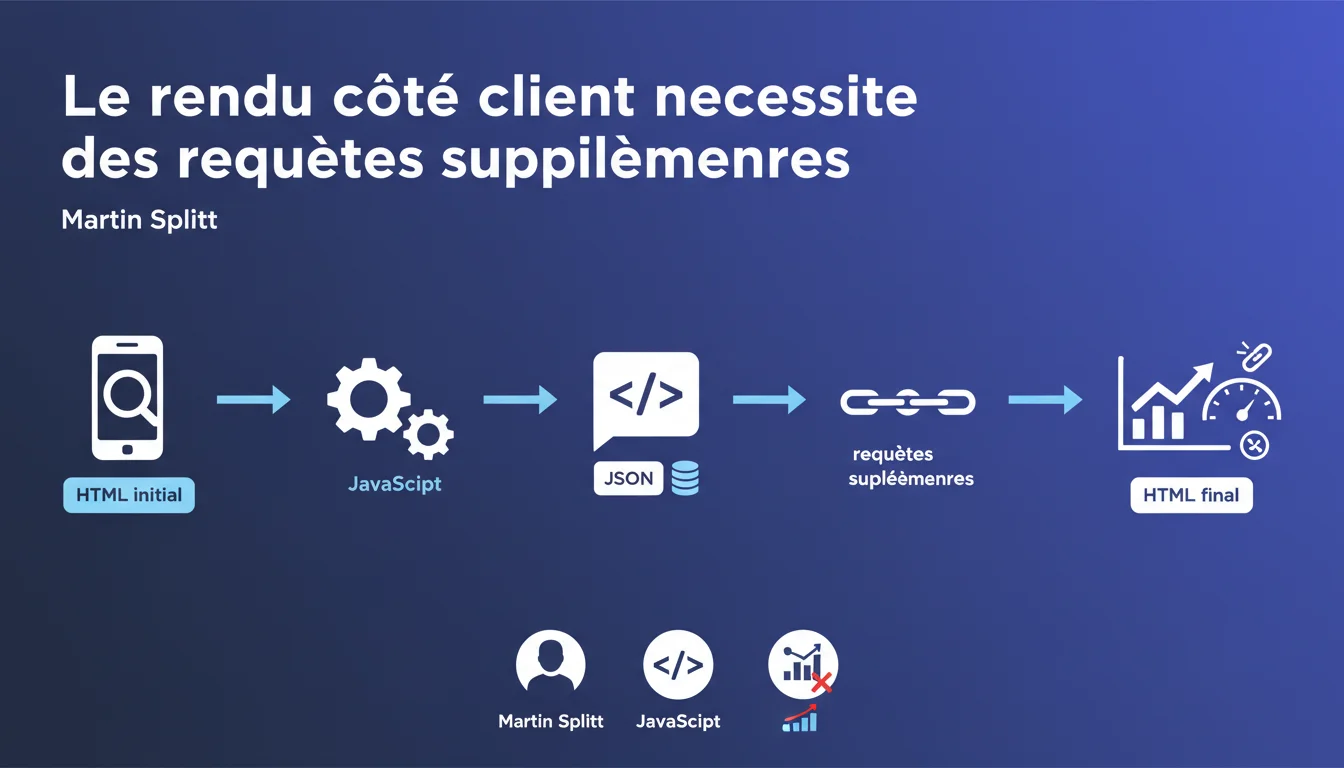
Le rendu côté client (CSR) multiplie les requêtes nécessaires pour afficher le contenu final : HTML initial, fichier JavaScript, puis appels API pour récupérer les données JSON avant génération du DOM. Chaque étape ajoute un point de défaillance potentiel et ralentit la découverte du contenu par Googlebot. Pour les sites critiques en SEO, cette complexité devient un handicap mesurable.
Ce qu'il faut comprendre
Que signifie concrètement cette cascade de requêtes ?
Le CSR impose un processus en trois temps : le navigateur (ou Googlebot) charge d'abord une coquille HTML vide, télécharge ensuite le bundle JavaScript, puis ce JS exécute des appels API pour récupérer le contenu réel stocké ailleurs. C'est seulement après ces trois étapes que le HTML final est généré dans le DOM.
Comparé au rendu serveur (SSR) où tout arrive d'un coup dans le premier HTML, on passe d'une requête à un minimum de trois. Et c'est un minimum — certains frameworks modernes peuvent déclencher des dizaines d'appels API imbriqués avant d'afficher une page complète.
Pourquoi Martin Splitt parle-t-il de « points de défaillance » ?
Chaque étape du processus peut échouer ou se dégrader. L'API peut renvoyer une erreur 500, le fichier JS peut être bloqué par un CDN défaillant, le timeout peut être atteint avant la fin du rendu. Googlebot n'attend pas indéfiniment.
Quand le bot visite une page SSR, soit le HTML est là, soit il ne l'est pas. Avec du CSR, tu multiplies les variables d'échec — et Google ne te dira pas toujours laquelle a planté. Le pire : certaines erreurs sont intermittentes, invisibles en développement mais réelles en production sous charge.
