Official statement
Other statements from this video 9 ▾
- □ Pourquoi le rendu côté client (CSR) met-il votre indexation Google en danger ?
- □ Pourquoi un échec de rendu JavaScript peut-il retarder votre indexation de plusieurs semaines ?
- □ Le JavaScript est-il vraiment indexé par Google ou faut-il encore s'en méfier ?
- □ Le rendu côté serveur est-il vraiment plus fiable que le rendu client ?
- □ Faut-il abandonner le rendu côté client pour améliorer son référencement naturel ?
- □ Faut-il vraiment privilégier le code 410 au 404 pour signaler une page supprimée ?
- □ Est-ce que Google traite vraiment les codes 429, 503 et 500 de la même manière ?
- □ Les domaines Web3 (.eth) sont-ils crawlables par Google ?
- □ Pourquoi vos utilisateurs tapent-ils le nom de votre marque dans Google plutôt que votre URL ?
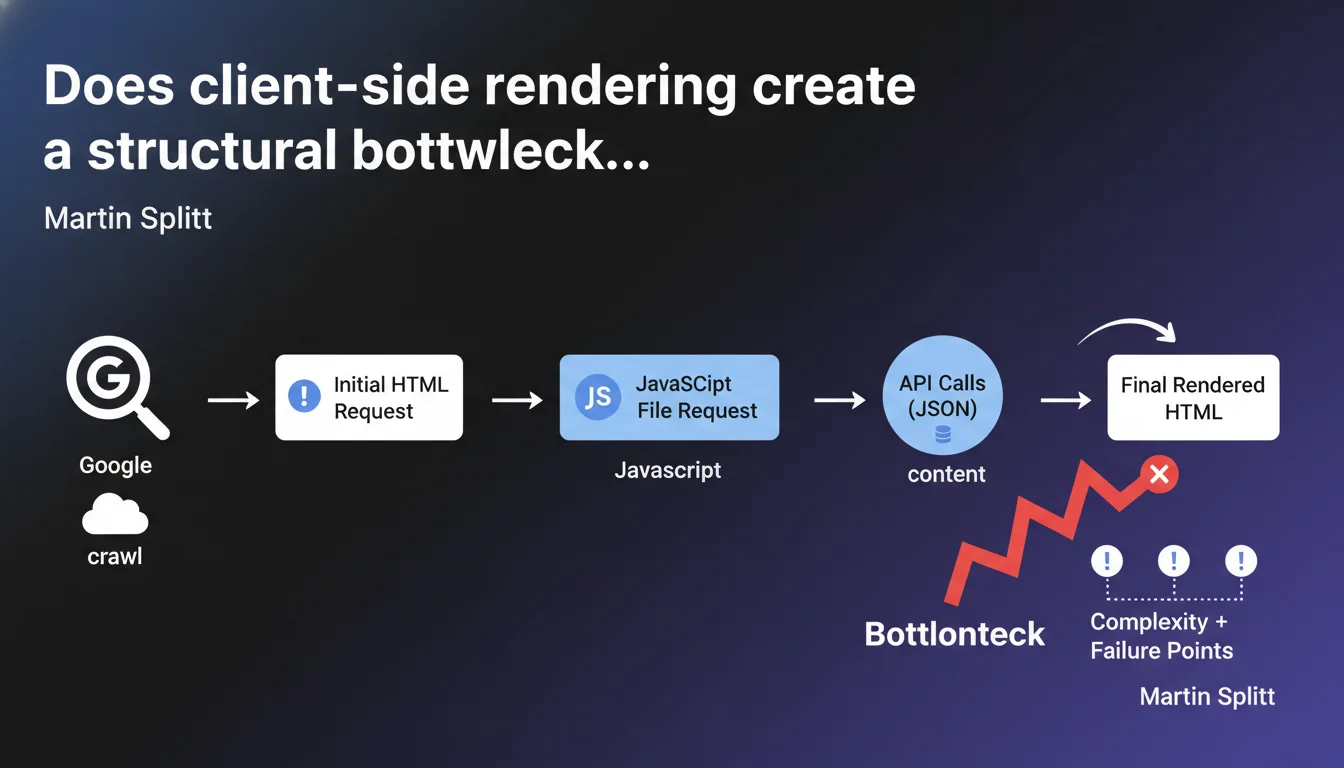
Client-side rendering (CSR) multiplies the requests needed to display final content: initial HTML, JavaScript file, then API calls to fetch JSON data before DOM generation. Each step adds a potential failure point and slows down content discovery by Googlebot. For SEO-critical websites, this complexity becomes a measurable disadvantage.
What you need to understand
What does this cascade of requests actually mean in practice?
CSR imposes a three-step process: the browser (or Googlebot) first loads an empty HTML shell, then downloads the JavaScript bundle, then this JS executes API calls to fetch the actual content stored elsewhere. Only after these three steps is the final HTML generated in the DOM.