Quels sont les impacts mesurables sur le crawl ?
- Latence accrue : le temps nécessaire pour obtenir le contenu final peut exploser, surtout si les API sont lentes ou géographiquement éloignées du datacenter Google
- Budget crawl consommé : Googlebot doit allouer plus de ressources (CPU, mémoire, bande passante) pour une seule page CSR que pour une page statique
- Indexation partielle : si le JS plante ou timeout, Google indexe la coquille vide — et tu ne le sais parfois que des semaines après
- Difficulté de debug : identifier quelle requête a échoué dans la chaîne devient un cauchemar sans logs précis côté serveur
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui — et c'est même un euphémisme. Sur des sites e-commerce en React pur CSR, on observe régulièrement des taux d'indexation inférieurs à 60% sur les fiches produits chargées dynamiquement. Google indexe le squelette, parfois le titre récupéré en meta, mais rate les descriptions, prix, avis clients.
Ce que Martin Splitt ne dit pas : même quand ça « marche », le délai d'indexation peut exploser. Une page SSR fraîche apparaît souvent dans l'index sous 24-48h. Une page CSR avec trois couches d'appels API ? On voit des délais de 2-3 semaines, voire jamais pour les URLs découvertes en profondeur.
Dans quels cas cette complexité reste-t-elle acceptable ?
Pour des interfaces applicatives où le SEO n'est pas critique : dashboards privés, back-offices, zones membres post-login. Là, le CSR apporte une vraie valeur UX (navigation fluide, état persistant) sans coût SEO puisque ces pages ne doivent pas être crawlées.
Le problème, c'est quand des développeurs appliquent aveuglément du CSR sur des pages de contenu public parce que « c'est moderne ». Résultat : un blog corporate en Next.js mal configuré qui fait du CSR alors qu'un simple SSG (Static Site Generation) suffirait amplement.
Que dit Google entre les lignes ?
Cette déclaration est un aveu soft : oui, Googlebot sait théoriquement gérer le JavaScript, mais non, ce n'est pas gratuit. Chaque couche de complexité réduit la fiabilité et la rapidité du crawl. Google ne te pénalise pas directement pour du CSR — mais tu te pénalises toi-même.
Le non-dit : si ton concurrent fait du SSR et toi du CSR à contenu équivalent, il aura probablement un avantage d'indexation et de fraîcheur. Pas parce que Google le favorise, mais parce que son architecture facilite le travail du bot. [À vérifier] si cet avantage se traduit en ranking — les études publiques manquent.
Impact pratique et recommandations
Que faut-il auditer en priorité sur un site CSR existant ?
Commence par Search Console : regarde le taux de couverture, les erreurs d'indexation, et surtout compare le nombre d'URLs soumises vs indexées. Un écart >20% sur du contenu récent est un signal d'alarme. Utilise ensuite l'outil d'inspection d'URL pour voir ce que Googlebot récupère réellement.
Teste le rendu en conditions réelles : lance un crawl Screaming Frog en mode JavaScript activé, avec timeout à 10s (proche de ce que Googlebot accepte). Note les pages qui timeout ou renvoient un DOM incomplet. Ces pages sont probablement mal indexées.
Vérifie les logs serveur : identifie les appels API qui échouent (4xx, 5xx) ou qui dépassent systématiquement 2-3s de latence. Ce sont tes points de défaillance critiques. Si ton API de contenu plante 5% du temps, 5% de ton crawl Google sera raté.
Quelles migrations techniques réduisent ce risque ?
- Passer au SSR ou SSG pour les pages de contenu à forte valeur SEO (fiches produits, articles, catégories)
- Implémenter du pre-rendering spécifique pour les bots si une migration complète est impossible (solutions comme Prerender.io, mais attention aux risques de cloaking)
- Optimiser les API critiques : mise en cache agressive, CDN proche des datacenters Google, failover automatique
- Réduire la taille des bundles JS : code-splitting, lazy loading des composants non-critiques, suppression des dépendances inutiles
- Monitorer le rendu côté bot : logs Googlebot dédiés, alertes sur les timeouts, tracking du taux d'indexation par type de page
Comment prioriser ces actions avec des ressources limitées ?
Commence par les 20% de pages qui génèrent 80% du trafic SEO. Identifie-les via Analytics, puis vérifie leur qualité d'indexation. Si tes top landing pages sont en CSR et mal indexées, c'est la priorité absolue — même si ça implique un refactoring partiel.
Pour le reste du site, une approche progressive fonctionne : migre d'abord les templates à fort ROI (produits phares, contenus evergreen), laisse les pages secondaires en CSR tant que l'indexation tient. Mesure l'impact après chaque vague de migration.
❓ Questions frequentes
Le SSR résout-il tous les problèmes du CSR pour le SEO ?
Google pénalise-t-il directement les sites en CSR ?
Un site SPA (Single Page Application) peut-il bien se positionner en SEO ?
Combien de temps Googlebot attend-il avant de timeout sur une page CSR ?
Les appels API externes sont-ils plus risqués que les appels en interne pour le CSR ?
🎥 De la même vidéo 9
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 30/05/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.