Compared to server-side rendering (SSR) where everything arrives at once in the initial HTML, you go from one request to a minimum of three. And that's a minimum — some modern frameworks can trigger dozens of nested API calls before displaying a complete page.
Why does Martin Splitt talk about "failure points"?
Each step of the process can fail or degrade. The API can return a 500 error, the JS file can be blocked by a failing CDN, the timeout can be reached before rendering completes. Googlebot doesn't wait indefinitely.
When the bot visits an SSR page, either the HTML is there or it isn't. With CSR, you multiply failure variables — and Google won't always tell you which one broke. Worse: some errors are intermittent, invisible in development but real in production under load.
What are the measurable impacts on crawling?
- Increased latency: the time needed to obtain final content can explode, especially if APIs are slow or geographically far from Google's datacenter
- Crawl budget consumed: Googlebot must allocate more resources (CPU, memory, bandwidth) for a single CSR page than for a static page
- Partial indexation: if JS crashes or times out, Google indexes the empty shell — and you sometimes don't find out for weeks
- Debugging difficulty: identifying which request failed in the chain becomes a nightmare without precise server-side logs
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes — and it's actually understating it. On pure React CSR e-commerce sites, we regularly observe indexation rates below 60% on dynamically loaded product pages. Google indexes the skeleton, sometimes the title fetched from meta, but misses descriptions, prices, customer reviews.
What Martin Splitt doesn't say: even when it "works", the indexation delay can explode. A fresh SSR page often appears in the index within 24-48 hours. A CSR page with three layers of API calls? We see delays of 2-3 weeks, or never for URLs discovered deeper in the site structure.
In which cases does this complexity remain acceptable?
For application interfaces where SEO isn't critical: private dashboards, back-offices, post-login member zones. There, CSR delivers real UX value (smooth navigation, persistent state) with no SEO cost since these pages shouldn't be crawled.
The problem arises when developers blindly apply CSR to public content pages because "it's modern". Result: a corporate blog in Next.js poorly configured to do CSR when a simple SSG (Static Site Generation) would be more than enough.
What is Google saying between the lines?
This statement is a soft admission: yes, Googlebot theoretically knows how to handle JavaScript, but no, it's not free. Each layer of complexity reduces crawl reliability and speed. Google won't directly penalize you for CSR — but you penalize yourself.
The unspoken part: if your competitor does SSR and you do CSR with equivalent content, they'll probably have a indexation and freshness advantage. Not because Google favors them, but because their architecture makes the bot's job easier. [To verify] whether this advantage translates to ranking — published studies are lacking.
Practical impact and recommendations
What should you audit first on an existing CSR site?
Start with Search Console: check coverage rate, indexation errors, and especially compare the number of URLs submitted vs indexed. A gap >20% on recent content is a red flag. Then use the URL inspection tool to see what Googlebot actually retrieves.
Test rendering in real conditions: run a Screaming Frog crawl with JavaScript enabled, timeout set to 10 seconds (close to what Googlebot accepts). Note pages that timeout or return incomplete DOM. These pages are probably poorly indexed.
Check server logs: identify API calls that fail (4xx, 5xx) or consistently exceed 2-3 seconds of latency. These are your critical failure points. If your content API crashes 5% of the time, 5% of your Google crawl will be lost.
Which technical migrations reduce this risk?
- Switch to SSR or SSG for high-value SEO content pages (product sheets, articles, categories)
- Implement bot-specific pre-rendering if complete migration is impossible (solutions like Prerender.io, but watch for cloaking risks)
- Optimize critical APIs: aggressive caching, CDN close to Google datacenters, automatic failover
- Reduce JS bundle size: code-splitting, lazy loading of non-critical components, remove unnecessary dependencies
- Monitor bot rendering: dedicated Googlebot logs, timeout alerts, track indexation rate by page type
How do you prioritize these actions with limited resources?
Start with the 20% of pages generating 80% of SEO traffic. Identify them via Analytics, then verify their indexation quality. If your top landing pages are in CSR and poorly indexed, that's the absolute priority — even if it requires partial refactoring.
For the rest of the site, a progressive approach works: migrate template pages with highest ROI first (flagship products, evergreen content), leave secondary pages in CSR as long as indexation holds. Measure impact after each migration wave.
❓ Frequently Asked Questions
Le SSR résout-il tous les problèmes du CSR pour le SEO ?
Google pénalise-t-il directement les sites en CSR ?
Un site SPA (Single Page Application) peut-il bien se positionner en SEO ?
Combien de temps Googlebot attend-il avant de timeout sur une page CSR ?
Les appels API externes sont-ils plus risqués que les appels en interne pour le CSR ?
🎥 From the same video 9
Other SEO insights extracted from this same Google Search Central video · published on 30/05/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.